原文链接:http://tecdat.cn/?p=25044
原文出处:拓端数据部落公众号
最近我们被客户要求撰写关于结构方程模型的研究报告,包括一些图形和统计输出。
1 简介
在本文,我们将考虑观察/显示所有变量的模型,以及具有潜在变量的模型。第一种有时称为“路径分析”,而后者有时称为“测量模型”。
2 进行简单的多元回归
SEM 在很大程度上是回归的多元扩展,我们可以在其中一次检查许多预测变量和结果。SEM 还提供了检查潜在结构(即未观察到某些变量的地方)的创新。更具体地说,“结构方程”的概念是指我们有不止一个方程表示协方差结构模型,其中我们(通常)有多个标准变量和多个预测变量。
让我们从简单的演示开始,即 SEM 中的路径模型可以概括简单的单预测变量-单结果回归。我们将检查人口普查中的房价数据,以回顾相关和回归中的重要概念。这是一个很好的回归数据集,因为有许多相互依赖的变量:犯罪,污染物,财产的年龄,等等。
这是上面的单预测回归,作为路径模型运行 :
#示例数据集,包括按人口普查区划分的房屋价格
Bsnml <- otnou %>% dplyr::select(
cmv, #住宅的中位数价值,以千计
crm, #城镇人均犯罪率
nx, #一氧化氮浓度
lsa, #地位较低的人的比例
rd #靠近放射状的高速公路
) %>% mutate
summary
为了比较,输出 lm()
summary(lm
回归系数是相同的(好!)。有一点需要注意的是,我们在输出中没有截距。这突出了一个重要的区别,基本的SEM经常关注数据的协方差结构。我们也可以包括均值,但通常只有当它与我们的科学问题有关时才会包括。例如,男性和女性在抑郁症潜在因素的平均水平上是否有差异?
2.1 平均结构
在这种情况下,我们可以要求在模型中包含平均值(截距) mean=TRUE:
summary(lvt)
2.2 模型参数详情
"参数 "表提供了模型中哪些参数是必须被估计,以及用户在模型语法中要求哪些参数的重要摘要。\
Table(mv)
在这里,'user' 指的是我们在语法中明确请求的参数,'free' 列的非零值表示模型自由估计的参数。
请注意,我们也可以得到标准化的估计值 。这是 SEM 中更复杂的主题,因为我们可以仅针对潜在变量(std.lv)或观察变量和潜在变量(std.all)进行标准化。后者通常是 SEM 论文中作为标准化估计报告的内容。
2.3 标准化估计
stdln(v, type)
3 住房数据的路径分析
让我们看一些更有趣的东西。如果我们认为一氧化氮 ( nox) 水平也可以预测房价和犯罪率,那会怎样?我们可以将其添加为标准多元回归中的预测变量。
此外,我们假设房屋靠近大型高速公路(rad)预测一氧化氮的浓度,从而预测较低的房价?
模型语法可以指定为:
sem(ln2, data=toSll)模型看起来像这样
Paths
这是文本输出:
summary
需要注意的几点:
- 请注意警告:“一些观察到的差异(至少)是其他差异的 1000 倍。”
- 我们的假设似乎都得到了支持。
- 模型卡方非常显着,表明全局模型拟合不佳。
3.1 调整
当模型中变量的方差显着不同(数量级)时,参数估计可能会遇到困难。鉴于上述警告,让我们来看看。
Table(lv2)
看起来nox的比例要比其他预测因素小得多,可能是因为它的单位是千万分之一!我们可以通过乘以常数来重新调整变量的比例。在这种情况下,我们可以通过乘以一个常数来重新划分变量的尺度。这对模型的拟合或解释没有影响--我们只需要回忆一下新单位代表什么。另外,如果重要的话,你可以随时从参数估计中除掉常数来恢复原来的单位。\
Bonl <- BoSal %>% mutate
summary(lv2)
3.2 模型拟合指数
您可以在模型摘要输出中使用更详细的全局拟合指数。
summary(fit.me=TRUE)
您还可以使用以下方法获取适合的度量(包括其他统计信息)


