本文的主要目的是理解cache_t以及sel-imp的缓存原理
整体分析
在之前的isa底层分析和类的结构分析中,分析了objc_class中isa和bits,这次主要是分析objc_calss中的cache属性
cache中存储的是什么?
首先,我们需要知道cache中存储的到底是什么?
- 查看
cache_t的源码,发现分成了3个架构的处理,其中真机的架构中,mask和bucket是写在一起,目的是为了优化,可以通过各自的掩码来获取相应的数据
CACHE_MASK_STORAGE_OUTLINED表示运行的环境模拟器或者macOS
CACHE_MASK_STORAGE_HIGH_16表示运行环境是64位的真机
CACHE_MASK_STORAGE_LOW_4 表示运行环境是非64位的真机
struct cache_t {
#if CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_OUTLINED//macOS、模拟器 -- 主要是架构区分
// explicit_atomic 显示原子性,目的是为了能够 保证 增删改查时 线程的安全性
//等价于 struct bucket_t * _buckets;
//_buckets 中放的是 sel imp
//_buckets的读取 有提供相应名称的方法 buckets()
explicit_atomic _buckets;
explicit_atomic _mask;
#elif CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_HIGH_16 //64位真机
explicit_atomic _maskAndBuckets;//写在一起的目的是为了优化
mask_t _mask_unused;
//以下都是掩码,即面具 -- 类似于isa的掩码,即位域
// 掩码省略....
#elif CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_LOW_4 //非64位 真机
explicit_atomic _maskAndBuckets;
mask_t _mask_unused;
//以下都是掩码,即面具 -- 类似于isa的掩码,即位域
// 掩码省略....
#else
#error Unknown cache mask storage type.
#endif
#if __LP64__
uint16_t _flags;
#endif
uint16_t _occupied;
//方法省略.....
}
- 查看bucket_t的源码,同样分为两个版本,真机 和 非真机,不同的区别在于sel 和 imp的顺序不一致
struct bucket_t {
private:
#if __arm64__ //真机
//explicit_atomic 是加了原子性的保护
explicit_atomic _imp;
explicit_atomic _sel;
