【Algorithms 4】算法(第4版)学习笔记 07 - 2.4 优先队列
文章目录
-
- 前言
- 参考目录
- 学习笔记
-
- 1:API
- 1.1:实现 demo 示例
- 1.2:初级实现(有序或无序的数组)
- 2:二叉堆
- 2.1:完全二叉树
- 2.2:二叉堆
- 2.2.1:堆的表示
- 2.2.2:属性
- 2.3:堆算法:由下至上的堆有序化(上浮)
- 2.3.1:swim 介绍
- 2.3.2:swim 代码实现
- 2.3.3:应用:堆插入节点
- 2.3.4:swim 应用代码实现
- 2.3.5:swim 应用 demo 演示
- 2.4:堆算法:由上至下的堆有序化(下沉)
- 2.4.1:sink 介绍
- 2.4.2:sink 代码实现
- 2.4.3:应用:堆删除最大节点
- 2.4.4:sink 应用代码实现
- 2.4.5:sink 应用 demo 演示
- 2.5:优先队列实现开销小结
- 2.6:实际考虑
- 3:堆排序
- 3.1:堆排序 demo 演示
- 3.1.1:堆构造阶段
- 3.1.2:堆排序阶段(下沉排序)
- 3.2:代码实现
- 3.3:堆排序数学分析
- 4:排序算法小结
前言
本文的主要内容包括 二叉堆 以及 堆排序,视频课程中还有关于事件驱动模拟(event-driven simulation)的介绍,本文不详细展开,感兴趣的朋友建议移步视频自行学习总结。
参考目录
- B站 普林斯顿大学《Algorithms》视频课
(请自行搜索。主要以该视频课顺序来进行笔记整理,课程讲述的教授本人是该书原版作者之一 Robert Sedgewick。) - 微信读书《算法(第4版)》
(本文主要内容来自《2.4 优先队列》) - 官方网站
(有书本配套的内容以及代码)
学习笔记
注1:下面引用内容如无注明出处,均是书中摘录。
注2:所有 demo 演示均为视频 PPT demo 截图。
1:API
表2.4.1 泛型优先队列的API

1.1:实现 demo 示例
为了展示优先队列的抽象模型的价值,考虑以下问题:输入N个字符串,每个字符串都对应着一个整数,你的任务就是从中找出最大的(或是最小的)M个整数(及其关联的字符串)。
edu.princeton.cs.algs4.TopM
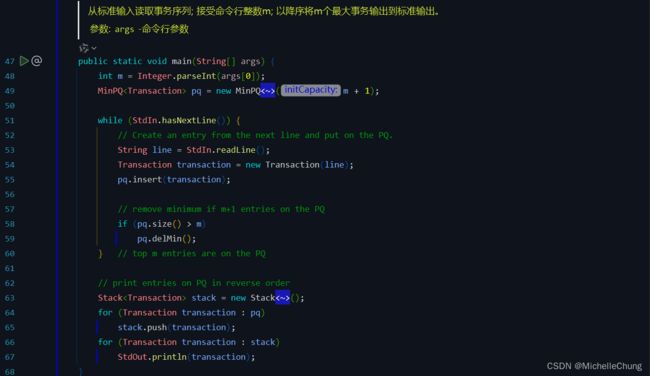
1.2:初级实现(有序或无序的数组)
UnorderedArrayMaxPQ
源码里面没有这个类,给出官网的 传送门。
Sedgewick 教授的评价:
(这是一个)“作弊”的版本:该方式要求用户提供数组初始空间。
OrderedArrayMaxPQ
源码里面没有这个类,给出官网的 传送门。
表2.4.3 优先队列的各种实现在最坏情况下运行时间的增长数量级
(注:堆在后文详细说明)