这些看起来很差:CFI < .95(甚至远低于 0.9),而 RMSEA 远高于我们认为“还可以”的 0.08 水平。
3.3 模型诊断
这表明需要更详细地检查拟合。首先,我们可以查看模型隐含和观察到的协方差矩阵之间的不匹配。
从概念上讲,结构方程建模 (SEM) 的目标是测试变量间协方差的理论动机模型是否提供了数据的良好近似。
更具体地说,我们试图测试一个解析模型(由测量和/或结构成分组成)对观察到的协方差矩阵的再现程度。从形式上看,我们正在寻求建立一个模型,其模型隐含的协方差矩阵接近于样本(观测)协方差矩阵。
SXX≈Σ (θ ^)
我们可以从中获得这些信息, 进一步诊断模型不匹配。
首先,模型隐含的协方差矩阵:
fitted
我们也许可以用相关(标准化)单位更容易地解释这一点。也就是说,变量之间的模型隐含相关性是什么?可以访问许多模型详细信息,包括:

这与观察到的相关性相比如何?

特别是,获得双变量关联的不匹配。在这里,我们要求相关单位中的残差,这比处理未标准化的协方差更直观。请注意,这是上面观察到的模型隐含矩阵的减法。大的正值表明模型低估了相关性;大的负值表明相关性的过度预测。通常值 |r>.1|值得仔细考虑。

因此,该模型显着低估了 nox 和 crim之间的 关联 。
我们也可以将问题可视化:
plot_matix
3.4 修改指数
让我们看一下修改索引,看看我们是否可以通过释放一个或多个路径来修复不匹配,特别是nox 和 log_crim之间的 关系 。

在这里,我们看到如果我们允许 log_crim 预测 ,模型拟合会大大提高nox。这是否具有理论上的意义是另一回事(而且可能更重要)。出于演示目的,让我们接受需要自由估计这条路径。
#我们可以使用添加参数来添加一个路径,同时保持所有其他模型元素不变
ma3 <- update
summary
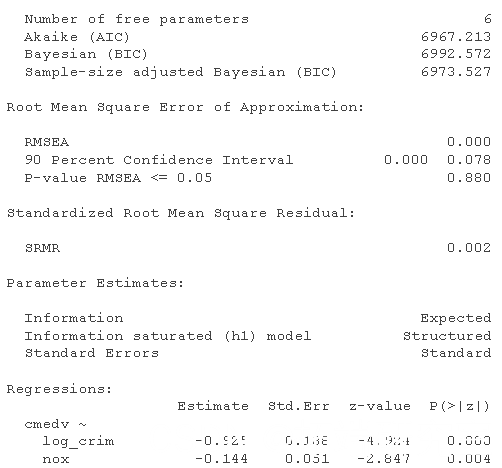

这在拟合方面看起来好多了。 犯罪与我们之前错过的氮氧化物水平之间存在强烈的正相关关系。从概念上讲,这表明犯罪与房价之间的关系部分是由犯罪对污染物水平的影响所调节的。相比之下,靠近高速公路对房价的影响似乎完全由污染物水平调节(正如这条路径没有大的修正指数所示)。
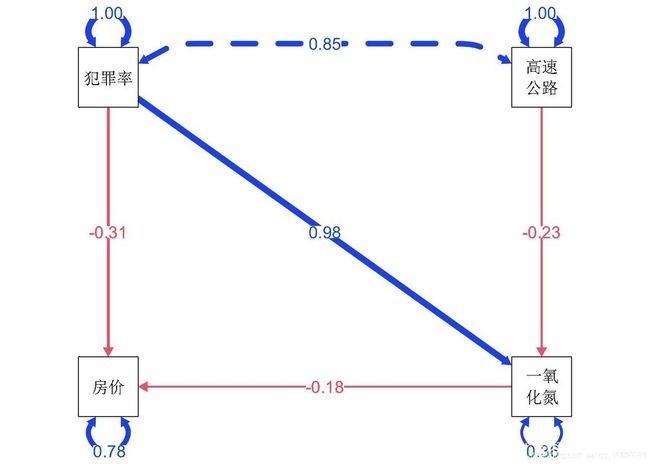
4 检验调解
如果支持上述模型并且我们对测试中介特别感兴趣,我们通常希望 1)专门检验间接效应,以及 2)使用一种方法对提供可信 p值的中介效应进行显着性检验。正如前段时间所指出的(例如,MacKinnon 等人,2007 年),在 SEM 框架中对中介的适当检验是基于 构成中介的成分路径的乘积。 在这里,我们在两个中介链中只有两条路径:
radlog_crim→nox→cmedv→nox→cmedvrad→nox→cmedvlog_crim→nox→cmedv
为了具体测试这些,我们需要在 模型中定义新参数,这些参数是各个路径的产物。这可以使用 =: 运算符('定义为')来完成。请注意,这确实会改变模型中自由参数的数量,因为这些只是现有参数的乘积。为了看哪个估计要相乘,我们必须通过将变量预乘以任意标签来使用“参数标签”。在这里,我将“a1”和“a2”用于 X -> M 路径,将“b1”用于 M -> Y 路径。
i_1 := a1*b1
i_2 := a2*b1
'
summary(mv4)

