DS Wannabe之5-AM Project: DS 30day int prep day12
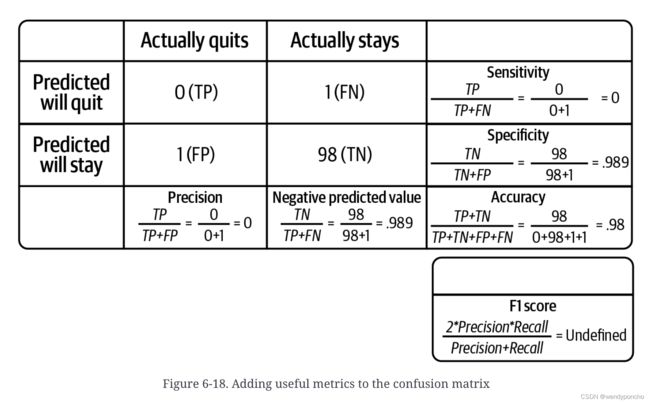
Q1. Where is the confusion matrix used? Which module would you use to show it?
混淆矩阵
混淆矩阵常用于评估分类模型的性能,特别是在二分类或多分类问题中。它展示了实际类别与模型预测类别之间的关系。在Python中,可以使用sklearn.metrics模块中的confusion_matrix函数来展示混淆矩阵。
Creating a confusion matrix for a testing dataset in SciPy
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# Load the data
df = pd.read_csv('https://bit.ly/3cManTi', delimiter=",")
# Extract input variables (all rows, all columns but last column)
X = df.values[:, :-1]
# Extract output column (all rows, last column)\
Y = df.values[:, -1]
model = LogisticRegression(solver='liblinear')
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=.33,
random_state=10)
model.fit(X_train, Y_train)
prediction = model.predict(X_test)
"""
The confusion matrix evaluates accuracy within each category.
[[truepositives falsenegatives]
[falsepositives truenegatives]]
The diagonal represents correct predictions,
so we want those to be higher
"""
matrix = confusion_matrix(y_true=Y_test, y_pred=prediction)
print(matrix)Q2: What is Accuracy?
准确率?
准确率是衡量分类模型性能的指标,表示模型正确预测的样本占总样本的比例。计算公式为:(正确预测的正样本数 + 正确预测的负样本数) / 总样本数。
It is the most intuitive performance measure and it simply a ratio of correctly predicted to the total observations. We can say as, if we have high accuracy, then our model is best. Yes, we could say that accuracy is a great measure but only when you have symmetric datasets where false positives and false negatives are almost same.
Accuracy = True Positive + True Negative / (True Positive +False Positive + False Negative + True Negative)
Q3: What is Precision?
精确率?
精确率是衡量模型预测为正类别准确性的指标,
计算公式为:正确预测的正样本数 / (正确预测的正样本数 + 错误预测为正样本的负样本数)。
It is also called as the positive predictive value. Number of correct positives in your model that predicts compared to the total number of positives it predicts.
Precision = True Positives / (True Positives + False Positives) Precision = True Positives / Total predicted positive
It is the number of positive elements predicted properly divided by the total number of positive elements predicted.
We can say Precision is a measure of exactness, quality, or accuracy. High precision Means that more or all of the positive results you predicted are correct.
Q4: What is Recall?
Recall we can also called as sensitivity or true positive rate.
It is several positives that our model predicts compared to the actual number of positives in our data.
Recall = True Positives / (True Positives + False Positives)
Recall = True Positives / Total Actual Positive
Recall is a measure of completeness. High recall which means that our model classified most or all of the possible positive elements as positive.
Q5: What is F1 Score?
F1分数?
F1分数是精确率和召回率的调和平均值,用于衡量模型的准确性和召回能力的平衡性,特别适用于类别不平衡的情况。
计算公式为:2 * (精确率 * 召回率) / (精确率 + 召回率)。
We use Precision and recall together because they complement each other in how they describe the effectiveness of a model. The F1 score that combines these two as the weighted harmonic mean of precision and recall.
