图像分类——基于pytorch的农作物病虫害检测
作为视觉基础任务的图像分类是大多数深度学习入门者的基础,本文将用包含33类的农作物病虫害数据集作为数据集,来过一遍图像分类任务的基本步骤。

一、引入库
import os
import torch
import numpy as np
from PIL import Image
import torch.nn as nn
import torch.optim as optim
from torchvision import utils
from collections import Counter
import matplotlib.pyplot as plt
from torchvision import transforms
from torch.utils.data import Dataset
其中,os模块用来处理文件和目录,numpy用来提供高性能的多维数组对象和这些数组上的各种操作,torch提供了强大的张量操作能力,以及自动求导系统来方便地进行深度学习模型的训练,PIL提供了打开、操作以及保存许多不同格式的图像文件的能力,torchvision包含了处理图像的方法和模型,例如预训练模型、图像转换操作等,collections提供了许多有用的数据结构和算法来处理集合数据,matplotlib用来展示数据的分布、趋势以及与其他变量之间的关系。
二、定义超参数
1.数据预处理和增强相关的超参数
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
transform_train = transforms.Compose([
transforms.RandomRotation(degrees=(-30, 30)),
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1), scale=(0.8, 1.2)),
transforms.RandomResizedCrop(size=256, scale=(0.6, 1.0)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
])
transform_val = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
])(1)训练数据变换 (transform_train)
-
RandomRotation(degrees=(-30, 30)):- 随机旋转图像,在给定的度数范围内(-30到30度)。
-
RandomAffine(degrees=0, translate=(0.1, 0.1), scale=(0.8, 1.2)):- 进行随机仿射变换。在这里,
degrees=0表示不进行旋转,translate=(0.1, 0.1)允许图像在垂直和水平方向上最多移动图像宽高的10%,scale=(0.8, 1.2)表示图像大小缩放的范围。
- 进行随机仿射变换。在这里,
-
RandomResizedCrop(size=256, scale=(0.6, 1.0)):- 随机大小裁剪图像。首先按照给定的比例(0.6到1.0之间)选取图像的一部分,然后将其缩放到256x256像素。
-
ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2):- 随机调整图像的亮度、对比度和饱和度。这些参数的范围是±20%。
-
RandomHorizontalFlip():- 以50%的概率水平翻转图像。
-
ToTensor():- 将PIL图像或NumPy
ndarray转换为torch.Tensor。这一步通常是必须的,因为PyTorch模型期望输入为张量。
- 将PIL图像或NumPy
-
Normalize(mean=mean, std=std):- 标准化图像。使用给定的均值(
mean)和标准差(std)对每个颜色通道进行标准化。这有助于加速训练并提高模型收敛速度。
- 标准化图像。使用给定的均值(
(2)验证集数据变换 (transform_val)
-
Resize(256):- 将图像大小调整为256x256像素。
-
CenterCrop(224):- 从图像中心裁剪出224x224像素的区域。
-
ToTensor():- 同上,将图像转换为张量。
-
Normalize(mean=mean, std=std):- 同上,标准化图像。
2.训练过程相关的超参数
counter = 0
patience = 3
num_epochs = 10
batch_size = 32
best_test_acc = 0.0
learning_rate = 0.001
criterion = nn.CrossEntropyLoss()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')-
num_epochs = 10:- 这指定了训练过程中整个数据集将被遍历的次数。在这里,您设置了10个训练周期(epochs)。每个epoch结束时,模型会看到整个训练集一次。
-
batch_size = 32:- 在训练过程中,数据将被分成大小为32的小批量(batches)。这意味着模型权重的更新将基于这32个样本的平均损失进行。
-
learning_rate = 0.001:- 学习率是优化过程中用于调整模型权重的步长。较小的学习率意味着权重调整的步幅更小,可能导致训练过程更平滑但需要更多时间收敛。0.001是一个常用的学习率起点。
-
criterion = nn.CrossEntropyLoss():- 这定义了损失函数,即模型预测与真实标签之间差异的度量方式。交叉熵损失是分类任务中常用的损失函数,特别适用于多类分类问题。
-