这看起来很有希望,但正如我上面提到的,这种用于测试中介的“delta 方法”众所周知是有问题的,因为间接路径乘积项的抽样分布不正常。Bootstrapping 是解决这种问题的一种常见解决方法,它不会对感兴趣系数的分布(即两个中介路径的采样分布)做出强有力的假设。我们可以使用参数来实现这一点 se = "bootstrap"。默认情况下,这将使用 1000 个非参数引导样本重新估计参数估计的标准误差。您可以使用bootstrap 参数更改引导样本的数量
summary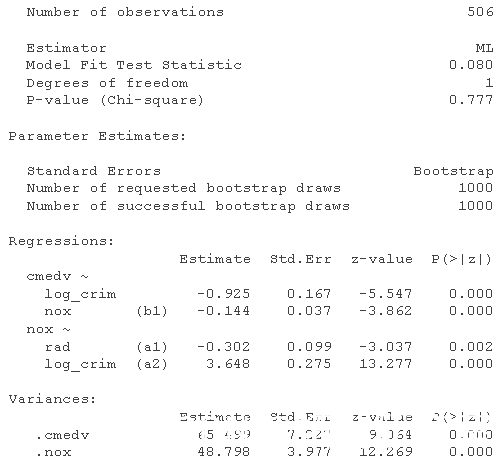

正如我们所怀疑的,这两种间接途径都很重要,表明了调节的证据。
5 带有潜在变量的 SEM
当我们对测试有潜变量的模型感兴趣时,怎么办?通常,这将是一个 "反映性潜变量 "模型,我们认为一个假定的潜变量是由几个(通常是3个以上)显性指标来衡量的。这样的变量通常被称为 "因子 "或 "潜在特质"。在SEM世界中,确认性因子分析是最常见的反映性潜变量模型。
这样的模型中使用=\~操作符('测量的')来指定。
让我们以 衡量智力为例,其中有 9 个项目可以衡量智力的不同方面:视觉、文本和速度。观察到的变量是 x1-x9。
这是一个“经典”数据集,用于许多关于结构方程建模 (SEM) 的论文和书籍,包括一些商业 SEM 软件包的手册。数据包括来自两所不同学校的七年级和八年级儿童的心理能力测试成绩。在我们的数据集版本中,仅包含原始 26 个测试中的 9 个。通常针对这 9 个变量提出的 CFA 模型由三个潜在变量(或因子)组成,每个潜在变量具有三个指标:
- 由 3 个变量测量的 视觉 因子
x1:x2和x3 - 由 3 个变量测量的 文本 因子
x4:x5和x6 - 由 3 个变量测量的 速度 因子
x7:x8和x9