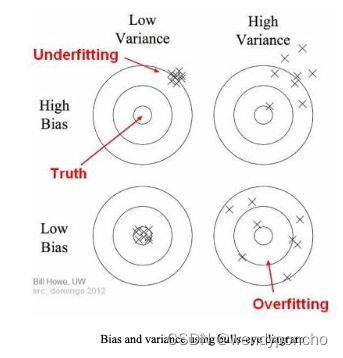
Q6: What is Bias and Variance trade-off?
偏差和方差的权衡?
偏差是模型的预测值与真实值之间的差异,方差是模型对训练集的小变动敏感程度。偏差和方差的权衡是机器学习中一个核心概念,指的是减少偏差可能导致方差增加,反之亦然。目标是找到两者之间的最佳平衡点,以提高模型的泛化能力。
Bias
Bias means it’s how far are the predict values from the actual values. If the average predicted values are far off from the actual values, then we called as this one have high bias.
When our model has a high bias, then it means that our model is too simple and does not capture the complexity of data, thus underfitting the data.
Variance
It occurs when our model performs good on the trained dataset but does not do well on a dataset that it is not trained on, like a test dataset or validation dataset. It tells us that actual value is how much scattered from the predicted value.
Because of High variance it cause overfitting that implies that the algorithm models random noise present in the training data.
When model have high variance, then model becomes very flexible and tune itself to the data points of the training set.

这张图展示了模型复杂度与预测误差之间的关系,并解释了偏差-方差权衡(Bias-Variance Tradeoff)的概念。
- 红色曲线:代表在测试样本上的预测误差。
- 青色曲线:代表在训练样本上的预测误差。
当模型复杂度较低时(图左侧),训练误差和测试误差都比较高。这是由于模型过于简单,无法捕捉数据的复杂性,从而导致高偏差。这种情况通常被称为欠拟合(Underfitting)。
随着模型复杂度的增加(向右移动),训练误差逐渐降低,因为模型能够更好地拟合训练数据。然而,测试误差开始下降后会在某一点开始再次上升,这是因为模型变得过于复杂,以至于开始学习到训练数据中的噪声,而不仅仅是潜在的模式。这导致了高方差。这种情况通常被称为过拟合(Overfitting)。
在图的中间部分,训练误差和测试误差之间的差距最小,这通常是模型复杂度的“最佳点”,即模型既不过于简单也不过于复杂,能够很好地泛化到未见数据。
- 高偏差低方差(图左上角):模型过于简化,无法捕捉数据的真实结构,但对不同的训练数据集表现出较为一致的行为。
- 低偏差高方差(图右上角):模型复杂度高,对训练数据的小变动非常敏感,导致在不同的训练数据集上表现出很大的差异。
整体来说,这个图传达了在模型选择时需要平衡模型的复杂度,以便在偏差和方差之间找到最佳平衡点,从而最小化总体的预测误差
Q7. What is data wrangling? Mention three points to consider in the process.
Data wrangling is a process by which we convert and map data. This changes data from its raw form to a format that is a lot more valuable.
Data wrangling is the first step for machine learning and deep learning. The end goal is to provide data that is actionable and to provide it as fast as possible.
There are three major things to focus on while talking about data wrangling –
1. Acquiring data
The first and probably the most important step in data science is the acquiring, sorting and cleaning of data. This is an extremely tedious process and requires the most amount of time.
One needs to:
-
Check if the data is valid and up-to-date.
-
Check if the data acquired is relevant for the problem at hand.
Sources for data collection Data is publicly available on various websites like kaggle.com, data.gov ,World Bank, Five Thirty Eight Datasets, AWS Datasets, Google Datasets.
2. Data cleaning
Data cleaning is an essential component of data wrangling and requires a lot of patience. To make the job easier it is first essential to format the data make the data readable for humans at first.
The essentials involved are:
-
Format the data to make it more readable
-
Find outliers (data points that do not match the rest of the dataset) in data
-
Find missing values and remove them from the data set (without this, any model being
trained becomes incomplete and useless)
3. Data Computation
At times, your machine not have enough resources to run your algorithm e.g. you might not have a GPU. In these cases, you can use publicly available APIs to run your algorithm. These are standard end points found on the web which allow you to use computing power over the web and process data without having to rely on your own system. An example would be the Google Colab Platform.
