ElasticSearch快速开始
目录
全文检索
全文检索的原理
什么是倒排索引
ElasticSearch介绍
ElasticSearch应用场景
ElasticSearch下载安装(windows)
客户端Kibana安装
Elasticsearch安装分词插件
ElasticSearch快速开始
ElasticSearch索引操作
创建索引
查询索引
删除索引
设置Settings
设置文档映射Mapping
动态映射
静态映射
使用ReIndex重建索引
ElasticSearch文档操作
全文检索
全文检索是一种通过对文本内容进行全面索引和搜索的技术。它可以快速地在大量文本数据中查找包含特定关键词或短语的文档,并返回相关的搜索结果。全文检索广泛应用于各种信息管理系统和应用中,如搜索引擎、文档管理系统、电子邮件客户端、新闻聚合网站等。它可以帮助用户快速定位所需信息,提高检索效率和准确性。
查询:有明确的搜索条件边界。比如,年龄 15~25 岁,颜色 = 红色,价格 < 3000,这里的 15、25、红色、3000 都是条件边界。即有明确的范围界定。
检索:即全文检索,无搜索条件边界,召回结果取决于相关性,其相关性计算无明确边界性条件,如同义词、谐音、别名、错别字、混淆词、网络热梗等均可成为其相关性判断依据。
全文检索的原理
在全文检索中,首先需要对文本数据进行处理,包括分词、去除停用词等。然后,对处理后的文本数据建立索引,索引会记录每个单词在文档中的位置信息以及其他相关的元数据,如词频、权重等。这个过程通常使用倒排索引(inverted index)来实现,倒排索引将单词映射到包含该单词的文档列表中,以便快速定位相关文档。
当用户发起搜索请求时,搜索引擎会根据用户提供的关键词或短语,在建立好的索引中查找匹配的文档。搜索引擎会根据索引中的信息计算文档的相关性,并按照相关性排序返回搜索结果。用户可以通过不同的搜索策略和过滤条件来精确控制搜索结果的质量和范围。
什么是倒排索引
正排索引(Forward Index)和倒排索引(Inverted Index)是全文检索中常用的两种索引结构,它们在索引和搜索的过程中扮演不同的角色。
正排索引(正向索引)
正排索引是将文档按顺序排列并进行编号的索引结构。每个文档都包含了完整的文本内容,以及其他相关的属性或元数据,如标题、作者、发布日期等。在正排索引中,可以根据文档编号或其他属性快速定位和访问文档的内容。正排索引适合用于需要对文档进行整体检索和展示的场景,但对于包含大量文本内容的数据集来说,正排索引的存储和查询效率可能会受到限制。
在MySQL 中通过 ID 查找就是一种正排索引的应用。
倒排索引(反向索引)
倒排索引是根据单词或短语建立的索引结构。它将每个单词映射到包含该单词的文档列表中。倒排索引的建立过程是先对文档进行分词处理,然后记录每个单词在哪些文档中出现,以及出现的位置信息。通过倒排索引,可以根据关键词或短语快速找到包含这些词语的文档,并确定它们的相关性。倒排索引适用于在大规模文本数据中进行关键词搜索和相关性排序的场景,它能够快速定位文档,提高搜索效率。
我们在创建文章的时候,建立一个关键词与文章的对应关系表,就可以称之为倒排索引。如下图所示:
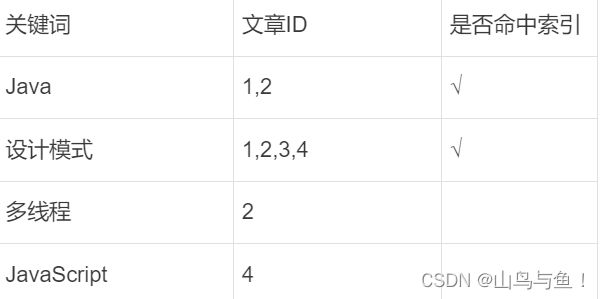
ElasticSearch介绍
ElasticSearch(简称ES)是一个开源的分布式搜索和数据分析引擎,是用Java开发并且是当前最流行的开源的企业级搜索引擎,能够达到近实时搜索,它专门设计用于处理大规模的文本数据和实现高性能的全文检索。
Elasticsearch 的特点和优势:
1. 分布式架构:Elasticsearch 是一个分布式系统,可以轻松地水平扩展,处理大规模的数据集和高并发的查询请求。
2. 全文检索功能:Elasticsearch 提供了强大的全文检索功能,包括分词、词项查询、模糊匹配、多字段搜索等,并支持丰富的查询语法和过滤器。
3. 多语言支持:Elasticsearch 支持多种语言的分词器和语言处理器,可以很好地处理不同语言的文本数据。
4. 高性能:Elasticsearch 使用倒排索引和缓存等技术,具有快速的搜索速度和高效的查询性能。
5. 实时性:Elasticsearch 支持实时索引和搜索,可以几乎实时地将文档添加到索引中,并立即可见。
6. 易用性:Elasticsearch 提供了简单易用的 RESTful API,方便进行索引管理、查询操作和数据分析。
ElasticSearch应用场景
只要用到搜索的场景,ES几乎都可以是最好的选择。国内现在有大量的公司都在使用 Elasticsearch,包括携程、滴滴、今日头条、饿了么、360安全、小米、vivo等诸多知名公司。除了搜索之外,结合Kibana、Logstash、Beats,Elastic Stack还被广泛运用在大数据近实时分析领域,包括日志分析、指标监控、信息安全等多个领域。