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate):- 这里选择了Adam优化器,并将其与模型的参数和学习率相关联。Adam是一种自适应学习率优化算法,它结合了RMSprop和Momentum两种优化算法的优点,通常在许多不同的机器学习任务中表现良好。
-
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[int(num_epochs * 0.5), int(num_epochs * 0.75)], gamma=0.1):- 这定义了一个学习率调度器,用于在训练过程中调整学习率。
MultiStepLR根据给定的里程碑(milestones)降低学习率,这里的设置是在训练过程达到总epoch数的50%和75%时,将学习率乘以0.1(即减少90%)。这有助于在训练后期细化模型权重,可能会提高模型的最终性能。
- 这定义了一个学习率调度器,用于在训练过程中调整学习率。
三、定义数据集加载方式
1.标签数值化与数字索引标签化
class_to_idx = {
'Background_without_leaves': 0,
'Blueberry___healthy': 1,
'Cherry___Powdery_mildew':2,
'Cherry___healthy': 3,
'Corn___Cercospora_leaf_spot Gray_leaf_spot':4,
'Corn___Common_rust':5,
'Corn___Northern_Leaf_Blight':6,
'Corn___healthy':7,
'Grape___Black_rot':8,
'Grape___Esca_(Black_Measles)':9,
'Orange___Haunglongbing_(Citrus_greening)':10,
'Peach___Bacterial_spot':11,
'Peach___healthy':12,
'Pepper,_bell___Bacterial_spot':13,
'Pepper,_bell___healthy':14,
'Potato___Early_blight':15,
'Potato___Late_blight':16,
'Potato___healthy':17,
'Raspberry___healthy':18,
'Soybean___healthy':19,
'Squash___Powdery_mildew':20,
'Strawberry___Leaf_scorch':21,
'Strawberry___healthy':22,
'Tomato___Bacterial_spot':23,
'Tomato___Early_blight':24,
'Tomato___Late_blight':25,
'Tomato___Leaf_Mold':26,
'Tomato___Septoria_leaf_spot':27,
'Tomato___Spider_mites Two-spotted_spider_mite':28,
'Tomato___Target_Spot':29,
'Tomato___Tomato_Yellow_Leaf_Curl_Virus':30
'Tomato___Tomato_mosaic_virus':31,
'Tomato___healthy':32,
}2.数据集载入
class MyDataset(Dataset):
def __init__(self, root_dir, transform=None, mode='train'):
self.root_dir = root_dir
self.transform = transform
self.mode = mode
self.class_names = sorted(os.listdir(os.path.join(root_dir, self.mode)))
self.class_to_idx = {class_name: idx for idx, class_name in enumerate(self.class_names)}
self.data = []
for class_name in self.class_names:
class_dir = os.path.join(root_dir, self.mode, class_name)
for image_name in os.listdir(class_dir):
image_path = os.path.join(class_dir, image_name)
self.data.append((image_path, class_name))
def __len__(self):
return len(self.data)
def __getitem__(self, index):
image_path, class_name = self.data[index]
image = Image.open(image_path).convert('RGB')
if self.transform is not None:
image = self.transform(image)
label = self.class_to_idx[class_name]
return image, label其中,文件夹的层次结构如下:
bch_33/
│
├── train/
│ ├── class_1/
│ │ ├── img1.jpg
│ │ ├── img2.jpg
│ │ └── ...
│ ├── class_2/
│ │ ├── img1.jpg
│ │ ├── img2.jpg
│ │ └── ...
│
└── val/
├── class_1/
│ ├── img1.jpg
│ ├── img2.jpg
│ └── ...
├── class_2/
│ ├── img1.jpg
│ ├── img2.jpg
│ └── ...
└── ...