2:二叉堆
2.1:完全二叉树
二叉堆的概念基于完全二叉树。

来简单汉化一下:
Binary tree.Empty or node with links to left and right binary trees.
二叉树。要么为空,要么为一个带有指向左右子二叉树链接的节点。
Complete tree.Perfectly balanced,except for bottom level.
完全树(Complete Tree)。除了最底层外,完美平衡。
进一步理解一下:
- 二叉树是一种数据结构,它或者是空的,或者是包含一个节点,该节点有两个指针分别链接到它的左子二叉树和右子二叉树。
- 完全二叉树是一种特殊的二叉树,其特点是除了最后一层外,所有层都是完全填满的,即所有节点都有两个子节点,除非它们是位于最后一层的叶子节点。这意味着完全二叉树非常接近平衡状态,仅在最底层可能出现节点数量不均等的情况。
Property.Height of complete tree with N nodes is [lg N].
性质:具有 N 个节点的完全二叉树的高度是 [lg N]。
Pf.Height only increases when N is a power of 2.
证明:高度仅在 N 是 2 的幂时增加。
这里的证明有点随意……我个人感觉这个证明有点类似 1.5 章节中的 加权 quick-union 方法中的证明,可以回头看下。
2.2:二叉堆
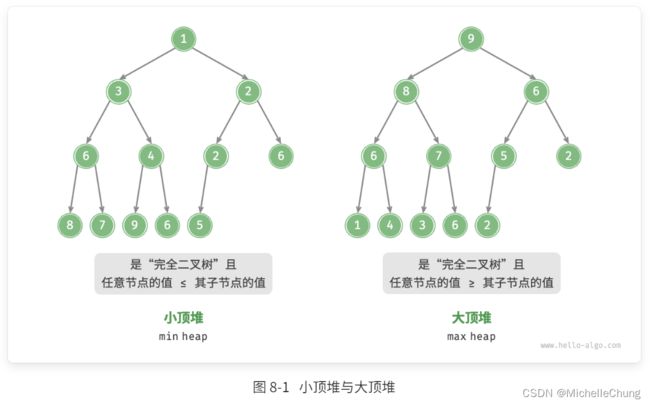
本节中的二叉堆都是以 max-heap 进行说明,与之相对应的是 min-heap。
这两者的区别可以看下这个图:
图源:Hello 算法
https://www.hello-algo.com/chapter_heap/heap/
2.2.1:堆的表示
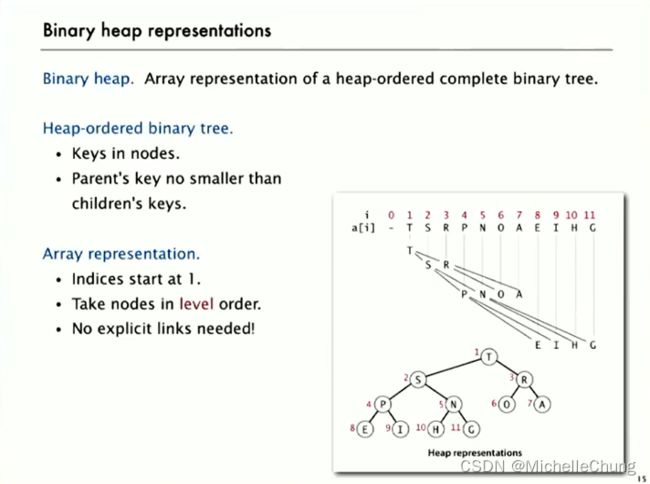
来简单汉化一下:
Binary heap.Array representation of a heap-ordered complete binary tree.
二叉堆。一种使用数组表示的堆排序完全二叉树。
Heap-ordered binary tree.
- Keys in nodes.
- Parent’s key no smaller than children’s keys.
堆序二叉树。
- 节点中包含键(关键字)。
- 父节点的键不小于其子节点的键。
Array representation.
- Indices start at 1.
- Take nodes in level order.
- No explicit links needed!
数组表示。
- 索引从1开始计数。
- 按层级顺序遍历节点。
- 无需显式链接!
进一步说明:
- 索引从1开始计数:这里的“索引从1开始”是指数组的第一个元素对应于二叉树中的根节点,而非通常编程语言中数组索引从0开始的习惯。
- 按层级顺序遍历节点:这意味着我们可以按照二叉树的层级顺序(也称为广度优先搜索顺序)依次访问数组中的元素,从而实现对整个二叉树的遍历。
- 无需显式链接:由于采用数组存储并利用了完全二叉树的特点,可以通过计算得出任意节点的父节点或子节点在数组中的位置,因此不需要像传统链表那样为每个节点设置显式的指针来指向其父节点或子节点。
2.2.2:属性
没有截图教授的 PPT 内容,不过还是将关键的内容汉化一下。
Proposition.Largest key is a[1],which is root of binary tree.
最大的键是a[1],这是二叉树的根节点。
Proposition.Can use array indices to move through tree.
- Parent of node at k is at k/2.
- Children of node at k are at 2k and 2k+1.
命题:可以使用数组索引遍历二叉树节点。
- 索引为 k 的节点的父节点位于索引 k/2 处(整数除法)。
- 索引为 k 的节点的子节点分别位于索引 2k 和 2k+1 处。
进一步解释:
这个命题描述了如何通过数组来实现堆序完全二叉树的逻辑结构。当完全二叉树采用数组表示时,可以通过简单的算术运算快速定位任意节点的父节点和子节点:
- 要访问某个节点 k 的父节点,只需将索引 k 除以 2(通常采用向下取整的整数除法),得到的结果就是其父节点在数组中的位置。
- 对于索引为 k 的节点,其左孩子节点的位置是索引 2k,右孩子节点的位置是索引 2k+1。
这种数组表示方法省去了显式维护指针链接的需要,极大地简化了算法实现,并提高了存储和操作效率。
(截图自官网)