ElasticSearch下载安装(windows)
下载地址: https://www.elastic.co/cn/downloads/past-releases#elasticsearch
选择版本:7.17.3

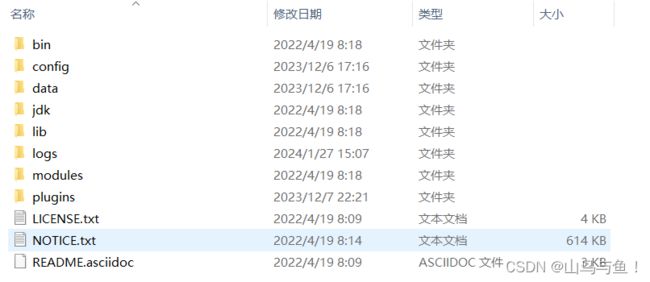
ElasticSearch文件目录结构
设置ES_JAVA_HOME和ES_HOME的环境变量

启动ElasticSearch服务
进入bin目录,直接运行elasticsearch.bat
浏览器中访问:http://localhost:9200/
客户端Kibana安装
Kibana是一个开源分析和可视化平台,旨在与Elasticsearch协同工作。
下载并解压缩Kibana
下载地址:https://www.elastic.co/cn/downloads/past-releases#kibana
选择版本:7.17.3

修改Kibana.yml,路径config/kibana.yml
server.port: 5601 #指定Kibana服务器监听的端口号
server.host: "localhost" #指定Kibana服务器绑定的主机地址
elasticsearch.hosts: ["http://localhost:9200"] #指定Kibana连接到的Elasticsearch实例的访问地址
i18n.locale: "zh-CN" #将 Kibana 的界面语言设置为简体中文运行Kibana:直接执行kibana.bat
访问 http://127.0.0.1:5601/app/dev_tools#/console

cat API
cat API 是 Elasticsearch 提供的一个用于查看和显示集群信息的 RESTful API。它可以用于获取关于索引、节点、分片、健康状态等各种集群相关的信息。
/_cat/allocation #查看单节点的shard分配整体情况
/_cat/shards #查看各shard的详细情况
/_cat/shards/{index} #查看指定分片的详细情况
/_cat/master #查看master节点信息
/_cat/nodes #查看所有节点信息
/_cat/indices #查看集群中所有index的详细信息
/_cat/indices/{index} #查看集群中指定index的详细信息
/_cat/segments #查看各index的segment详细信息,包括segment名, 所属shard, 内存(磁盘)占用大小, 是否刷盘
/_cat/segments/{index}#查看指定index的segment详细信息
/_cat/count #查看当前集群的doc数量
/_cat/count/{index} #查看指定索引的doc数量
/_cat/recovery #查看集群内每个shard的recovery过程.调整replica。
/_cat/recovery/{index}#查看指定索引shard的recovery过程
/_cat/health #查看集群当前状态:红、黄、绿
/_cat/pending_tasks #查看当前集群的pending task
/_cat/aliases #查看集群中所有alias信息,路由配置等
/_cat/aliases/{alias} #查看指定索引的alias信息
/_cat/thread_pool #查看集群各节点内部不同类型的threadpool的统计信息,
/_cat/plugins #查看集群各个节点上的plugin信息
/_cat/fielddata #查看当前集群各个节点的fielddata内存使用情况
/_cat/fielddata/{fields} #查看指定field的内存使用情况,里面传field属性对应的值
/_cat/nodeattrs #查看单节点的自定义属性
/_cat/repositories #输出集群中注册快照存储库
/_cat/templates #输出当前正在存在的模板信息Elasticsearch安装分词插件
http://127.0.0.1:5601/app/dev_tools#/console在线安装analysis-icu分词插件
#查看已安装插件
bin/elasticsearch-plugin list
#安装插件
bin/elasticsearch-plugin install analysis-icu
#删除插件