四、载入数据集
root_dir = "bch_33"
train_dataset = MyDataset(root_dir=root_dir, transform=transform_train, mode='train')
val_dataset = MyDataset(root_dir=root_dir, transform=transform_test, mode='val')
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)-
创建数据集实例:
train_dataset = MyDataset(root_dir=root_dir, transform=transform_train, mode='train')- 创建一个训练数据集实例,指向根目录
"bch_33"下的train目录,并应用transform_train预处理。
- 创建一个训练数据集实例,指向根目录
val_dataset = MyDataset(root_dir=root_dir, transform=transform_test, mode='val')- 创建一个验证数据集实例,指向根目录
"bch_33"下的val目录,并应用transform_test预处理。
- 创建一个验证数据集实例,指向根目录
-
创建数据加载器:
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)- 训练数据集创建一个数据加载器,设置了批量大小
batch_size(之前定义的变量),并启用了随机打乱数据的选项shuffle=True,以便于训练过程中提高模型的泛化能力。
- 训练数据集创建一个数据加载器,设置了批量大小
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)- 验证数据集创建一个数据加载器,设置了相同的批量大小但禁用了数据打乱(
shuffle=False),因为在验证或测试阶段,保持数据顺序通常更有助于结果的一致性和分析。
- 验证数据集创建一个数据加载器,设置了相同的批量大小但禁用了数据打乱(
五、检验载入的数据
1.检查数据维度
首先,确保从数据加载器中获取的数据批次具有正确的维度。对于图像数据,一个批次的数据通常具有形状 [batch_size, channels, height, width]。
for images, labels in train_loader:
print(f"Batch shape: {images.size()}")
print(f"Labels: {labels}")
break # 这里只检查第一个批次,所以使用break退出循环
2.可视化数据样本
将数据集中的一些图像可视化出来,可以直观地验证数据是否被正确加载和处理。
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(train_loader)
images, labels = dataiter.next()
imshow(utils.make_grid(images))
print(' '.join(f'{labels[j]}' for j in range(batch_size)))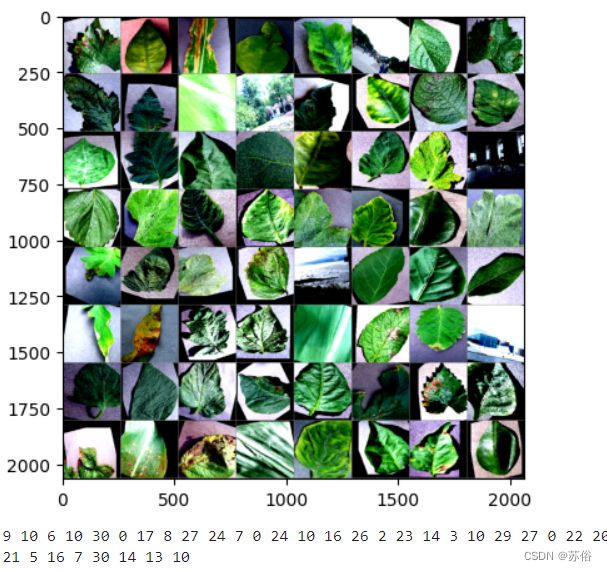
3.检查标签分布
检查训练和验证数据集的标签分布是否均衡。
def check_label_distribution(loader):
all_labels = []
for _, labels in loader:
all_labels.extend(labels.tolist())
label_counter = Counter(all_labels)
return label_counter
train_label_distribution = check_label_distribution(train_loader)
val_label_distribution = check_label_distribution(val_loader)
print("Training set label distribution:", train_label_distribution)
print("Validation set label distribution:", val_label_distribution)
六、定义模型结构并实例化
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, num_classes=33):
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(64, 64, 3)
self.layer2 = self._make_layer(256, 128, 4, stride=2)
self.layer3 = self._make_layer(512, 256, 6, stride=2)
self.layer4 = self._make_layer(1024, 512, 3, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=0.5)
self.fc = nn.Linear(512 * Bottleneck.expansion, num_classes)
def _make_layer(self, inplanes, planes, blocks, stride=1):
downsample = None
if stride != 1 or inplanes != planes * Bottleneck.expansion:
downsample = nn.Sequential(
nn.Conv2d(inplanes, planes * Bottleneck.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * Bottleneck.expansion),
)
layers = []
layers.append(Bottleneck(inplanes, planes, stride, downsample))
inplanes = planes * Bottleneck.expansion
for _ in range(1, blocks):
layers.append(Bottleneck(inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = self.fc(x)
return x
model = ResNet()
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[int(num_epochs * 0.5), int(num_epochs * 0.75)], gamma=0.1)七、检验模型的输出情况
test_input= torch.rand((32, 3, 224, 224)).to(device)
print(test_input.shape)
test_output = model(test_input)
test_output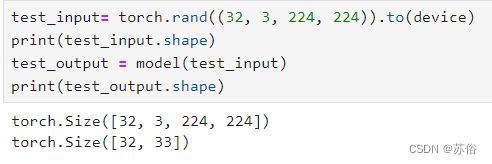
八、加载之前训练的模型参数(没有就不用)
model.load_state_dict(torch.load('path/to/your/trained/model.pth'))换成自己本地的真实路径。
九、训练模型且保存训练过程
torch.manual_seed(1)
train_losses = []
train_accuracies = []
val_accuracies = []
for epoch in range(10):
print(f"正在训练第{epoch+1}批次数据:")
train_accuracy_total = 0
train_correct = 0
train_loss = 0
model.train()
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
outputs = model.forward(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicts = torch.max(outputs.data, 1)
train_accuracy_total += labels.size(0)