2.3:堆算法:由下至上的堆有序化(上浮)
2.3.1:swim 介绍
场景:子节点比父节点大。
消除违例:
- 交换异常的父子节点。
- 重复此操作,直到恢复堆顺序。

2.3.2:swim 代码实现
edu.princeton.cs.algs4.MaxPQ#swim

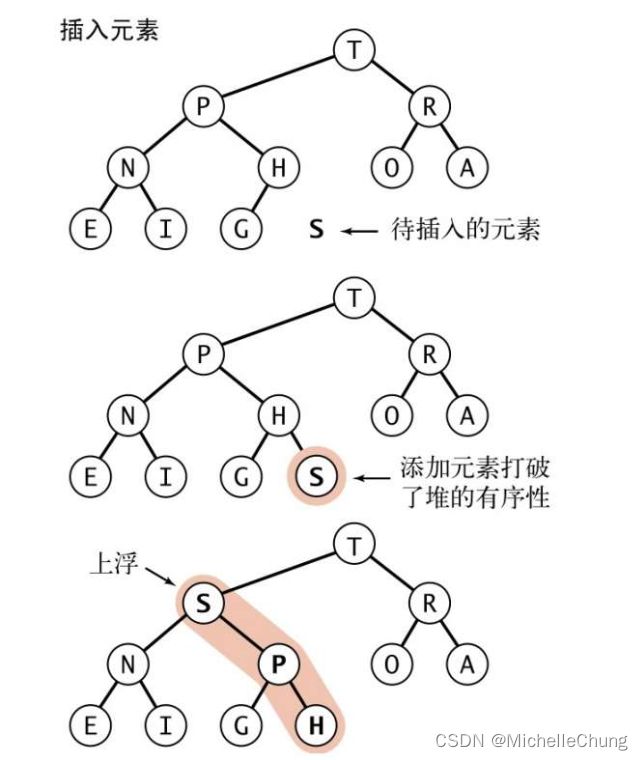
2.3.3:应用:堆插入节点
插入节点:在末尾加入元素,然后让其swim到相应的位置。
开销:最多 1 + lgN 次交换。
2.3.4:swim 应用代码实现
edu.princeton.cs.algs4.MaxPQ#insert

2.3.5:swim 应用 demo 演示
初始状态:

将新的节点加入到数组末尾(打破了堆顺序,swim):

与父级进行交换,直到顺序正确。
第一次交换:
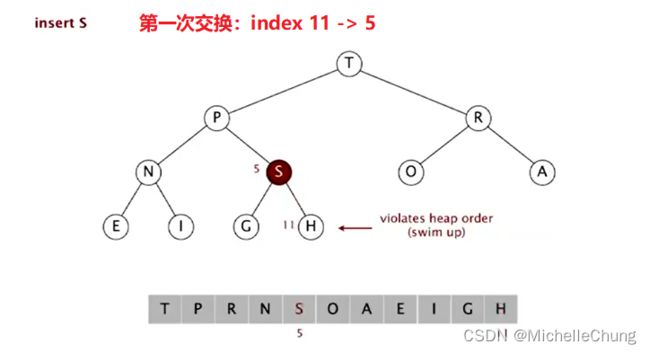
第二次交换:
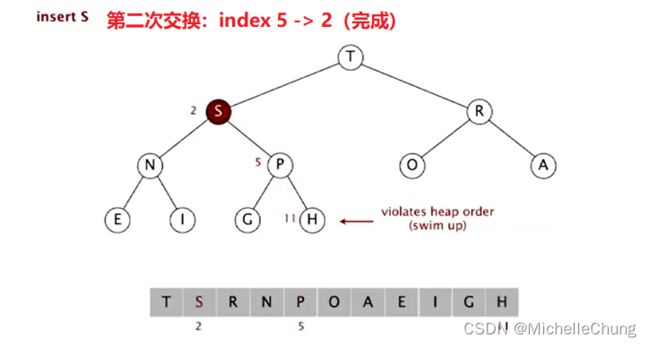
S比T小,交换结束。
最终堆有序状态:

2.4:堆算法:由上至下的堆有序化(下沉)
2.4.1:sink 介绍
场景:父节点比它的两个子结点或是其中之一更小。
消除违例:
- 将父节点与较大的子节点进行交换。
- 重复此操作,直到恢复堆顺序。
图2.4.4 由上至下的堆有序化(下沉)

2.4.2:sink 代码实现
edu.princeton.cs.algs4.MaxPQ#sink
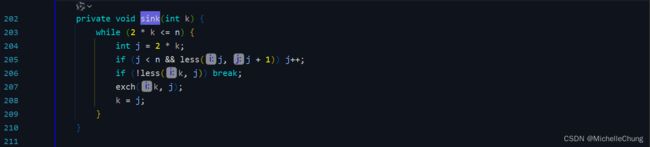
2.4.3:应用:堆删除最大节点
删除最大节点:交换根节点与末尾的元素,然后让新的根节点sink到相应的位置。
开销:最多 2lgN 次交换。

2.4.4:sink 应用代码实现
edu.princeton.cs.algs4.MaxPQ#delMax

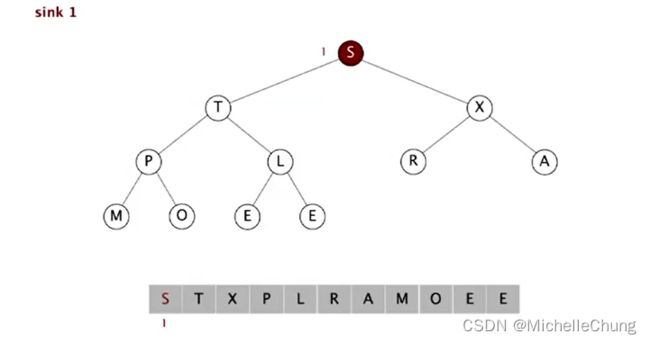
2.4.5:sink 应用 demo 演示
初始状态:

与末尾的节点交换:

删除末尾的元素,并得到新的根节点(打破了堆顺序,sink):