#else //非真机
explicit_atomic _sel;
explicit_atomic _imp;
#endif
//方法等其他部分省略
}
所以通过上面两个结构体源码可知,cache中缓存的是sel-imp
整体的结构如下图所示
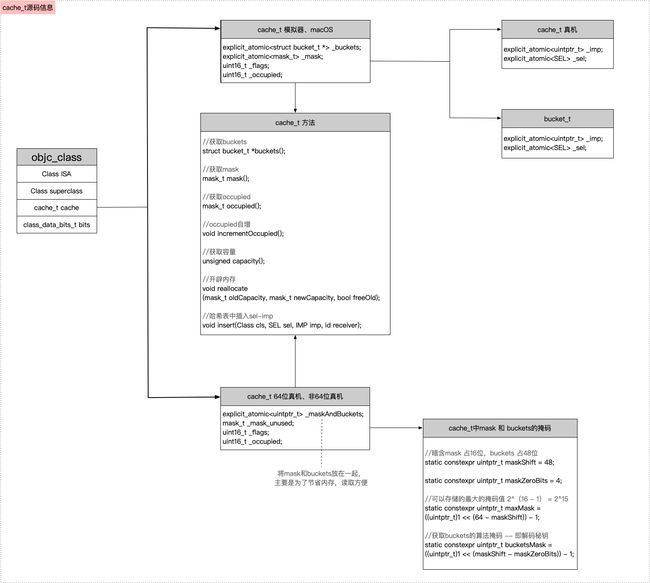
在cache中查找sel-imp
cache_t中查找存储的sel-imp,有以下两种方式
- 通过源码查找
- 脱离源码在项目中查找
准备工作
-
定义一个
LGPerson类,并定义两个属性及5个实例方法及其实现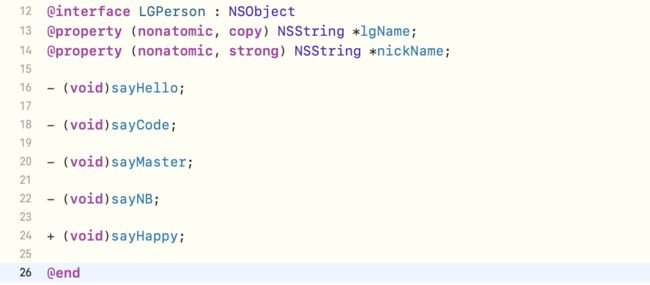

在
main中定义LGPerson类的对象p,并调用其中的3个实例方法,在p调用第一个方法处加一个断点
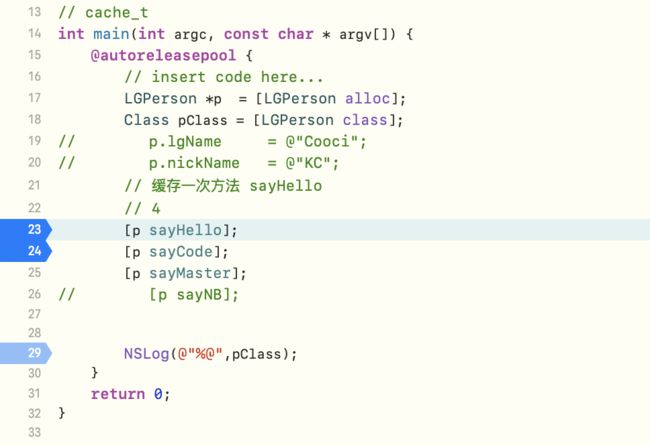
通过源码查找
-
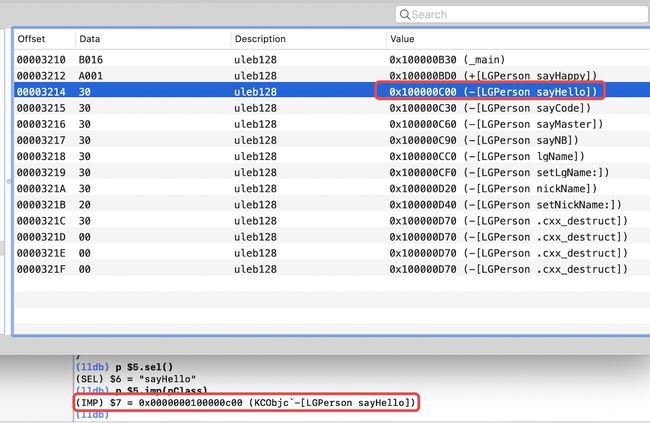
运行执行,断在
[p sayHello];部分,此时执行以下lldb调试流程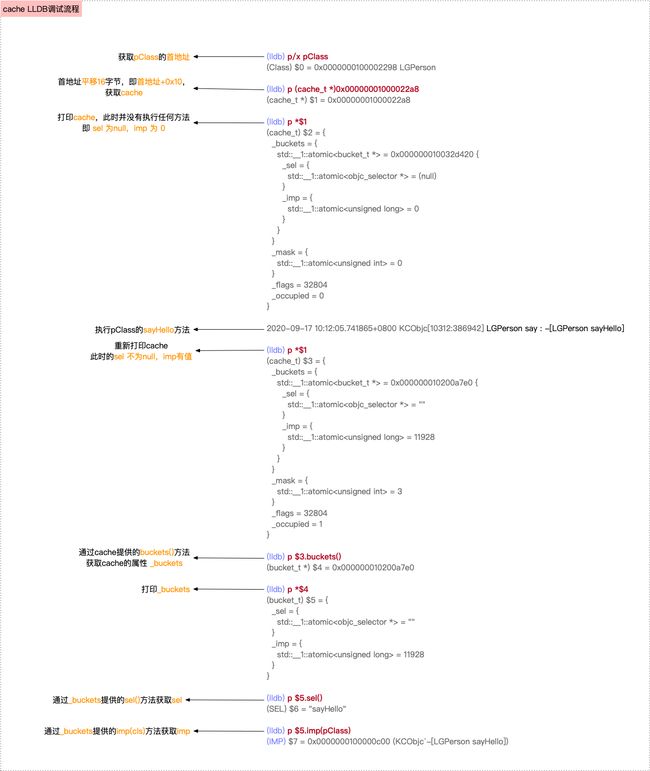 仅一个方法调用的sel-imp查找流程
仅一个方法调用的sel-imp查找流程 cache属性的获取,需要通过pclass的首地址平移16字节,即首地址+0x10获取cache的地址从源码的分析中,我们知道
sel-imp是在cache_t的_buckets属性中(目前处于macOS环境),而在cache_t结构体中提供了获取_buckets属性的方法buckets()获取了
_buckets属性,就可以获取sel-imp了,这两个的获取在bucket_t结构体中同样提供了相应的获取方法sel()以及imp(pClass)
由上图可知,在没有执行方法调用时,此时的cache是没有缓存的,执行了一次方法调用,cache中就有了一个缓存,即调用一次方法就会缓存一次方法。
我们现在了解了如何获取cache中sel-imp,如何验证打印的sel和imp就是我们调用的呢?可以通过machoView打开target的可执行文件,在方法列表中查看其imp的值是否是一致的,如下所示,发现是一致的,所以打印的这个sel-imp就是LGPerson的实例方法
- 接着上面的步骤,我们再次调用一个方法,这次我们想要获取第二个sel,其调试的lldb如下

第一个调用方法的存储获取很简单,直接通过_buckets的首地址调用对应的方法即可,所以我们这里可以通过_buckets属性的首地址偏移,即 p *($9+1)即可获取第二个方法的sel 和imp
如果有多个方法需要获取,以此类推,例如p *($9+i)
脱离源码通过项目查找
脱离源码环境,就是将所需的源码的部分拷贝至项目中,其完整代码如下
typedef uint32_t mask_t; // x86_64 & arm64 asm are less efficient with 16-bits