Q8. Why is normalization required before applying any machine learning model? What module can you use to perform normalization?
| Normalization is a process that is required when an algorithm uses something like distance measures. Examples would be clustering data, finding cosine similarities, creating recommender systems. Normalization is not always required and is done to prevent variables that are on higher scale from affecting outcomes that are on lower levels. For example, consider a dataset of employees’ income. This data won’t be on the same scale if you try to cluster it. Hence, we would have to normalize the data to prevent incorrect clustering. A key point to note is that normalization does not distort the differences in the range of values. A problem we might face if we don’t normalize data is that gradients would take a very long time to descend and reach the global maxima/ minima. For numerical data, normalization is generally done between the range of 0 to 1. The general formula is: |
应用任何机器学习模型之前需要进行归一化?使用哪个模块进行归一化?
归一化是将不同量级的数据转换到同一尺度的过程,这对于大多数机器学习模型非常重要,因为它们对输入特征的量级非常敏感。归一化可以提高模型的收敛速度和性能。在Python中,可以使用sklearn.preprocessing模块中的MinMaxScaler或StandardScaler等函数进行归一化。
Q9. What is the difference between feature selection and feature extraction?
特征选择与特征提取有什么区别?
特征选择是从原始特征中选择一部分重要特征,以减少特征的数量,而不改变原始特征的含义。特征提取是将原始数据转换或压缩成新的特征集(可能减少了特征的维度),这些新的特征是原始特征的变换或组合,可能会改变原始特征的含义。
Feature selection and feature extraction are two major ways of fixing the curse of dimensionality
| 1. Feature selection: Feature selection is used to filter a subset of input variables on which the attention should focus. Every other variable is ignored. This is something which we, as humans, tend to do subconsciously. Many domains have tens of thousands of variables out of which most are irrelevant and redundant. Feature selection limits the training data and reduces the amount of computational resources used. It can significantly improve a learning algorithms performance. In summary, we can say that the goal of feature selection is to find out an optimal feature subset. This might not be entirely accurate, however, methods of understanding the importance of features also exist. Some modules in python such as Xgboost help achieve the same. |
| 2. Feature extraction Feature extraction involves transformation of features so that we can extract features to improve the process of feature selection. For example, in an unsupervised learning problem, the extraction of bigrams from a text, or the extraction of contours from an image are examples of feature extraction. The general workflow involves applying feature extraction on given data to extract features and then apply feature selection with respect to the target variable to select a subset of data. In effect, this helps improve the accuracy of a model. |
Q10. Why is polarity and subjectivity an issue?
Polarity and subjectivity are terms which are generally used in sentiment analysis.
| Polarity is the variation of emotions in a sentence. Since sentiment analysis is widely dependent on emotions and their intensity, polarity turns out to be an extremely important factor. In most cases, opinions and sentiment analysis are evaluations. They fall under the categories of emotional and rational evaluations. |
| Rational evaluations, as the name suggests, are based on facts and rationality while emotional evaluations are based on non-tangible responses, which are not always easy to detect. Subjectivity in sentiment analysis, is a matter of personal feelings and beliefs which may or may not be based on any fact. When there is a lot of subjectivity in a text, it must be explained and analysed in context. On the contrary, if there was a lot of polarity in the text, it could be expressed as a positive, negative or neutral emotion. |
Q11. When would you use ARIMA?
ARIMA is a widely used statistical method which stands for Auto Regressive Integrated Moving Average. It is generally used for analyzing time series data and time series forecasting. Let’s take a quick look at the terms involved. Auto Regression is a model that uses the relationship between the observation and some numbers of lagging observations.