与较大的子节点进行交换,直到顺序正确。
第一次交换:
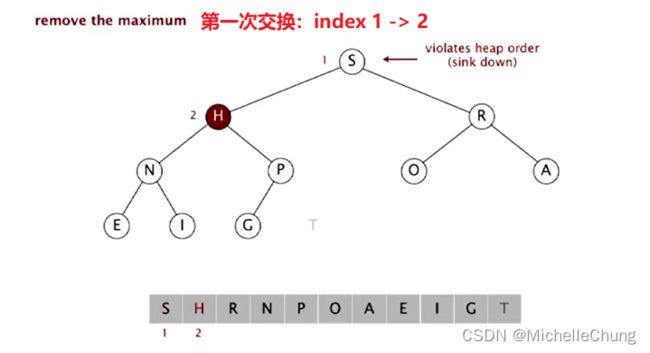
第二次交换:
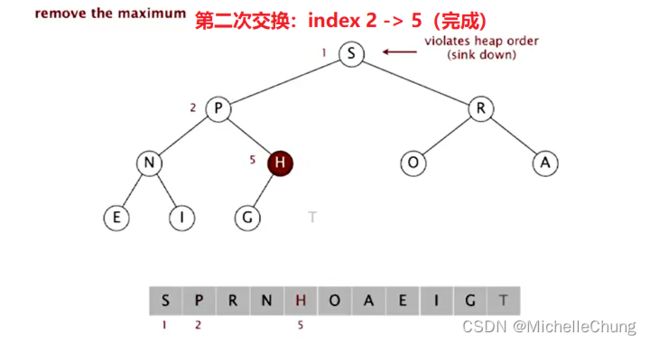
H比G大,交换结束。
最终堆有序状态:

2.5:优先队列实现开销小结

2.6:实际考虑
(截图自官网)

3:堆排序
3.1:堆排序 demo 演示
3.1.1:堆构造阶段

堆的构造。使用自底向上的方法构建大顶堆。(假设数组元素下标是1到N)
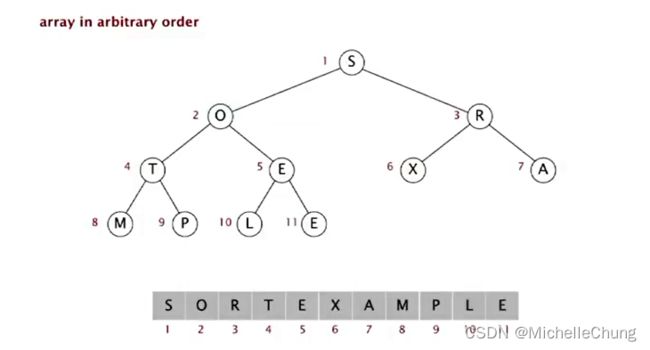
初始状态:任意排序的数组
第一步:单节点堆
开始时我们只需要扫描数组中的一半元素,因为我们可以跳过大小为1的子堆。

第二步:3节点堆(数组从右往左扫描)
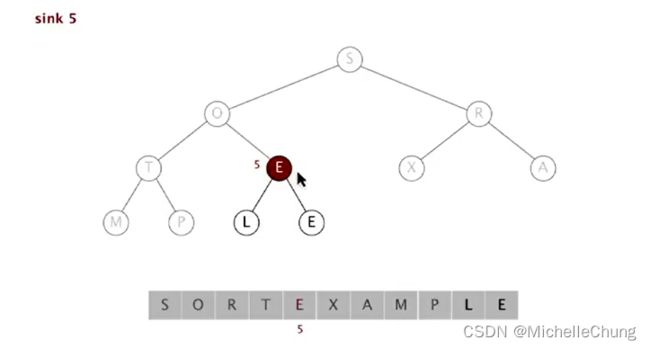
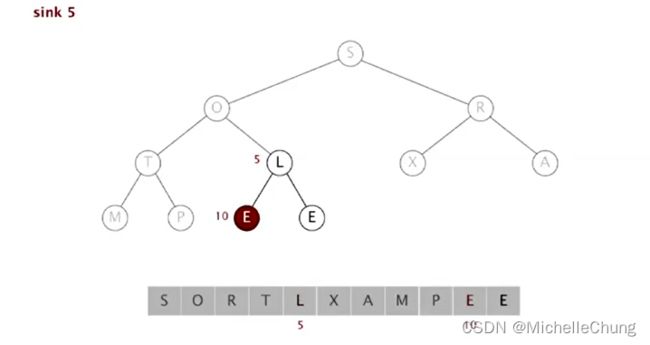