struct lg_bucket_t {
SEL _sel;
IMP _imp;
};
struct lg_cache_t {
struct lg_bucket_t * _buckets;
mask_t _mask;
uint16_t _flags;
uint16_t _occupied;
};
struct lg_class_data_bits_t {
uintptr_t bits;
};
struct lg_objc_class {
Class ISA;
Class superclass;
struct lg_cache_t cache; // formerly cache pointer and vtable
struct lg_class_data_bits_t bits; // class_rw_t * plus custom rr/alloc flags
};
int main(int argc, const char * argv[]) {
@autoreleasepool {
LGPerson *p = [LGPerson alloc];
Class pClass = [LGPerson class]; // objc_clas
[p say1];
[p say2];
//[p say3];
//[p say4];
struct lg_objc_class *lg_pClass = (__bridge struct lg_objc_class *)(pClass);
NSLog(@"%hu - %u",lg_pClass->cache._occupied,lg_pClass->cache._mask);
for (mask_t i = 0; icache._mask; i++) {
// 打印获取的 bucket
struct lg_bucket_t bucket = lg_pClass->cache._buckets[i];
NSLog(@"%@ - %p",NSStringFromSelector(bucket._sel),bucket._imp);
}
NSLog(@"Hello, World!");
}
return 0;
}
这里有个问题需要注意,在源码中,objc_class的ISA属性是继承自objc_object的,但在我们将其拷贝过来时,去掉了objc_class的继承关系,需要将这个属性明确,否则打印的结果是有问题,如下图所示,

加上ISA属性后,增加两个方法的调用,其正确的打印结果应该是这样的

针对上面的打印结果,有以下几点疑问
- 1、
_mask是什么? - 2、
_occupied是什么? - 3、为什么随着方法调用的增多,其打印的
occupied和mask会变化? - 4、
bucket数据为什么会有丢失的情况?,例如2-7中,只有say3、say4方法有函数指针 - 5、2-7中say3、say4的打印顺序为什么是say4先打印,say3后打印,且还是挨着的,即
顺序有问题? - 6、打印的
cache_t中的_ocupied为什么是从2开始?
