ERNIE实现酒店情感分析(文本分类)
ERNIE实现酒店情感分析(文本分类)
引言
在自然语言处理(NLP)领域,文本分类是一项重要的任务,它能够帮助我们理解和分析大量的文本数据。随着深度学习技术的发展,预训练模型成为了处理文本分类任务的重要工具。本项目将介绍如何利用PaddleHub和预训练模型ERNIE来完成酒店情感分析,即对酒店评论进行积极或消极的分类。
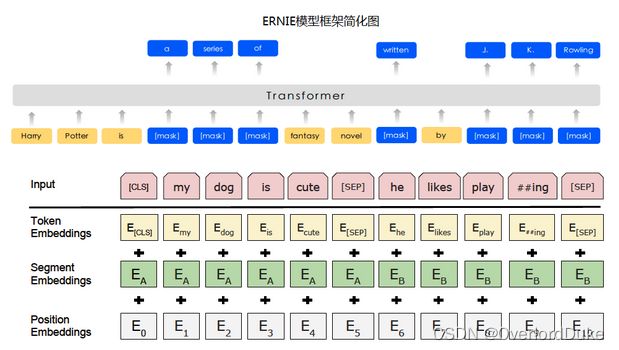
项目背景与意义
在过去,NLP文本处理主要依赖于序列模型,如循环神经网络(RNN)。然而,随着深度学习的发展,模型参数数量急剧增加,为了训练这些参数,需要更大规模的数据集来避免过拟合。但是构建大规模标注数据集的成本很高,尤其是对于句法和语义相关的任务而言。相比之下,构建大规模未标注语料库相对容易。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM)能够习得通用的语言表示,并且通过Fine-tune到特定任务上,可以获得出色的表现,同时也避免了从零开始训练模型的麻烦。
准备工作
首先,我们需要安装并导入必要的Python包,具体如下:
!pip install -U paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
import paddlehub as hub
import paddle
代码步骤
Step 1: 选择模型
我们选择了ERNIE预训练模型,并使用PaddleHub提供的Fine-tune API进行文本分类任务的模型选择和初始化。
model = hub.Module(name="ernie_tiny", task='seq-cls', num_classes=2)
在这里,我们使用了ERNIE Tiny模型,并指定了文本分类任务以及类别数为2,即积极和消极情感。
Step 2: 加载自定义数据集
我们使用了一个较大规模的、去重后的非平衡酒店评论情感语料作为示例数据集。首先,我们加载和预览了数据集,然后进行了数据清洗和标签分布的分析。
Step 3: 选择优化策略和运行配置
我们选择了Adam优化器,并配置了训练器的参数,包括使用GPU进行训练等。
optimizer = paddle.optimizer.Adam(learning_rate=5e-5, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir='./ckpt', use_gpu=True)
Step 4: 执行fine-tune并评估模型
我们使用训练器进行模型的Fine-tune,并在验证集上评估模型的性能。
trainer.train(train_dataset, epochs=3, batch_size=32, eval_dataset=dev_dataset, save_interval=1)
result = trainer.evaluate(test_dataset, batch_size=32)
使用模型进行预测
在Fine-tune完成后,我们可以加载训练保存的最佳模型,并利用该模型对新的文本进行情感分析的预测。
data = [
["房间比较干净,但是窗户打不开,空气不太好。早餐很好。总体不错。"],
["绝对是超三星标准,地处商业区,购物还是很方便的,对门有家羊杂店,绝对正宗。除了价格稍贵,总体还是很满意的"],
["1房间很小,地毯很脏,白毛巾显黑色2中央空调有异响,后半夜只好关掉3洗澡水忽冷忽热"],
["房间设施还可以,但酒店内非常的冷,冬天不推荐入住。"]
]
results = model.predict(data, max_seq_len=128, batch_size=1, use_gpu=True)
for idx, text in enumerate(data):
print('Data: {} \t Label: {}'.format(text[0], results[idx]))
通过以上步骤,我们完成了基于ERNIE预训练模型的酒店情感分析任务,实现了对酒店评论的情感分类,为进一步的文本分析提供了可靠的基础。
结语
本项目展示了如何利用PaddleHub和预训练模型ERNIE进行酒店评论情感分析的文本分类任务。通过预训练模型和Fine-tune技术,我们能够快速构建并训练出针对特定任务的高性能文本分类模型,为各种NLP应用提供了强大的支持。希望本项目能对您有所帮助,谢谢阅读!