依次扫描E(5)、T(4)、R(3):

第三步:7节点堆




7节点堆下沉完成。
第四步:11节点堆(完全二叉树:15节点堆)


11节点堆下沉完成。
堆构造阶段结束。
3.1.2:堆排序阶段(下沉排序)

下沉排序(降序排序)。重复删除数组中最大的剩余元素项。
即持续交换下标1与末尾的元素,并使用 sink 方法重新排序。参考前文 2.4.5 demo。
最终得到的结果:

3.2:代码实现
edu.princeton.cs.algs4.Heap#sort

图2.4.7 堆排序:堆的构造(左)和下沉排序(右)

3.3:堆排序数学分析

汉化:
定理:构建一个堆需要 <= 2N 次比较和交换操作。
定理:堆排序需要 <= 2NlgN 次比较和交换操作。
重要性。最坏情况为NlogN的原地排序算法。
- 归并排序:no,线性额外空间。(可以原地合并,但不实用)
- 快速排序:no,最坏情况是平方时间。(可能最坏情况是NlogN,但不实用)
- 堆排序:yes!
底线。堆排序在时间和空间上都是最优的。但是:
- 内层循环时间比快速排序长
- 缓存使用不充分(使用率低)
- 不稳定
4:排序算法小结
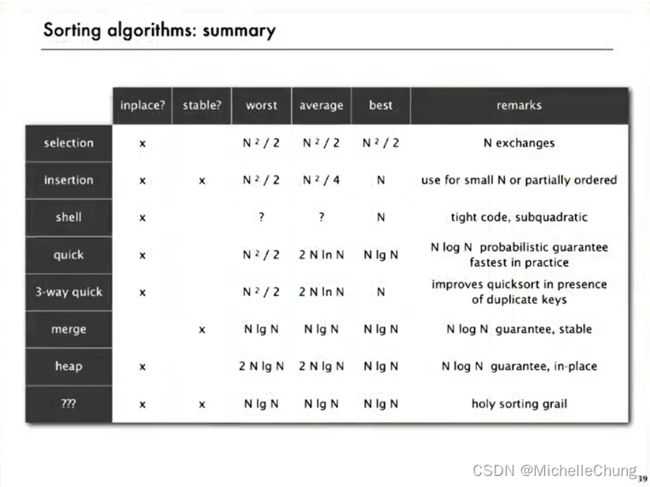
做成表格简单汉化一下:
| 原地? | 稳定? | 最坏 | 平均 | 最好 | 备注 | |
|---|---|---|---|---|---|---|
| 选择排序 | × | N2/2 | N2/2 | N2/2 | N次交换 | |
| 插入排序 | × | × | N2/2 | N2/4 | N | N较小或者是部分排序时使用 |
| 希尔排序 | × | ? | ? | N | 编码紧凑,次平方时间复杂度 (次平方:指其运行时间的增长速度低于问题规模(通常是输入大小)的平方) |
|
| 快速排序 | × | N2/2 | 2NlnN | NlgN | NlogN概率保证,在实践中最快 | |
| 三向切分快速排序 | × | N2/2 | 2NlnN | N | 改进存在重复键时的快排 | |
| 归并排序 | × | NlgN | NlgN | NlgN | NlogN保证,稳定 | |
| 堆排序 | × | 2NlgN | 2NlgN | NlgN | NlogN保证,原地排序 | |
| ??? | × | × | NlgN | NlgN | NlgN | 排序的圣杯 (在计算机编程中,“Holy Sorting Grail”这个表达通常用来比喻一种理想化的排序算法。) |
(完)