controller-manager学习三部曲之三:deployment的controller启动分析
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
《controller-manager学习三部曲》完整链接
- 通过脚本文件寻找程序入口
- 源码学习
- deployment的controller启动分析
本篇概览
-
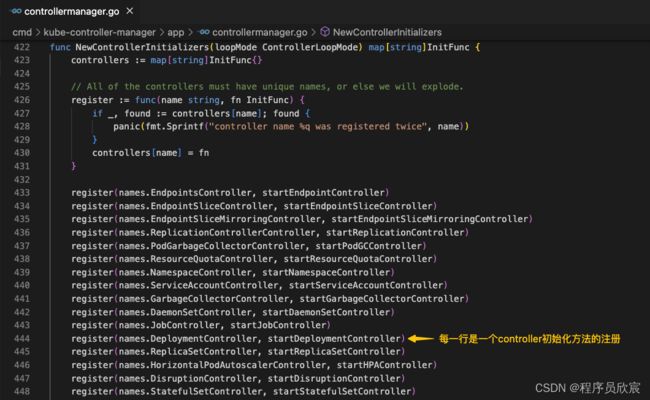
本文是《controller-manager学习三部曲》的终篇,前面咱们从启动到运行已经分析了controller-manager的详细工作,对controller-manager有了详细了解,也知道controller-manager最重要的任务是调用各controller的初始化方法,使它们进入正常的工作状态,也就是下面代码的黄色箭头位置

-
这些初始化方法又是哪来的呢?不得不再次提到前文多次遇到的NewControllerInitializers方法,这里面有所有controller的初始化方法
-
现在问题来了:controller有这么多,它们的初始化到底做了些什么?
-
篇幅所限,自然不可能把每个controller的初始化方法都看一遍,所以咱们还是挑一个典型的来看看吧,就选deployment的controller,也就是上图黄色箭头指向的那行
register(names.DeploymentController, startDeploymentController)
- 不过在正式阅读deployment的controller启动代码之前,先巩固一下基础,弄清楚register方法是什么
register方法
- 所有controller都要通过register方法注册,所以这个register有必要了解一下
// controllers是个map,key就是controller的名称了,value是初始化方法
controllers := map[string]InitFunc{}
// register在此定义
register := func(name string, fn InitFunc) {
// 同一个key不能注册多次
if _, found := controllers[name]; found {
panic(fmt.Sprintf("controller name %q was registered twice", name))
}
controllers[name] = fn
}
- 作为value的InitFunc也非常重要,它对初始化方法的入参和返回值做了定义,保证了一致性
type InitFunc func(ctx context.Context, controllerCtx ControllerContext) (controller controller.Interface, enabled bool, err error)
- InitFunc会在StartControllers方法中被执行,每个InitFunc执行结束意味着对应controller初始化完成,来看看它的三个返回值
| 返回值 | 说明 |
|---|---|
| controller | 创建的controller对象,这是个接口定义,只要求实现Name方法 |
| enabled | 用于描述创建的controller对象是否可用,如果可用就会做健康检查相关的判断和注册工作 |
| err | 如果创建过程有错误发生就在此返回,此err一旦不为空就会导致整个controller-manager进程退出 |
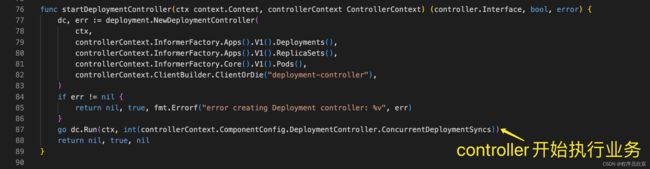
- 现在准备工作算是完成了,该研究deployment的启动代码了,也就是startDeploymentController方法
且看deployment的controller是如何创建的
- 如果您看过欣宸之前的《client-go实战》系列,应该对自定义controller的套路非常熟悉,主要是下面这几件事情
- 创建队列,并指定处理队列数据的方法
- 监听指定类型的资源,待其发生变化的时候将其放入队列,由前面指定的方法来做具体的处理
- 正因为熟悉了这个套路,才可以提前猜测deployment的controller做的也是这些事情,然后再来验证猜测
- startDeploymentController方法的源码很简单,先创建对象再调用Run方法启动业务处理逻辑,要注意的是NewDeploymentController的入参,有deployment、replicaset、pod等三种Informer,所以controller会监听这三种资源的变更,然后还有个client在请求api-server时会用到
func startDeploymentController(ctx context.Context, controllerContext ControllerContext) (controller.Interface, bool, error) {
// 实例化对象
dc, err := deployment.NewDeploymentController(
ctx,
controllerContext.InformerFactory.Apps().V1().Deployments(),
controllerContext.InformerFactory.Apps().V1().ReplicaSets(),
controllerContext.InformerFactory.Core().V1().Pods(),
controllerContext.ClientBuilder.ClientOrDie("deployment-controller"),
)
if err != nil {
return nil, true, fmt.Errorf("error creating Deployment controller: %v", err)
}
go dc.Run(ctx, int(controllerContext.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs))
return nil, true, nil
}
- 打开方法,看看deployment的controller具体是如何创建的
func NewDeploymentController(ctx context.Context, dInformer appsinformers.DeploymentInformer, rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, client clientset.Interface) (*DeploymentController, error) {
eventBroadcaster := record.NewBroadcaster()
logger := klog.FromContext(ctx)
// 创建deployment的controller对象,注意queue被用来存入要监听的业务变更,然后有对应的processor来处理(这是套路),client也传进去了,里面请求api-server会用到(主要是资源的写操作)
dc := &DeploymentController{
client: client,
eventBroadcaster: eventBroadcaster,
eventRecorder: eventBroadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "deployment-controller"}),
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "deployment"),
}
// rsControl提供PatchReplicaSet方法,可用于ReplicaSet资源的patch操作
dc.rsControl = controller.RealRSControl{
KubeClient: client,
Recorder: dc.eventRecorder,
}
// 监听Deployment资源的变化,增删改都绑定了对应的处理方法
dInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
dc.addDeployment(logger, obj)
},
UpdateFunc: func(oldObj, newObj interface{}) {
dc.updateDeployment(logger, oldObj, newObj)
},
// This will enter the sync loop and no-op, because the deployment has been deleted from the store.