train_correct += (predicts == labels).sum().item()
train_loss /= len(train_loader)
train_accuracy = train_correct / train_accuracy_total
train_losses.append(train_loss)
train_accuracies.append(train_accuracy)
val_acc = evaluate_acc(val_loader, model)
val_accuracies.append(val)
print(f"第{epoch+1}次的损失函数值为{train_loss}, 训练集上的准确率为{train_accuracy}, 验证集上的准确率为{val_acc}")
if val_acc > best_val_acc:
best_val_acc = val_acc
counter = 0
torch.save(model.state_dict(), 'path/to/save/model.pth') # 定期保存模型参数
else:
counter += 1
if counter >= patience:
print("早停:没有进一步提升测试集准确率")
break
scheduler.step()
十、可视化训练过程并评估模型性能
plt.plot(range(1, len(train_losses)+1), train_losses, label='Train Loss')
plt.plot(range(1, len(train_accuracies)+1), train_accuracies, label='Train Accuracy')
plt.plot(range(1, len(val_accuracies)+1), val_accuracies, label='Val Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Value')
plt.legend()
plt.show()
print("训练完成")可视化的结果如下:
 十一、定义预测函数进行预测
十一、定义预测函数进行预测
def predict(image_path):
image = Image.open(image_path)
image_array = np.array(image)
img = transform_val(image).to(device)
image = img.unsqueeze(0)
# english_to_chinese_dict = dict(zip(class_names_english, class_names_chinese))
with torch.no_grad():
output = model(image)
probabilities = torch.softmax(output, dim=1)
max_prob, predicted_class = torch.max(probabilities, dim=1)
if max_prob < 0.5:
return f"图片错误,最大概率为: {max_prob.item()}"
else:
class_index = predicted_class.item()
class_label_english = list(class_to_idx.keys())[list(class_to_idx.values()).index(class_index)]
# class_label_chinese = english_to_chinese_dict.get(class_label_english, class_label_english)
return f"类别结果: {class_index,class_label_english}, 概率: {max_prob.item()}"
img = r"path/to/img.JPG"
output = predict(img)
output![]()
全部的代码如下:
import os
import torch
import numpy as np
from PIL import Image
import torch.nn as nn
import torch.optim as optim
from torchvision import utils
from collections import Counter
import matplotlib.pyplot as plt
from torchvision import transforms
from torch.utils.data import Dataset
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
transform_train = transforms.Compose([
transforms.RandomRotation(degrees=(-30, 30)),
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1), scale=(0.8, 1.2)),
transforms.RandomResizedCrop(size=256, scale=(0.6, 1.0)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
])
transform_val = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
])
num_epochs = 10
batch_size = 32
learning_rate = 0.001
best_val_acc = 0.0
patience = 3
counter = 0
class_to_idx = {
'Background_without_leaves': 0,
'Blueberry___healthy': 1,
'Cherry___healthy': 3,
'Cherry___Powdery_mildew':2,
'Corn___Cercospora_leaf_spot Gray_leaf_spot':4,
'Corn___Common_rust':5,
'Corn___healthy':7,
'Corn___Northern_Leaf_Blight':6,
'Grape___Black_rot':8,
'Grape___Esca_(Black_Measles)':9,
'Orange___Haunglongbing_(Citrus_greening)':10,
'Peach___Bacterial_spot':11,
'Peach___healthy':12,
'Pepper,_bell___Bacterial_spot':13,
'Pepper,_bell___healthy':14,
'Potato___Early_blight':15,
'Potato___healthy':17,
'Potato___Late_blight':16,
'Raspberry___healthy':18,
'Soybean___healthy':19,
'Squash___Powdery_mildew':20,
'Strawberry___healthy':22,
'Strawberry___Leaf_scorch':21,
'Tomato___Bacterial_spot':23,
'Tomato___Early_blight':24,
'Tomato___healthy':32,
'Tomato___Late_blight':25,
'Tomato___Leaf_Mold':26,
'Tomato___Septoria_leaf_spot':27,
'Tomato___Spider_mites Two-spotted_spider_mite':28,
'Tomato___Target_Spot':29,
'Tomato___Tomato_mosaic_virus':31,
'Tomato___Tomato_Yellow_Leaf_Curl_Virus':30
}
class_names_english = [
'Background_without_leaves',
'Blueberry___healthy',
'Cherry___healthy',
'Cherry___Powdery_mildew',
