爬虫篇——今天也是没有闲着。学习笔记
待学习——正则表达式(变简单)——re
——多线程(同时)——threading
其实爬虫对于我现在初学的理解就是:
先请求,然后获取,然后提前。
1.爬虫1
2.爬虫2
3.爬虫3
4.爬虫4
5.爬虫5
6.爬虫6
1.爬虫1:先来代码::代码部分
import requests #导入库
head = {"User-Agent":"Mozilla/5.0(Windows NT 10.0; Win64; x64)"}#加个“头”,模仿浏览器访问
response = requests.get("http://books.toscrape.com/",headers= head)#访问的地址,和加上了“头”
if response.ok: #如果访问成功,就输出 ,没有就on
print(response.text)
else:
print("on")head = {"User-Agent":"Mozilla/5.0(Windows NT 10.0; Win64; x64)"}#加个“头”,模仿浏览器
response = requests.get("http://books.toscrape.com/",headers= head)
#访问的地址,和加上了“头”——————就是通过代码给浏览器发生请求
因为有的网站他不想代码访问,不想让你爬。想从正常的浏览器访问。这个就是为啥要加个“头”了。
2.爬虫2——豆瓣的访问
import requests
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0"
} #“头”
response = requests.get("https://movie.douban.com/top250",headers = headers)
if response.ok:
print(response.text)
else:
print("on")这个“头”的获取——
随便打开一个网站。
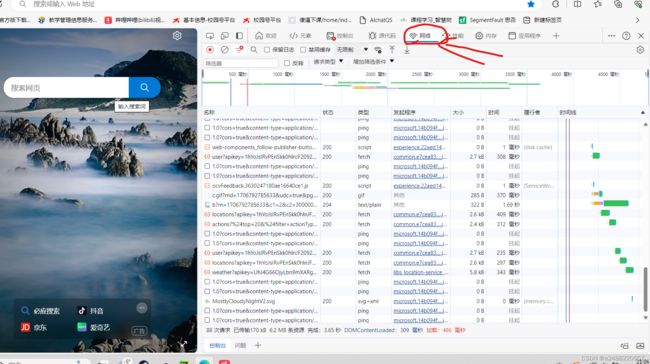
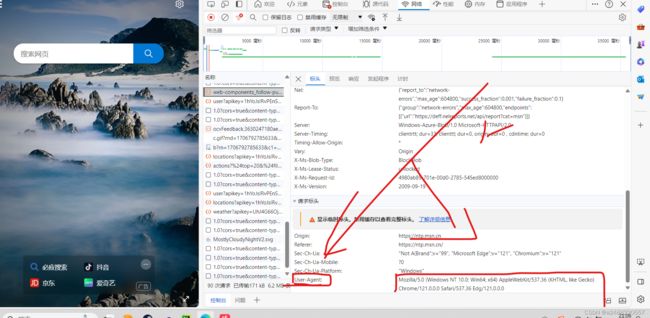 随便点一个进去找到“User-Agent:”然后把后面的复制给“头”就可以了。注意书写格式:
随便点一个进去找到“User-Agent:”然后把后面的复制给“头”就可以了。注意书写格式:
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0"
如果访问成功就会返回这个网站的信息。
3.爬虫3——这个是制作一个网站
这是个一个网站
一级标题
一级标题
一级标题
一级标题
一级12标题
一级标题
这还一个
文本
 百度
百度
- 我是第一项
- 我是第一项
- 我是第一项
- 我是第一项
头部1
头部2
头部3
#行
头部1
头部2
头部3
#行
#头部
111
222
333
#行
111
222
333
#行
111
222
333
#行
#主体
一个网站以一个
————就是题目![]()
————主体部分
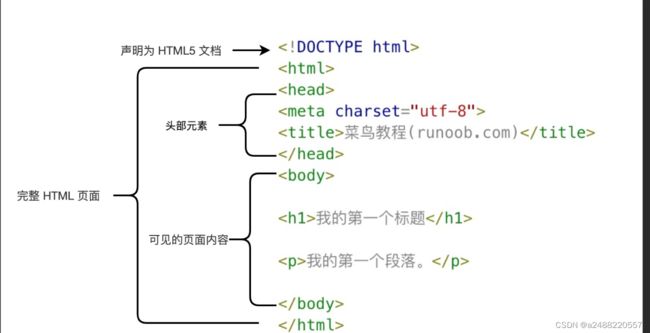
里面代码的:
从上往下看
1. ——很重要编码模式“UTF-8”我相信不陌生
2.一级标题
一级标题
3.就是我我这个部分的意思——这个就是我这个部分为红色
一级标题
一级标题
4.就是我选中的部分的颜色是什么
一级12标题
一级标题
5.这个就是文本(正文)
这个就是换行(你会发现在
里的换行没有用)
这还一个
文本
6.这个是加入图片,不过要先建立图床——啊这个还不会。
百度
8.
这个是ol为有序排列(前面有数字)
- 这个无序排列
- 我是第一项
- 我是第一项
- 我是第一项
- 我是第一项
9.就是表格
#行
#头部
#行
#主体
这个是形式,"border"就是边框的大小
——头部
——主体
——就几行就有几个
——内容
头部1
头部2
头部3
#行
头部1
头部2
头部3
#行
#头部
111
222
333
#行
111
222
333
#行
111
222
333
#行
#主体
好家伙爬虫3完了
图片还要图床所以显示不成功
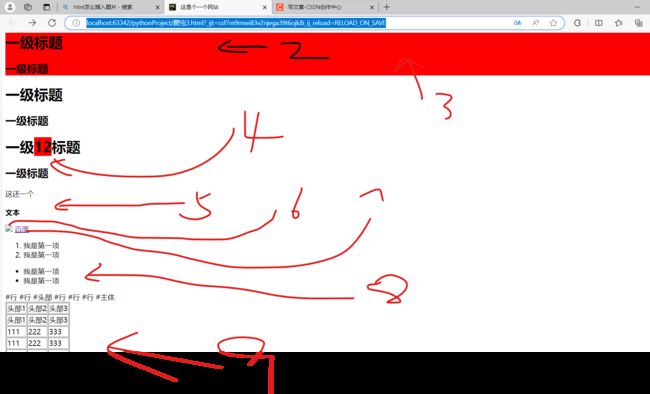
4.爬虫4——在练习的网站上获取价格
from bs4 import BeautifulSoup
import requests
content = requests.get("http://books.toscrape.com/").text
soup = BeautifulSoup(content,"html.parser")
all_prices = soup.findAll("p",attrs={ "class": "price_color"})
for price in all_prices:
print(price.string)#会把标签包围的文字,返回给我们
我们先打开这个网站:

我们的目的是提前价格,就要看价格的格式,和其他的特殊之处
£51.77
£53.74
元素表示文本的一个段落。
可以看出都在 中的“
1.soup = BeautifulSoup(content,"html.parser")——将这个网站的信息给Bea...这个库函数中,“html.parser”是解释器形式 中的类中的"price_color"
2.all_prices = soup.findAll("p",attrs={ "class": "price_color"})——查看
3.print(price.string)#会把标签包围的文字,返回给我们
![]()
本来是这个
然后加上那个就是
4.还可以加上切片
print(price.string[2:])#会把标签包围的文字,返回给我们

结束!!!!!
5.爬虫5——这个是提前那个书网站的书名
from bs4 import BeautifulSoup
import requests
content = requests.get("http://books.toscrape.com/").text
soup = BeautifulSoup(content,"html.parser")
all_tittle = soup.findAll("h3")
for tittle in all_tittle:
all_links = tittle.findAll("a")
for link in all_links:
print(link.string)这个是那个网站上书名的截屏:

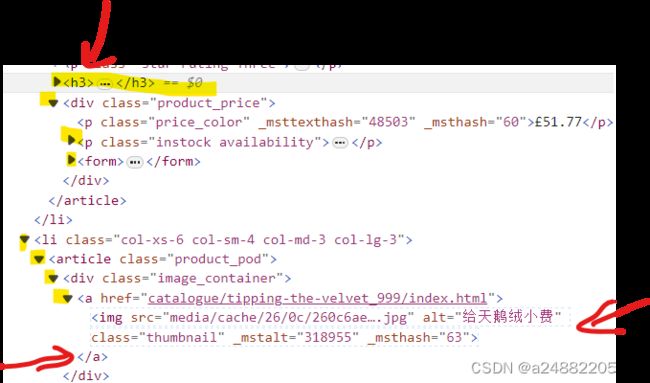
在发现在
中:
所以
all_tittle = soup.findAll("h3")——所有的书名
for tittle in all_tittle:
all_links = tittle.findAll("a")———所有书名的"a"
for link in all_links:
print(link.string)——所有“a”的文字

结束!!!!!
6.爬虫6——这个是提取豆瓣250的榜单
import requests
from bs4 import BeautifulSoup
num=1
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0"
}
for start_num in range(0,250,25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}",headers = headers)
if response.ok:
html = response.text
soup = BeautifulSoup(html,"html.parser")#"html.parser"这个是html的解析器
all_titles = soup.findAll("span",attrs = {"class":"title"})
for title in all_titles:
title_string=title.string
if "/" not in title_string:
print(f"{num}.{title_string}")
num+=1
else:
print("on")先打开网站

你会发现就是有规律,这就用到一个变量为0,25,50,75,100,125...225,用for循环遍历一下不就成了: for start_num in range(0,250,25):

你看这个这里特殊,就直接找他就行了 加上{"class":"title"}这个类
得到的就是要得到的电影名
你会发现
还有别名,然后每个别名和正常的名字不在一行
用if判断一下 得的电影名
OKOK到这里也就结束,这个是在b站上的课程。