ARIMA(自回归积分滑动平均模型)是一种广泛使用的统计方法,常用于分析时间序列数据和进行时间序列预测。下面是涉及的一些术语的快速概述:

-
自回归(AR):这是一种模型,它使用当前观测值与其自身在之前若干时间点的观测值之间的关系。简言之,它表明了当前值如何被其历史值所影响。
-
差分(I):这是使时间序列数据稳定的过程,通常通过计算连续观测值之间的差异来完成。这有助于去除数据中的趋势和季节性成分,使其更适合进行模型拟合。
-
滑动平均(MA):这部分模型使用观测值的滑动平均误差来预测未来值。它反映了当前值与历史预测误差之间的关系。
你可能会在以下情况下使用ARIMA模型:
-
时间序列预测:当你有一个时间序列数据集,并且你想预测未来的数据点时,ARIMA是一个强有力的工具。这在经济学、股市预测、气象学和任何需要预测未来趋势的领域中都非常有用。
-
数据分析:ARIMA可以帮助你理解数据中的某些模式,例如季节性变化、趋势或周期性波动。
-
去趋势和去季节性处理:通过ARIMA模型的差分部分,你可以将数据转换成一个更稳定的形式,这对于去除趋势和季节性成分很有帮助。
-
长期预测:尽管ARIMA模型对于短期预测更加有效,但在某些情况下,它也可以用于长期预测,尤其是当数据表现出明显的稳定模式时。
选择使用ARIMA模型的关键是确保你的时间序列数据是稳定的,或者你可以通过差分等方法使其稳定。这种模型对于非季节性、趋势性的时间序列数据特别有效。
Integrated means use of differences in raw observations which help make the time series stationary.
Moving Averages is a model that uses the relationship and dependency between the observation and residual error from the models being applied to the lagging observations.
Note that each of these components are used as parameters. After the construction of the model, a linear regression model is constructed.
Data is prepared by:
-
Finding out the differences
-
Removing trends and structures that will negatively affect the model
-
Finally, making the model stationary.
Exercise Solutions - 一些往期学习抽查QA
-
How would you define machine learning?
Machine Learning is about building systems that can learn from data. Learning means getting better at some task, given some performance measure. -
Can you name four types of applications where it shines?
Machine Learning is great for complex problems for which we have no algorithmic solution, to replace long lists of hand-tuned rules, to build systems that adapt to fluctuating environments, and finally to help humans learn (e.g., data mining). -
What is a labeled training set?
A labeled training set is a training set that contains the desired solution (a.k.a. a label) for each instance. -
What are the two most common supervised tasks?
The two most common supervised tasks are regression and classification. -
Can you name four common unsupervised tasks?
Common unsupervised tasks include clustering, visualization, dimensionality reduction, and association rule learning. -
What type of algorithm would you use to allow a robot to walk in various unknown terrains?
Reinforcement Learning is likely to perform best if we want a robot to learn to walk in various unknown terrains. -
What type of algorithm would you use to segment your customers into multiple groups?
If you don't know how to define the groups, then you can use a clustering algorithm (unsupervised learning) to segment your customers into clusters of similar customers. -
Would you frame the problem of spam detection as a supervised learning problem or an unsupervised learning problem?
Spam detection is a typical supervised learning problem: the algorithm is fed many emails along with their labels (spam or not spam). -
What is an online learning system?
An online learning system can learn incrementally, as opposed to a batch learning system. -
What is out-of-core learning?
Out-of-core algorithms can handle vast quantities of data that cannot fit in a computer's main memory. -
What type of algorithm relies on a similarity measure to make predictions?
An instance-based learning system learns the training data by heart; then, when given a new instance, it uses a similarity measure to find the most similar learned instances and uses them to make predictions. -
What is the difference between a model parameter and a model hyperparameter?
A model parameter determines what the model will predict given a new instance, while a hyperparameter is a parameter of the learning algorithm itself, not of the model. -
What do model-based algorithms search for? What is the most common strategy they use to succeed? How do they make predictions?
Model-based learning algorithms search for an optimal value for the model parameters such that the model will generalize well to new instances. They usually minimize a cost function and make predictions by feeding new instance's features into the model's prediction function. -
Can you name four of the main challenges in machine learning?
Some of the main challenges are the lack of data, poor data quality, nonrepresentative data, and excessively complex models that overfit the data. -
If your model performs great on the training data but generalizes poorly to new instances, what is happening? Can you name three possible solutions?
The model is likely overfitting the training data. Possible solutions include getting more data, simplifying the model, or reducing the noise in the training data.