带着上述的这些疑问,下面来进行cache底层原理的探索
首先,从cache_t中的_mask属性开始分析,找cache_t中引起变化的函数,发现了incrementOccupied()函数
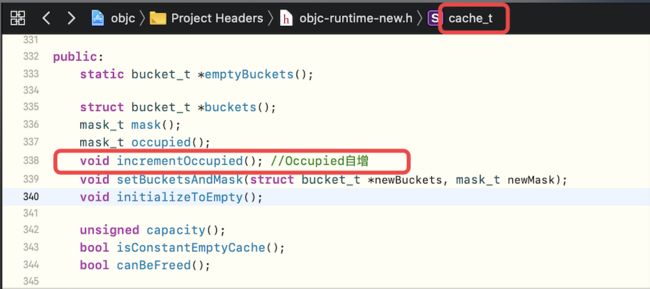
该函数的具体实现为
void incrementOccupied(); //Occupied自增
//具体实现
void cache_t::incrementOccupied()
{
_occupied++;
}
源码中,全局搜索incrementOccupied()函数,发现只在cache_t的insert方法有调用
全局搜索insert(方法,发现只有cache_fill方法中的调用符合
-
全局搜索
cache_fill,发现在写入之前,还有一步操作,即cache读取,即查找sel-imp,如下所示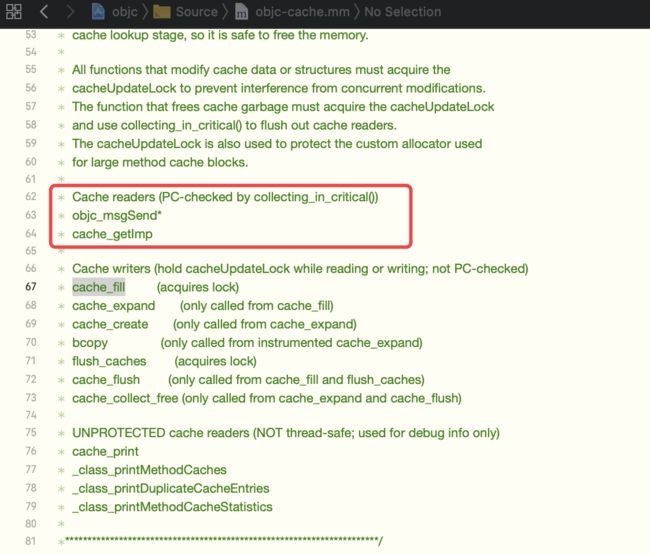
但本文的重点还是分析cache存储的原理,接下来根据cache_t写入的流程图,着重分析insert方法
insert方法分析
在insert方法中,其源码实现如下
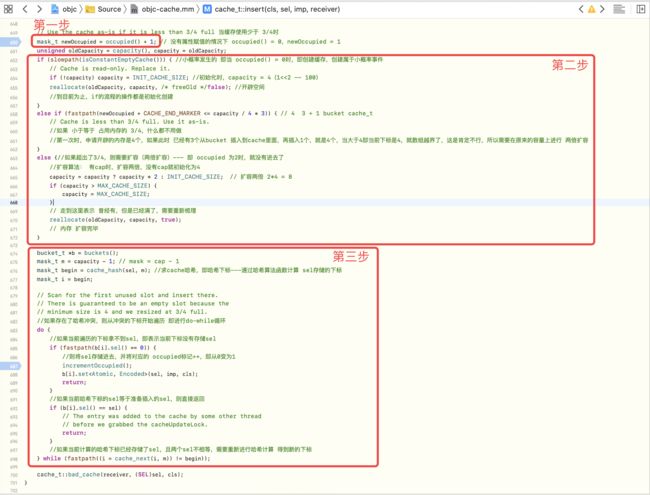
主要分为以下几部分
- 【第一步】
计算出当前的缓存占用量 - 【第二步】根据
缓存占用量``判断执行的操作 - 【第三步】针对需要存储的
bucket进行内部imp和sel赋值
其中,第一步,根据occupied的值计算出当前的缓存占用量,当属性未赋值及无方法调用时,此时的occupied()为0,而newOccupied为1,如下所示
mask_t newOccupied = occupied() + 1;
关于缓存占用量的计算,有以下几点说明:
alloc申请空间时,此时的对象已经创建,如果再调用init方法,occupied也会+1当
有属性赋值时,会隐式调用set方法,occupied也会增加,即有几个属性赋值,occupied就会在原有的基础上加几个当
有方法调用时,occupied也会增加,即有几次调用,occupied就会在原有的基础上加几个
【第二步】根据缓存占用量判断执行的操作
如果是第一次创建,则默认开辟4个
if (slowpath(isConstantEmptyCache())) { //小概率发生的 即当 occupied() = 0时,即创建缓存,创建属于小概率事件
// Cache is read-only. Replace it.
if (!capacity) capacity = INIT_CACHE_SIZE; //初始化时,capacity = 4(1<<2 -- 100)
reallocate(oldCapacity, capacity, /* freeOld */false); //开辟空间
//到目前为止,if的流程的操作都是初始化创建
}
- 如果缓存占用量小于等于3/4,则不作任何处理
else if (fastpath(newOccupied + CACHE_END_MARKER <= capacity / 4 * 3)) {
// Cache is less than 3/4 full. Use it as-is.