一个 3 因素 CFA 示例
5.1 指定因子模型
指定此模型的相应 语法如下:
visual =~ x1 + x2 + x3
textual =~ x4 + x5 + x6
speed =~ x7 + x8 + x9在此示例中,模型语法仅包含三个“潜在变量定义”。
5.2 典型 CFA 输出
默认情况下,第一个指标具有 1 的固定负载以缩放基础因子(“单位负载标识”)。让我们来看看:
summary



5.3 CFA 的修正指数
modification
修正指数表明 x9 可能会加载 visual 因子,或者 x7 可能 x9 具有唯一的残差相关性。这又是一个理论上的问题,但我们可以测试修改后的模型以进行演示。我们使用 ~~ 运算符来指定模型中的(残差)方差或协方差项。
summary(fit2, fit.meas)
仍然不是很好。我们可以重新检查修改指数
modificatio
现在是时候咨询你关于潜在结构应该是什么的预测或理论了。这是一个模型构建和模型比较问题,很大程度上超出了本教程的范围。然而,我们至少可以测试这些模型之间的全局拟合差异。这些是嵌套模型(因为 x7 ~~ x9 在更简单的模型中残差协方差为 0),这允许我们使用似然比检验(也称为模型卡方差):
anova
该 anova 函数将使用 LRT 方法测试整体拟合差异。LRT 的自由度是自由参数数量的差异(此处为 1)。
5.4 详细看模型
我们可以查看自由参数在矩阵规范中的位置。自由参数被编号(按顺序),零表示可能的参数,固定为零(即不估计)。\
inspect

我们还可以看到矩阵形式的参数估计:
inspect( "est")

5.5 结构模型呢?
上面的 CFA 只包含一个测量模型——一个具有因子之间相关性的三因子模型。如果我们还想看看学校的年级在多大程度上可以预测智力因素(视觉、文本、速度)的水平,该怎么办?
summary( fit.measures=TRUE)
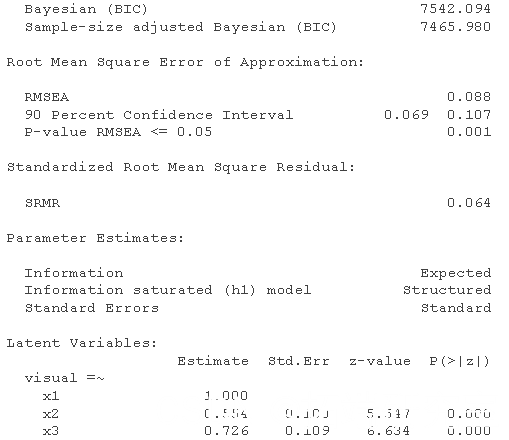
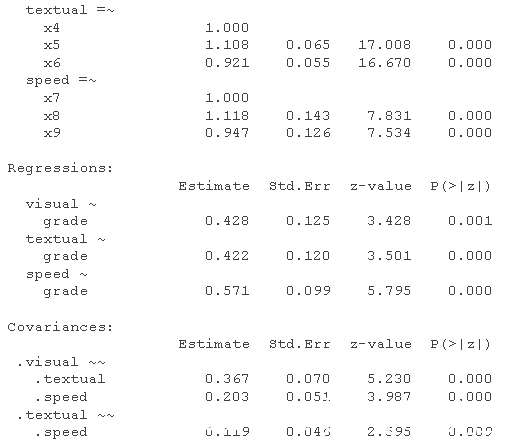

semPath
正如人们所预料的那样,高年级的孩子在潜在智力因素上得分更高。
最后,如果我们想在结构模型中使用一般与特定(残差)方差怎么办?为了让它们在相同的参数矩阵中适当地发挥作用,我们为感兴趣的项目残差创建了一个单指标潜在变量。
x1d =~ 1*x1 #定义干扰因子,将1.0加载到指标上(如RAM的符号)。
x1 ~~ 0*x1 #指标的零残差(所有加载到干扰因素上)。
#根据标准模型,干扰因素与因子不相关
x1d ~~ 0*视觉
x1d ~~ 0*文本
x1d ~~ 0*速度
#我们现在可以看看X1的具体方差和视觉因素是否能唯一地预测人的年龄
summary(fitne)