bin/elasticsearch-plugin remove analysis-icu注意:安装和删除完插件后,需要重启ES服务才能生效。
测试分词效果
# _analyzer API可以用来查看指定分词器的分词结果
POST _analyze
{
"analyzer":"icu_analyzer",
"text":"中华人民共和国"
} 
#ES的默认分词设置是standard,会单字拆分
POST _analyze
{
"analyzer":"standard",
"text":"中华人民共和国"
}
#ik_smart:会做最粗粒度的拆
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
#ik_max_word:会将文本做最细粒度的拆分
POST _analyze
{
"analyzer":"ik_max_word",
"text":"中华人民共和国"
}ElasticSearch快速开始
节点:Node
一个节点就是一个Elasticsearch的实例,可以理解为一个 ES 的进程。
注意:一个节点 ≠ 一台服务器
角色:Roles
ES的角色分类:
1. 主节点(active master):一般指活跃的主节点,一个集群中只能有一个,主要作用是对集群的管理。
2. 候选节点(master-eligible):当主节点发生故障时,参与选举,也就是主节点的替代节点。
3. 数据节点(data node):数据节点保存包含已编入索引的文档的分片。数据节点处理数据相关操作,如 CRUD、搜索和聚合。这些操作是 I/O 密集型、内存密集型和 CPU 密集型的。监控这些资源并在它们过载时添加更多数据节点非常重要。
4. 预处理节点(ingest node):预处理节点有点类似于logstash的消息管道,所以也叫ingest pipeline,常用于一些数据写入之前的预处理操作。
注意:如果 node.roles 为缺省配置,那么当前节点具备所有角色。
索引:Index
在 ES 中,索引在不同的特定条件下可以表示三种不同的意思:
1. 表示源文件数据:当做数据的载体,即类比为数据表,通常称作 index。例如:通常说集群中有 product 索引,即表述当前 ES 的服务中存储了 product 这样一张“表”。
2. 表示索引文件:以加速查询检索为目的而设计和创建的数据文件,通常承载于某些特定的数据结构,如哈希、FST 等。例如:通常所说的正排索引和倒排索引(也叫正向索引和反向索引)。就是当前这个表述,索引文件和源数据是完全独立的,索引文件存在的目的仅仅是为了加快数据的检索,不会对源数据造成任何影响,
3. 表示创建数据的动作:通常说创建或添加一条数据,在 ES 的表述为索引一条数据或索引一条文档,或者 index 一个 doc 进去。此时索引一条文档的含义为向索引中添加数据。
索引的组成部分:
alias:索引别名
settings:索引设置,常见设置如分片和副本的数量等。
mapping:映射,定义了索引中包含哪些字段,以及字段的类型、长度、分词器等。

类型:Type(ES 7.x 之后版本已删除此概念)
ES 8.x不再支持在请求中指定类型。该include_type_name参数被删除。
文档:Document
文档是ES中的最小数据单元。它是一个具有结构化JSON格式的记录。文档可以被索引并进行搜索、更新和删除操作。

文档元数据,所有字段均以下划线开头,为系统字段,用于标注文档的相关信息:
_index:文档所属的索引名。
_type:文档所属的类型名。
_id:文档唯一id。
_source: 文档的原始Json数据。
_version: 文档的版本号,修改删除操作_version都会自增1。
_seq_no: 和_version一样,一旦数据发生更改,数据也一直是累计的。Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no。
_primary_term: _primary_term主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,避免Primary Shard上的写入被覆盖。每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1。
ElasticSearch索引操作
创建索引
格式: PUT /索引名称
索引命名规范:
1. 以小写英文字母命名索引
2. 不要使用驼峰命名法则
3. 如过出现多个单词的索引名称,以全小写 + 下划线分隔的方式:如test_index。
ES 索引创建成功之后,以下属性将不可修改:
1. 索引名称
2. 主分片数量
3. 字段类型
#创建索引