'Corn___Cercospora_leaf_spot Gray_leaf_spot',
'Corn___Common_rust',
'Corn___healthy',
'Corn___Northern_Leaf_Blight',
'Grape___Black_rot',
'Grape___Esca_(Black_Measles)',
'Orange___Haunglongbing_(Citrus_greening)',
'Peach___Bacterial_spot',
'Peach___healthy',
'Pepper,_bell___Bacterial_spot',
'Pepper,_bell___healthy',
'Potato___Early_blight',
'Potato___healthy',
'Potato___Late_blight',
'Raspberry___healthy',
'Soybean___healthy',
'Squash___Powdery_mildew',
'Strawberry___healthy',
'Strawberry___Leaf_scorch',
'Tomato___Bacterial_spot',
'Tomato___Early_blight',
'Tomato___healthy',
'Tomato___Late_blight',
'Tomato___Leaf_Mold',
'Tomato___Septoria_leaf_spot',
'Tomato___Spider_mites Two-spotted_spider_mite',
'Tomato___Target_Spot',
'Tomato___Tomato_mosaic_virus',
'Tomato___Tomato_Yellow_Leaf_Curl_Virus'
]
class_names_chinese = [
'无叶--背景',
'蓝莓--健康',
'樱桃--健康',
'樱桃--白粉病',
'玉米--黄斑病和灰斑病',
'玉米--锈病',
'玉米--健康',
'玉米--灰斑病',
'葡萄--黑腐病',
'葡萄--黑斑病',
'柑橘--黄龙病',
'桃--细菌性斑点病',
'桃--健康',
'甜椒--细菌性斑点病',
'甜椒--健康',
'马铃薯--早疫病',
'马铃薯--健康',
'马铃薯--晚疫病',
'树莓--健康',
'大豆--健康',
'南瓜--白粉病',
'草莓--健康',
'草莓--叶枯病',
'番茄--细菌性斑点病',
'番茄--早疫病',
'番茄--健康',
'番茄--晚疫病',
'番茄--叶霉病',
'番茄--斑点病',
'番茄--蜘蛛螨病',
'番茄--病毒性斑点病',
'番茄--花叶病毒',
'番茄--黄化曲叶病毒'
]
class CustomDataset(Dataset):
def __init__(self, root_dir, transform=None, mode='train'):
self.root_dir = root_dir
self.transform = transform
self.mode = mode
self.class_names = sorted(os.listdir(os.path.join(root_dir, self.mode)))
self.class_to_idx = {class_name: idx for idx, class_name in enumerate(self.class_names)}
self.data = []
for class_name in self.class_names:
class_dir = os.path.join(root_dir, self.mode, class_name)
for image_name in os.listdir(class_dir):
image_path = os.path.join(class_dir, image_name)
self.data.append((image_path, class_name))
def __len__(self):
return len(self.data)
def __getitem__(self, index):
image_path, class_name = self.data[index]
image = Image.open(image_path).convert('RGB')
if self.transform is not None:
image = self.transform(image)
label = self.class_to_idx[class_name]
return image, label
from torchvision import transforms
from torch.utils.data import DataLoader
root_dir = r"D:\desktop\com\软赛\rs-病虫害检测\new_data\bch_33"
train_dataset = CustomDataset(root_dir=root_dir, transform=transform_train, mode='train')
val_dataset = CustomDataset(root_dir=root_dir, transform=transform_val, mode='test')
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
for images, labels in train_loader:
print(f"Batch shape: {images.size()}")
print(f"Labels: {labels}")
break
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(train_loader)
images, labels = dataiter.next()
imshow(utils.make_grid(images))
print(' '.join(f'{labels[j]}' for j in range(batch_size)))
def check_label_distribution(loader):
all_labels = []
for _, labels in loader:
all_labels.extend(labels.tolist())
label_counter = Counter(all_labels)
return label_counter
train_label_distribution = check_label_distribution(train_loader)
val_label_distribution = check_label_distribution(val_loader)
print("Training set label distribution:", train_label_distribution)
print("Validation set label distribution:", val_label_distribution)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, num_classes=33):
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(64, 64, 3)
self.layer2 = self._make_layer(256, 128, 4, stride=2)
self.layer3 = self._make_layer(512, 256, 6, stride=2)
self.layer4 = self._make_layer(1024, 512, 3, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=0.5)
self.fc = nn.Linear(512 * Bottleneck.expansion, num_classes)
def _make_layer(self, inplanes, planes, blocks, stride=1):
downsample = None
if stride != 1 or inplanes != planes * Bottleneck.expansion:
downsample = nn.Sequential(