}
如果缓存占用量超过3/4,则需要进行两倍扩容以及重新开辟空间
else {//如果超出了3/4,则需要扩容(两倍扩容)
//扩容算法: 有cap时,扩容两倍,没有cap就初始化为4
capacity = capacity ? capacity * 2 : INIT_CACHE_SIZE; // 扩容两倍 2*4 = 8
if (capacity > MAX_CACHE_SIZE) {
capacity = MAX_CACHE_SIZE;
}
// 走到这里表示 曾经有,但是已经满了,需要重新梳理
reallocate(oldCapacity, capacity, true);
// 内存 扩容完毕
}
realloc方法:开辟空间
该方法,在第一次创建以及两倍扩容时,都会使用,其源码实现如图所示

主要有以下几步
allocateBuckets方法:向系统申请开辟内存,即开辟bucket,此时的bucket只是一个临时变量-
setBucketsAndMask方法:将临时的bucket存入缓存中,此时的存储分为两种情况:-
如果是
真机,根据bucket和mask的位置存储,并将occupied占用设置为0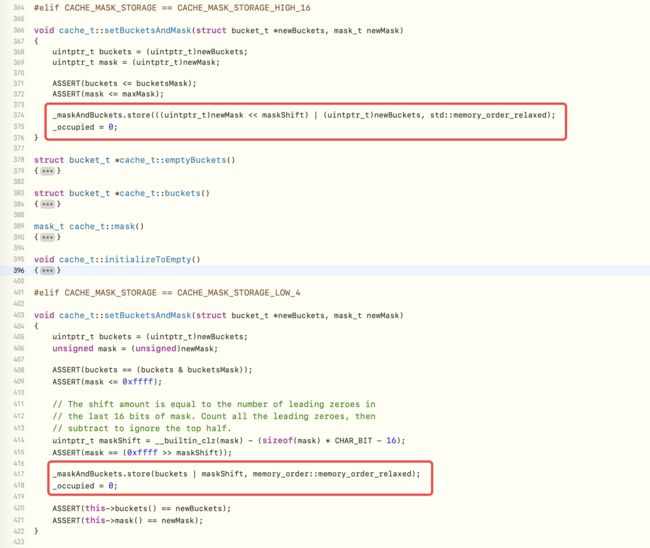 真机的setBucketsAndMask源码实现
真机的setBucketsAndMask源码实现
-
如果不是真机,正常存储bucket和mask,并将occupied占用设置为0
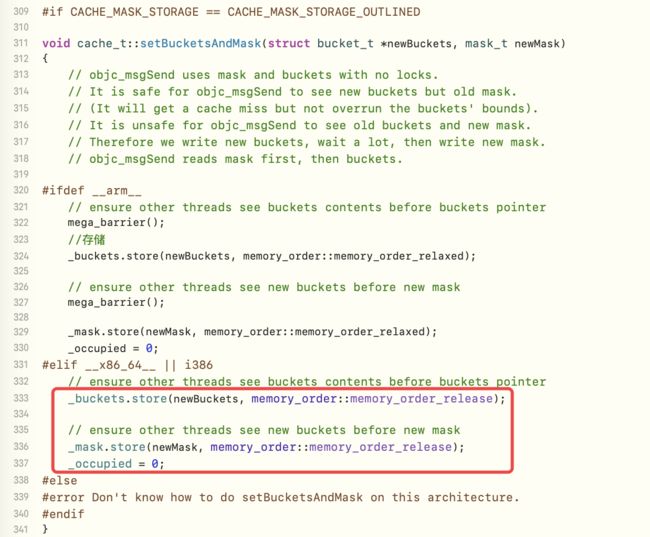
如果有旧的buckets,需要清理之前的缓存,即调用cache_collect_free方法,其源码实现如下
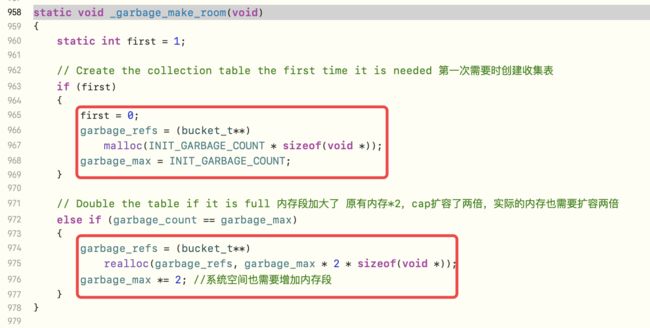
【第三步】针对需要存储的bucket进行内部imp和sel赋值
这部分主要是根据cache_hash方法,即哈希算法 ,计算sel-imp存储的哈希下标,分为以下三种情况:
如果哈希下标的位置
未存储sel,即该下标位置获取sel等于0,此时将sel-imp存储进去,并将occupied占用大小加1如果当前哈希下标存储的sel
等于即将插入的sel,则直接返回如果当前哈希下标存储的sel
不等于即将插入的sel,则重新经过cache_next方法 即哈希冲突算法,重新进行哈希计算,得到新的下标,再去对比进行存储
其中涉及的两种哈希算法,其源码如下
- cache_hash:哈希算法
static inline mask_t cache_hash(SEL sel, mask_t mask)
{
return (mask_t)(uintptr_t)sel & mask; // 通过sel & mask(mask = cap -1)
}
- cache_next:哈希冲突算法
#if __arm__ || __x86_64__ || __i386__