PUT /索引名
查询索引
格式: GET /索引名称
#查询索引
GET /test
#test是否存在
HEAD /test
删除索引
格式: DELETE /索引名称
DELETE /test设置Settings
创建索引的时候指定 settings
创建索引时可以设置分片数和副本数。
#创建索引test,指定其主分片数量为 3,每个主分片的副本数量为 2
PUT /test
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}创建索引时可以指定IK分词器作为默认分词器
PUT /test
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
} 
设置文档映射Mapping
ES中Mapping可以分为动态映射和静态映射。
查看完整的索引 mapping
GET //_mappings
查看索引中指定字段的 mapping
GET //_mappings/field/ mapping的使用禁忌:
ES 没有隐式类型转换
ES 不支持类型修改
生产环境尽可能的避免使用动态映射(dynamic mapping)
动态映射
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射,在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
自动类型推断规则

#创建文档(ES根据数据类型, 会自动创建映射)
PUT /user/_doc/1
{
"name":"zhagsan",
"age":18,
"address":"北京"
}
#获取文档映射
GET /user/_mapping
静态映射
在索引文档写入之前,人为创建索引并且指定索引中每个字段类型、分词器等参数。
PUT /user
{
"settings": {
"number_of_shards": "1",
"number_of_replicas": "1"
},
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age" : {
"type" : "long"
},
"address" : {
"type" : "text"
}
}
}
}使用ReIndex重建索引
具体方法:
1)如果要推倒现有的映射,你得重新建立一个静态索引。
2)然后把之前索引里的数据导入到新的索引里。
3)删除原创建的索引。
4)为新索引起个别名,为原索引名。
通过这几个步骤可以实现了索引的平滑过渡,并且是零停机。
PUT /user2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
# 2. 把之前索引里的数据导入到新的索引里
POST _reindex
{
"source": {
"index": "user"
},
"dest": {
"index": "user2"
}
}
# 3. 删除原创建的索引
DELETE /user
# 4. 为新索引起个别名, 为原索引名
PUT /user2/_alias/user
GET /userElasticSearch文档操作
索引文档
格式: [PUT | POST] /索引名称/[_doc | _create ]/id
# 创建文档,指定id
# 如果id不存在,创建新的文档,否则先删除现有文档,再创建新的文档,版本会增加
PUT /user/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "北京",
"remark": "java"
}
#创建文档,ES生成id
POST /user/_doc
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "北京",
"remark": "java"
}注意:POST和PUT都能起到创建/更新的作用,PUT需要对一个具体的资源进行操作也就是要确定id才能进行更新/创建,而POST是可以针对整个资源集合进行操作的,如果不写id就由ES生成一个唯一id进行创建新文档,如果填了id那就针对这个id的文档进行创建/更新。
简单查询文档
根据id查询文档,格式: GET /索引名称/_doc/id
GET /user/_doc/1条件查询 _search,格式: /索引名称/_doc/_search
GET /test/_doc/_search修改文档
全量更新,整个json都会替换,格式: [PUT | POST] /索引名称/_doc/id,如果文档存在,现有文档会被删除,新的文档会被索引。
