Linux->文件系统初识
目录
前言:
1 认识文件
2 文件使用
2.1 文件加载
2.2 外设文件使用
3 文件接口和文件描述符
3.1 文件系统调用接口
open:
3.2 文件描述符
4 缓冲区
前言:
在大家看这篇文章之前,我得提出几个问题:
1. 我们有多种对于文件的操作方式,不同的语言有不同的方式,但是对于我们的操作系统来说,它真的认识这么多语言提供的方式吗?
2. 操作文件时,都需要打开文件,但为什么打开文件?
3. 文件在操作时,文件处在什么位置?
4. 当系统中存在大量的被打开的文件,应该如何管理?
1 认识文件
所谓对于文件的操作究其本质,其实它并不关于任何一门语言,而是所有的语言都尊崇同样的接口,并且对这些接口封装,从而实现我们看到了语言的各种各样的不同的文件操作方式。这些操作在后方为大家介绍。
文件本身就是内容加上属性,所以对于文件的操作就是对于内容的操作和对其属性的操作,当我们没有使用文件时,它是安静的呆在磁盘当中。一旦我们对文件操作时,他就会从磁盘加载到内存当中,这一点相信大家了解冯诺依曼体系一定能明白。
我们在对文件进行操作的时候,文件需要内加载到内存当中,但是是否只有我们一个人在使用呢?也就是这个文件是否有多个人在对其进行打开操作?答案肯定是不可能只有一个人也就是一个进程在使用的,因为就连我们平时操作Linux时,我都能对一个文件进行多次打开。而且我在一个程序当中是可以打开多个文件的,那么我们可以得到一个结论:进程和文件的对应关系是1:n。
并且,在Liunx下,一切皆文件。
综上,系统会打开多个进程,而一个进程又会操作多个文件,那么系统中会充斥非常多的文件,这些文件是如何被管理的呢?下面就会讲解文件的加载过程和文件的管理操作。
2 文件使用
2.1 文件加载
首先,我们了解文件在没有被操作时是呆在磁盘当中的,只有在被调度时才会从磁盘加载到内存当中,然后呢?如果所有文件的操作都是到这里就戛然而止了,那么内存当中必然到处都是乱七八糟的文件,此时就必须得有一个管理的操作。
看到管理大家必须的像是触发了关键词一样,那就是先描述,再组织。没错操作系统对于文件的管理如同进程管理那般,都是先描述再组织,那么它同样是有自己抽象出来的结构体用于装载自己的信息。
struct file
{//属性
//各种链接关系
}
看到我们结构体当中存有的数据是属性和各种链接关系,那么证明了什么?也就是说我们的文件内容与我们的管理并没有太多的关系,那么我们就让他乖乖的呆在内存当中,甚至在刚准备打开文件的时候只需要将文件的各种属性告知操作系统都行,内容慢慢的加载。
文件是由操作系统打开的,但是是我们也就是进程让操作系统打开的,那么这样我们的对于文件的操作也就变为了进程与文件的操作。
在系统当中,进程和文件都是被组织起来的数据结构,那么他们之间的交互就变成了两个结构体的操作------struct tast_struct和struct file。
所以整个文件加载到内存当中的过程就如下图:
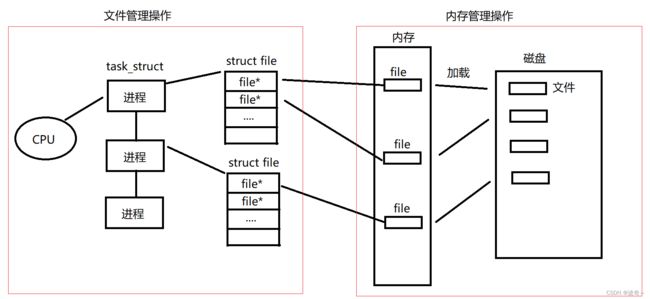
相信看到了这一张图大家是能够将我前面所讲的内容联系起来的,当然真实的图比我这要复杂很多。这里我们将文件管理和内存管理分开来看,文件结构体里面只存有文件在内存当中的地址,也就是整个文件管理和内存管理的关系只有这样的联系,并且这个联系是随时能够被更改的。具体如何更改呢?我之后讲解。那么这样做之后有什么好处呢?实现了文件管理和内存管理的解耦操作,也就是两者都互相并不关心彼此是如何操作的,彼此都只需要一个固定的方式进行交互。
2.2 外设文件使用
操作系统想要显示内容到显示器上面,或者想要获取键盘上的信息从本质而言都是对于文件的操作,但是这样想是否有一些抽象?它怎么就能使用外设文件的信息,它是怎么搞的?但是我们可以换一个角度去想象我们的外设,如果外设是一个进程代码呢?那么它里面是不是就有了什么?代码,而代码里面有什么?函数,也就是每一个外设都是有提供自己的操作方式的,例如键盘就会有一个输入内容的操作方式,显示器就有显示内容的操作方式。
那么因为是一个函数,我们就可以做一件什么事情呢?那就是调用这个函数实现对应的功能,不过说起来简单,具体应该怎么操作呢?如下图:

请问,我们在file结构体当中定义了一个什么样的变量?函数指针,我们都知道Linux是用C语言写的,而C语言不支持在结构体里面写成员函数,所以操作系统也不会支持写成员函数,但是函数的什么是可以写在结构体当中的呢?那就是函数指针,只要有了函数指针找到对应的函数还不简单?
那么上图也就表示了,任何一个外设都有属于自己的文件,并且每一个文件都被抽象成为了一个结构体,所有信息都被记录了起来,通过函数指针调用外设本身为我们提供的操作函数。这样做就能实现对所有不同的外设做出统一的管理执行方式了。要问如果外设不按照这个规则来写呢?那我之只能说那是外设的问题,不是系统的问题。
至于上面为什么键盘只有读函数,显示器只有写函数的原因,也不是这两个没有对应的写和读函数,只是都被置位空了,调用了没有任何意义,我们总不能从键盘上写信息吧,难道让它的某个按键跳起来打人?这也太奇怪了。
3 文件接口和文件描述符
3.1 文件系统调用接口
博主在最开始的时候就已经为大家声明了,任何语言对于文件的操作都源自于封装系统给我们提供的系统调用函数,那么函数有哪些呢?
- fcntl 文件控制
- open 打开文件
- creat 创建新文件
- close 关闭文件描述字
- read 读文件
- write 写文件
- readv 从文件读入数据到缓冲数组中
- writev 将缓冲数组里的数据写入文件
- pread 对文件随机读
- pwrite 对文件随机写
博主这里也就主要使用open、close、write、read函数,主要是想要让大家了解这些接口的操作方式。
open:

文件系统调用的所有接口都在这三个文件当中,重点讲解的是它的参数,第一个参数const char* pathname,相信大家通过变量名也能够知道这是个什么参数,没错,这就是文件的位置加名字,通过字符串表示,这个没什么难的,我也不需要多讲。
第二个参数int flags,这是干嘛的?你们可能得说了,这不就是一个整数嘛,有啥,并不是,他是一个有32位的位图数据结构。什么意思?看下代码。
1 #include
2
3 #define ONE 0x01
4 #define TWO 0x02
5 #define THREE 0x04
6 #define FOUR 0x08
7 #define FIVE 0x10
8
9 void Print(int flags)
10 {
11 if(flags & ONE) printf("ONE\n");
12 if(flags & TWO) printf("TWO\n");
13 if(flags & THREE) printf("THREE\n");
14 if(flags & FOUR) printf("FOUR\n");
15 if(flags & FIVE) printf("FIVE\n");
16 }
17
18 int main()
19 {
20 Print(ONE);
21 printf("*******************************\n");
22 Print(ONE | TWO);
23 printf("*******************************\n");
24 Print(ONE | TWO | THREE);
25 printf("*******************************\n");
26 }
输出:

看到了什么现象?我们通过不同的位然后输出了不同的结果,这也就是位图的作用。
而我们的open函数里面的flags也是同样的作用,只不过它提供了更多的接口罢了。如下:



![]()
除了以上接口外,还有很多接口,不过博主认为初次学习认识这些接口就行了。
O_APPEND:追加内容
O_CREAT:没有文件时创建文件
O_TRUNC:清空之前文件数据
O_RDONLY:只读
O_WRONLY:只写
O_RDWR:可读可写
操作方式:

大家可能会主要到0666,这是什么?很简单,这就是权限的意思,表示所有人都是可读可写,那么创建的log.txt的权限表示应该是-rw-rw-rw-这样才对,但是看界面:

是我们说的那样嘛?很明显不是,为什么那是因为有一个权限掩码的东西在作祟,也就是umask。怎么改呢?很简单只需要在主程序当中加一句umask(0)即可。



上述就是open函数的操作了,其余函数我也不讲解了,有兴趣的大家可以自行了解,本篇文章重点不再这里,而是open函数的返回值int fd。
3.2 文件描述符
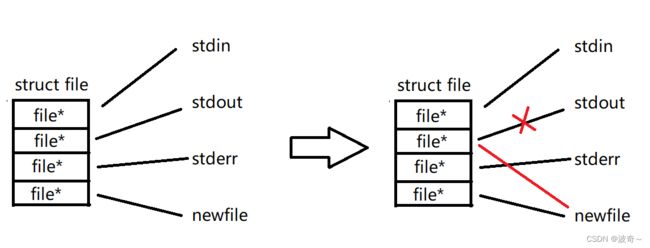
所谓文件描述符其实也不是什么很牛逼的东西,就是一个数字,也可以说是一个数组下标,还记得我开始画的那一张图嘛?

就是这一张图,它的里面就应该有文件描述符,只不过我没有画出来罢了,如果加上就变成了如下:
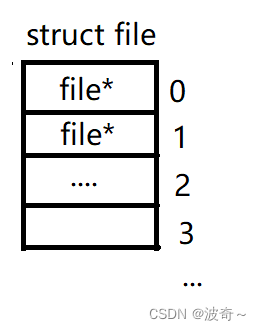
我们的每一个进程里面都有自己专属的struct file结构体,这个结构体变量里面会存储大量的被打开的文件的地址,但是,我们这些文件的时候却不是通过地址去匹配,而是通过下标实现,也就是我们的文件描述符fd。
在C封装代码当中我们也是能够找到文件标识符的:

我们每打开一个进程,操作系统都会自动为我们打开三个文件分别是标准输入、标准输出、标准错误,分别对应了文件描述符0、1、2这三个位置。通过代码可以查看:


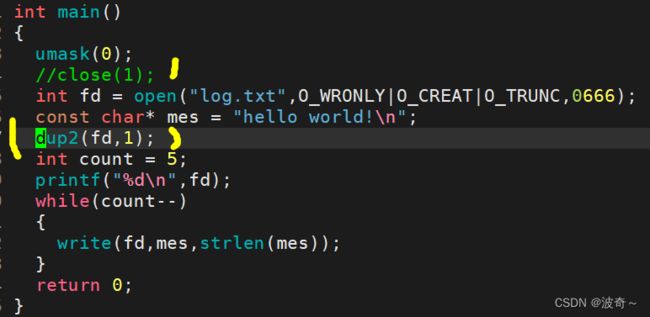
当然这都不是重点,重点是当我们知道了这三个文件的文件描述符我们就能干一件什么事情呢?那就是偷偷给他把里面的地址换了,换成我们自己的文件地址,怎么说呢?也就是重定向功能,比如本来应该输出到显示器上的代码,现在却跑到了我自己的文件中去了。如下:
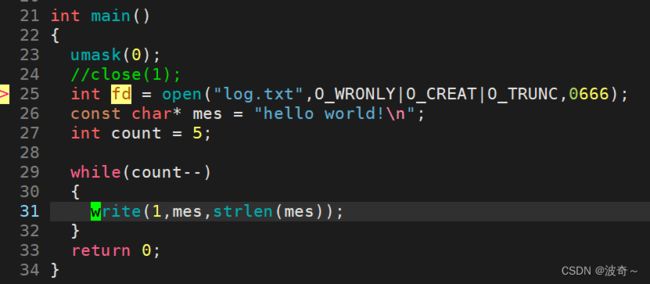
当我们没有关闭1号文件,那么这个时候的1号文件就是stdout对应的文件,那么输出的方式就是在显示器上表示出来,看结果:
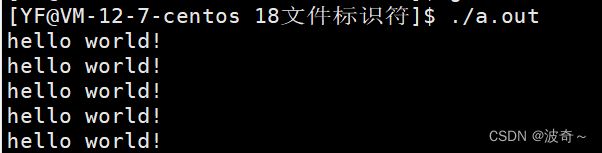
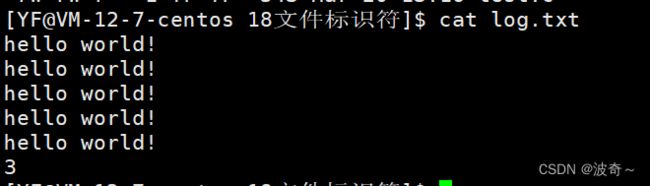
和我们预想的一模一样,那么我们将1号文件关闭,再自己在后面打开一个文件,请看发生了什么。
![]()