// objc_msgSend has few registers available.
// Cache scan increments and wraps at special end-marking bucket.
#define CACHE_END_MARKER 1
static inline mask_t cache_next(mask_t i, mask_t mask) {
return (i+1) & mask; //(将当前的哈希下标 +1) & mask,重新进行哈希计算,得到一个新的下标
}
#elif __arm64__
// objc_msgSend has lots of registers available.
// Cache scan decrements. No end marker needed.
#define CACHE_END_MARKER 0
static inline mask_t cache_next(mask_t i, mask_t mask) {
return i ? i-1 : mask; //如果i是空,则为mask,mask = cap -1,如果不为空,则 i-1,向前插入sel-imp
}
到此,cache_t的原理基本分析完成了,然后前文提及的几个问题,我们现在就有答案了
疑问解答
1、_mask是什么?
_mask是指掩码数据,用于在哈希算法或者哈希冲突算法中计算哈希下标,其中mask 等于capacity - 1
2、_occupied 是什么?
_occupied表示哈希表中 sel-imp 的占用大小 (即可以理解为分配的内存中已经存储了sel-imp的的个数)
init会导致occupied变化属性赋值,也会隐式调用,导致occupied变化方法调用,导致occupied变化
3、为什么随着方法调用的增多,其打印的occupied 和 mask会变化?
因为在cache初始化时,分配的空间是4个,随着方法调用的增多,当存储的sel-imp个数,即newOccupied + CACHE_END_MARKER(等于1)的和 超过 总容量的3/4,例如有4个时,当occupied等于2时,就需要对cache的内存进行两倍扩容
4、bucket数据为什么会有丢失的情况?,例如2-7中,只有say3、say4方法有函数指针
原因是在扩容时,是将原有的内存全部清除了,再重新申请了内存导致的
5、2-7中say3、say4的打印顺序为什么是say4先打印,say3后打印,且还是挨着的,即 顺序有问题 ?
因为sel-imp的存储是通过哈希算法计算下标的,其计算的下标有可能已经存储了sel,所以又需要通过哈希冲突算法重新计算哈希下标,所以导致下标是随机的,并不是固定的
6、打印的 cache_t 中的 ocupied 为什么是从 2 开始?
这里是因为LGPerson通过alloc创建的对象,并对其两个属性赋值的原因,属性赋值,会隐式调用set方法,set方法的调用也会导致occupied变化