# 全量更新,替换整个json
PUT /user/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25
}
#查询文档
GET /user/_doc/1使用_update部分更新,格式: POST /索引名称/_update/id,update不会删除原来的文档,而是实现真正的数据更新。
# 部分更新:在原有文档上更新
# Update -文档必须已经存在,更新只会对相应字段做增量修改
POST /user/_update/1
{
"doc": {
"age": 28
}
}
#查询文档
GET /user/_doc/1使用 _update_by_query 更新文档
POST /test/_update_by_query
{
"query": {
"match": {
"_id": 1
}
},
"script": {
"source": "ctx._source.age = 30"
}
}并发场景下修改文档
_seq_no和_primary_term是对_version的优化,7.X版本的ES默认使用这种方式控制版本,所以当在高并发环境下使用乐观锁机制修改文档时,要带上当前文档的_seq_no和_primary_term进行更新:
POST /user/_doc/2?if_seq_no=21&if_primary_term=6
{
"name": "李四xxx"
}删除文档
格式: DELETE /索引名称/_doc/id
DELETE /test/_doc/1批量写入
批量对文档进行写操作是通过_bulk的API来实现的
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}actionName:表示操作类型,主要有create,index,delete和update
批量创建文档create
POST _bulk
{"create":{"_index":"article", "_type":"_doc", "_id":3}}
{"id":3,"title":"zhangsan","content":"666","tags":["java", "面向对象"]}
{"create":{"_index":"article", "_type":"_doc", "_id":4}}
{"id":4,"title":"lisi","content":"777","tags":["java", "面向对象"]}如果原文档不存在,则是创建
如果原文档存在,则是替换(全量修改原文档)
批量删除delete
POST _bulk
{"delete":{"_index":"article", "_type":"_doc", "_id":3}}
{"delete":{"_index":"article", "_type":"_doc", "_id":4}}批量修改update
POST _bulk
{"update":{"_index":"article", "_type":"_doc", "_id":3}}
{"doc":{"title":"888"}}
{"update":{"_index":"article", "_type":"_doc", "_id":4}}
{"doc":{"title":"999"}}批量读取
es的批量查询可以使用mget和msearch两种。其中mget是需要我们知道它的id,可以指定不同的index,也可以指定返回值source。msearch可以通过字段查询来进行一个批量的查找。
_mget
#可以通过ID批量获取不同index和type的数据
GET _mget
{
"docs": [
{
"_index": "user",
"_id": 1
},
{
"_index": "test",
"_id": 4
}
]
}
#可以通过ID批量获取es_db的数据
GET /user/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 4
}
]
}
#简化后
GET /user/_mget
{
"ids":["1","2"]
}_msearch
在_msearch中,请求格式和bulk类似。查询一条数据需要两个对象,第一个设置index和type,第二个设置查询语句。查询语句和search相同。如果只是查询一个index,我们可以在url中带上index,这样,如果查该index可以直接用空对象表示。
GET /test/_msearch
{}
{"query" : {"match_all" : {}}, "from" : 0, "size" : 2}
{"index" : "user"}
{"query" : {"match_all" : {}}}