nn.Conv2d(inplanes, planes * Bottleneck.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * Bottleneck.expansion),
)
layers = []
layers.append(Bottleneck(inplanes, planes, stride, downsample))
inplanes = planes * Bottleneck.expansion
for _ in range(1, blocks):
layers.append(Bottleneck(inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
# print(x.shape)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
# print(x.shape)
x = self.layer2(x)
# print(x.shape)
x = self.layer3(x)
# print(x.shape)
x = self.layer4(x)
# print(x.shape)
x = self.avgpool(x)
# print(x.shape)
x = x.view(x.size(0), -1)
# print(x.shape)
x = self.dropout(x)
# print(x.shape)
x = self.fc(x)
# print(x.shape)
return x
learning_rate=0.0001
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ResNet()
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate) #选择优化器
num_epochs=10
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[int(num_epochs * 0.5), int(num_epochs * 0.75)], gamma=0.1)
test_input= torch.rand((32, 3, 224, 224)).to(device)
print(test_input.shape)
test_output = model(test_input)
print(test_output.shape)
model = ResNet(num_classes=33)
model.load_state_dict(torch.load('path/to/your/trained/model.pth'))
def evaluate_acc(test_loader, model):
model.eval()
test_correct = 0.0
test_total = 0.0
with torch.no_grad():
for i,(images,labels) in enumerate(test_loader):
inputs, labels = images.to(device),labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
test_accuracy = test_correct / test_total
return test_accuracy
torch.manual_seed(1)
train_losses = []
train_accuracies = []
val_accuracies = []
for epoch in range(10):
print(f"正在训练第{epoch + 1}批次数据:")
train_accuracy_total = 0
train_correct = 0
train_loss = 0
model.train()
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
outputs = model.forward(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicts = torch.max(outputs.data, 1)
train_accuracy_total += labels.size(0)
train_correct += (predicts == labels).sum().item()
train_loss /= len(train_loader)
train_accuracy = train_correct / train_accuracy_total
train_losses.append(train_loss)
train_accuracies.append(train_accuracy)
val_acc = evaluate_acc(val_loader, model)
val_accuracies.append(val_acc)
print(f"第{epoch + 1}次的损失函数值为{train_loss}, 训练集上的准确率为{train_accuracy}, 验证集上的准确率为{val_acc}")
if val_acc > best_val_acc:
best_val_acc = val_acc
counter = 0
torch.save(model.state_dict(), './bch.pth') # 定期保存模型参数
else:
counter += 1
if counter >= patience:
print("早停:没有进一步提升测试集准确率")
break
scheduler.step()
plt.plot(range(1, len(train_losses) + 1), train_losses, label='Train Loss')
plt.plot(range(1, len(train_accuracies) + 1), train_accuracies, label='Train Accuracy')
plt.plot(range(1, len(val_accuracies) + 1), val_accuracies, label='Val Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Value')
plt.legend()
plt.show()
print("训练完成")
def predict(image_path):
image = Image.open(image_path)
image_array = np.array(image)
img = transform_val(image).to(device)
image = img.unsqueeze(0)
english_to_chinese_dict = dict(zip(class_names_english, class_names_chinese))
with torch.no_grad():
output = model(image)
probabilities = torch.softmax(output, dim=1)
max_prob, predicted_class = torch.max(probabilities, dim=1)
if max_prob < 0.5:
return f"图片错误,最大概率为: {max_prob.item()}"
else:
class_index = predicted_class.item()
class_label_english = list(class_to_idx.keys())[list(class_to_idx.values()).index(class_index)]
class_label_chinese = english_to_chinese_dict.get(class_label_english, class_label_english)
return f"类别结果: {class_index,class_label_english}, 概率: {max_prob.item()}"
img = r"D:\desktop\com\软赛\rs-病虫害检测\new_data\bch_33\test\Blueberry___healthy\image (5).JPG"
output = predict(img)
print(output)