看到了吗?我们的输出跑到了log.txt文件当中去了,整个过程我就关闭了1号文件,然后创建了一个文件,而且创建的文件的文件标识符又变成了1,这说明了什么?
这证明了,文件描述符的存储方式根据顺序排列,如果前面有小的描述符,那么这个文件就会去占据哪一个位置。

此时,咱们就实现了流的重定向功能,但是这样做有点太挫了,看不下去,还要先去关闭一个文件才能重新指向一个新的文件,所以还有一个接口dup(),就是用来替换这种无语的操作的,看下方:
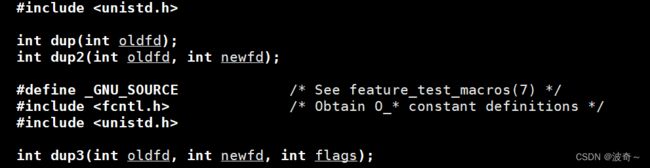
当然,一般来说我们都是用dup2()来替换的,其中的两个参数表示,将oldfd去指向newfd,表示了关闭原来的newfd,成为现在的oldfd。这样讲有点绕,图解:
看到了吗?我们并没有改变log.txt的指向,也没有关闭1号文件,但是我们输出内容时,都会被存到log.txt文件当中,还可以看到log.txt的文件描述符不是1而是3,这就表明了,我们将1号位置的文件地址变为了log.txt,3号还是三号。
4 缓冲区
对于缓冲区,博主不想说过多,不过基础的知识可以提及一些,缓冲区在系统当中是没有这个玩意的,缓冲区的实现和我们平时写的代码是一个级别的东西,都是用户层代码。平时我们看不到它,但是它却存在的原因是因为有库文件为我们维护了,它的实现很复杂也很牛逼,博主也不明白,可能以后会明白,但是我知道缓冲区有三种刷新方式。
无缓冲:内容直接刷新
行缓冲:遇到一个\n刷新
全缓冲:缓冲区满了或者程序结束了刷新
对于这个的理解我用一段奇怪的代码,大家就能够理解了:
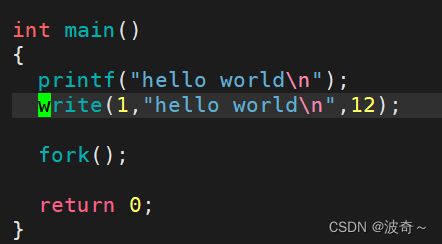

这没什么,不就是把数据输出嘛,也没什么不对,但是请看下面:
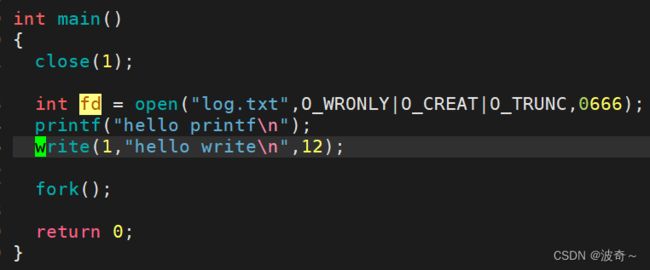

我们重定向到log.txt文件当中发生了什么?先输出的write,然后在输出了两个printf,这很奇怪不是吗?其实不然,如果我们知道了缓冲区就知道了怎么回事。
write是系统调用,所以没有缓冲区,但是printf呢,有缓冲区,并且因为有fork()创建了一个子进程,那么这个时候缓冲区的内容同时被父子进程都获取到了,但是程序结束需要刷新缓冲区,这个时候就会发生什么?父进程或者子进程都会区刷新缓冲区,但是缓冲区只有一个数据,怎么办呢?那么这个时候就会出现写时拷贝的这个过程,也就表示了会出现两个hello printf。
出现这个现象,究其原因其实就是我们的文件重定向之后,将缓冲区刷新方式冲行缓冲变为了什么?全缓冲。
以上,就是我对文件初认识的全部理解,希望能对大家有帮助。