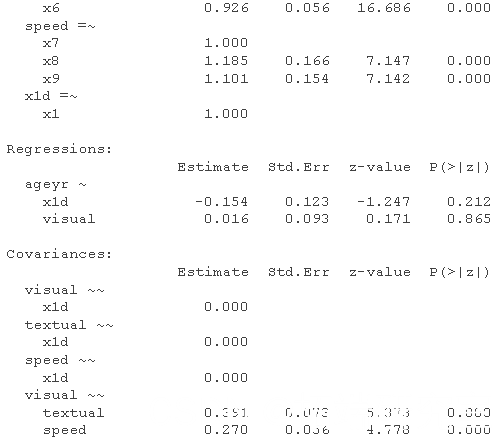

这里没有骰子,但你明白了。
6 分类数据
支持使用阈值结构来正式处理内生的分类数据。这源于这样的观点:一个项目的基本分布是连续的(高斯),但我们的离散化(如二元或多态)在特定的点上降低了这个维度。\

我们有4个级别的变量(1、2、3、4),但只有三个阈值--每个阈值指定两个相邻级别(锚)之间的边界。如果我们有动力来说明这个结构,这些阈值可以被指定为模型中的自由参数。这实质上是在估计ττ参数沿着连续体的落点;它们不需要均匀分布
如果我们对一个项目有5个以上的锚,我们也许可以把它当作连续的,而不会出现重大的错误。请注意,这就是我们在最初的CFA中所做的事情--我们将x1-x9视为正态/连续分布。事实证明,它们是(即不是高度离散的)。\
hist(Holz$x1)
但是,如果我们有具有 2、3 或 4 个值的数据,将变量视为连续变量通常是不合适的,并且可能导致有偏差、不准确的结果。
通常,具有阈值结构的模型是使用“加权最小二乘”(WLS)估计器而不是最大似然(ML;SEM 中的典型估计器)估计的。均值和协方差调整的 WLS(又名“WLSMV”)通常是可行的方法,因为它可以比典型的 WLS 更好地处理多元分布的非正态性。
6.1 CFA分类数据演示
这是一个快速演示——如果我们的每个智力测试项目只有三分法怎么办?
hist
我们用有序参数告诉R哪些项目是有序分类的。
summary(fiat)




请注意,我们现在对每个项目都有阈值估计,其中较高的数值表示对一个类别和下一个类别之间的边界有较高的估计,而这个潜在的连续体据说是该项目的基础。
7 估计
最后, 可以用许多不同的算法来估计模型中的参数。“ML”是连续数据的默认值,“WLS”是(部分)分类数据的默认值。
这些估计器的'稳健'通常会在整个模型的卡方检验和标准误差的层面上对非正态性(以及潜在的其他东西,如聚类)进行稳健处理,因此,显著性检验。让你的统计数据对非正态性具有鲁棒性通常是一件好事......因此,许多人将使用 "MLR "作为他们对连续数据的首选,而 "WLSMV "则用于分类数据。
可以使用 estimator 参数指定它。
summary(filr, fit.measures=TRUE)



我们现在有一列“稳健”的全局拟合指数,并注意标准误差是使用 Huber-White 估计器估计的(对非正态性和聚类稳健)。
8 缺失数据
默认情况下, 通常会删除缺少任何变量的样本。但是您可能会丢失大量数据,并且因为它可能会给数据带来偏差。虽然远远超出了本教程,但通常最好在数据随机缺失的假设下使用所谓的全信息最大似然 (FIML),即给定变量的缺失可能与其他变量相关,但是而不是变量本身。使用 FIML,估计尝试根据具有可用数据的案例来估计所有参数。
以下是默认情况下发生的情况:




注意输出:

结果不理想。
好的,下面是FIML
summary(fiiml, fit.measures=TRUE)



这更让人放心:

同样,关于缺失数据的理论和正式方法超出了本教程的范围,但我希望这能让大家了解到如何在sem中处理缺失问题。

最受欢迎的见解
2.面板平滑转移回归(PSTR)分析案例实现分析案例实现")
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
6.r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现