DeleteFunc: func(obj interface{}) {
dc.deleteDeployment(logger, obj)
},
})
// 监听ReplicaSet资源的变化,增删改都绑定了对应的处理方法
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
dc.addReplicaSet(logger, obj)
},
UpdateFunc: func(oldObj, newObj interface{}) {
dc.updateReplicaSet(logger, oldObj, newObj)
},
DeleteFunc: func(obj interface{}) {
dc.deleteReplicaSet(logger, obj)
},
})
// 监听Pod资源的变化,增删改都绑定了对应的处理方法
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
DeleteFunc: func(obj interface{}) {
dc.deletePod(logger, obj)
},
})
// 这是整个controller的核心业务代码,就是收到deployment资源的变化后所做的各种操作
dc.syncHandler = dc.syncDeployment
// 入参是对象,功能是将对象的key放入队列
dc.enqueueDeployment = dc.enqueue
// 这一堆lister都会用在各种查询的场景
dc.dLister = dInformer.Lister()
dc.rsLister = rsInformer.Lister()
dc.podLister = podInformer.Lister()
// 是否已经同步的标志
dc.dListerSynced = dInformer.Informer().HasSynced
dc.rsListerSynced = rsInformer.Informer().HasSynced
dc.podListerSynced = podInformer.Informer().HasSynced
return dc, nil
}
-
在上面的代码中,果然看到了队列queue,这就是连接生产和消费的关键对象,至于dInformer.Informer().AddEventHandler、rsInformer.Informer().AddEventHandler等方面里面的AddFunc、UpdateFunc等,肯定是监听了deployment、pod的变化,然后将key放入deployment中,为了验证这个猜测,咱们挑一个看看,就看ReplicaSet的AddFunc中的(logger, obj)dc.addReplicaSet,果然,这些资源的变化都会导致相关的资源被放入队列queue

-
至此,咱们对deployment的controller创建算是了解了,接下来要了解controller如何运行,也就是下图黄色箭头所指的方法做了些什么,按照套路,这里面要做的就是让queue的生产和消费正常运转起来
-
方法的代码如下
func (dc *DeploymentController) Run(ctx context.Context, workers int) {
defer utilruntime.HandleCrash()
// Start events processing pipeline.
dc.eventBroadcaster.StartStructuredLogging(0)
dc.eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: dc.client.CoreV1().Events("")})
defer dc.eventBroadcaster.Shutdown()
defer dc.queue.ShutDown()
logger := klog.FromContext(ctx)
logger.Info("Starting controller", "controller", "deployment")
defer logger.Info("Shutting down controller", "controller", "deployment")
// 确保本地与api-server的同步已经完成
if !cache.WaitForNamedCacheSync("deployment", ctx.Done(), dc.dListerSynced, dc.rsListerSynced, dc.podListerSynced) {
return
}
// 多个协程并行执行,每个一秒钟执行一次dc.worker方法(其实就是消费queue的业务逻辑)
for i := 0; i < workers; i++ {
go wait.UntilWithContext(ctx, dc.worker, time.Second)
}
<-ctx.Done()
}
- 可见是定时执行dc.worker方法,那就看看这个worker是啥吧,如下所示,其实就是processNextWorkItem,这个咱们在《client-go实战》系列中已经写了太多次了,就是消费queue的业务代码,也是整个controller的核心业务代码
func (dc *DeploymentController) worker(ctx context.Context) {
for dc.processNextWorkItem(ctx) {
}
}
// 这是整个deployment的controller的核心业务逻辑,对deployment资源的变化进行响应
func (dc *DeploymentController) processNextWorkItem(ctx context.Context) bool {
// 从queue中取出对象的key
key, quit := dc.queue.Get()
if quit {
return false
}
defer dc.queue.Done(key)
// 对指定key对应的资源进行处理,也就是此deployment的主要工作
err := dc.syncHandler(ctx, key.(string))
dc.handleErr(ctx, err, key)
return true
}
- 读到这里,不知您是否有一种豁然开朗的感觉:kubernetes规范了queue、生产、消费的模式,并且在自身controller中践行此模式,这就使得开发controller和阅读controller代码都变得更加容易了,甚至在本文章,我也数次尝试在阅读代码前先猜测再验证,结果都和猜测的一致
- 或许您可能会有疑问:代码都分析到这里了,咋不继续读dc.syncHandler的源码,把这个controller搞明白?
- 呃…这里必须要打住了,本文的重点的controller-manager的学习,也就是controller是如何创建和启动的,而并非研究controller的具体业务,所以dc.syncHandler就不展开看了,毕竟每个controller都有自己独特的业务处理逻辑
- 但我相信,现在的您已经可以轻松读懂dc.syncHandler,从而彻底掌握deployment的controller了,毕竟咱们一起经历了太多的套路,对这套逻辑已经熟悉
- 至此,《controller-manager学习三部曲》就已经完成了,希望这个系列能够帮您梳理和熟悉kubernetes的controller管理和启动逻辑,让您能开发出更加契合原生kubernetes系统的controller
你不孤单,欣宸原创一路相伴
- Java系列
- Spring系列
- Docker系列
- kubernetes系列
- 数据库+中间件系列
- DevOps系列