Java代码实现多级目录树的封装(转)
我们经常在代码里会造一个树结构对象,以方便前端使用。
以地区(区、镇、村)为例
后台一般对于树结构对象在数据库的结构是这样的:
| 主键ID | 名字 | 父ID |
|---|---|---|
| ID | REGION_NAME | PARENT_ID |
| 121100 | 尼龙区 | 0 |
| 121100001 | 尼龙区钢丝镇 | 121100 |
| 121100001001 | 尼龙区钢丝镇螺丝村 | 121100001 |
其实这样返回给前端,前端是可以做成树的,但是我这里不是要说这种的,我遇到的是下边的情况。
| 主键ID | 名字 | 词典表类型 |
|---|---|---|
| ID | REGION_NAME | DICT_TYPE |
| 121100 | 尼龙区 | XZQH |
| 121100001 | 尼龙区钢丝镇 | XZQH |
| 121100001001 | 尼龙区钢丝镇螺丝村 | XZQH |
| 231111 | 一般性支付 | ZFFS |
数据库的结构如上,并没有树结构,需要根据DICT_TYPE为XZQH的记录取出来,然后封装成树结构返回给前端,前端要的树结构类似如下:
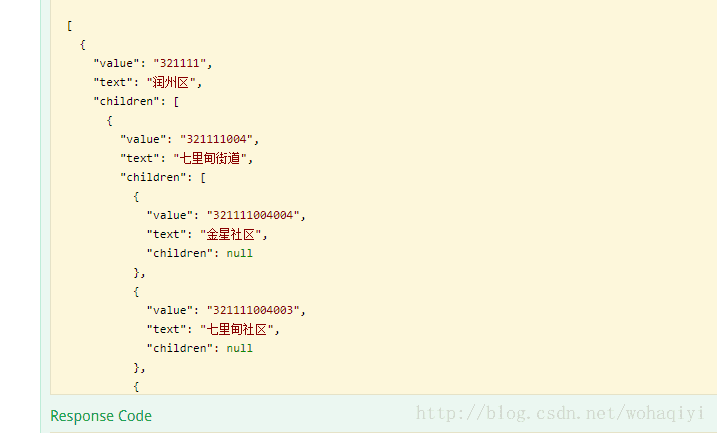
我的实现的逻辑是这样的:
- 首先根据DICT_TYPE取出相关的地区记录。
- 然后将区、镇、村分别存到三个不同的map里。
- 最后,嵌套遍历三个map的key,区里边套镇、镇里边套村,封装对象。(最重要的地方)。
具体步骤:
1、建立一个对象,用来规范树结构。
public class FpzjXzdwArray implements Serializable {
private String value; //对应数据库的ID
private String text; //对应数据库的region_name
private List children;
//省略get/set方法了
} - 1
- 2
- 3
- 4
- 5
- 6
2、第一步我就省略了。
3、第二步像我这种情况就是根据ID了,长度为6的放到区map里,长度为9的放到镇map里,长度为12的放到村map里。
Map<String,FpzjXzdwArray> quMap = new HashMap<String,FpzjXzdwArray>();
Map<String,FpzjXzdwArray> zhenMap = new HashMap<String,FpzjXzdwArray>();
Map<String,FpzjXzdwArray> cunMap = new HashMap<String,FpzjXzdwArray>();- 1
- 2
- 3
4、嵌套遍历三个map,首先缕缕我们的步骤。
以一个小例子为例,我们现在有一个大箱子、2个中箱子(1红、1蓝)、6个红蓝小箱子(3红、3蓝)。要求是把大箱子里装上中箱子,中箱子里要颜色对应装进去小箱子。
正确逻辑:如果让一个正常人来做,我们的逻辑都是一样的,要先把颜色对应的小箱子放到中箱子里以后,才会把中箱子放到大箱子里,对吗?
错误逻辑:如果你非要先把中箱子放到大箱子以后,再去拿对应颜色的小箱子放进中箱子里去的话,这样带来的一个问题就是,你必须要先把大箱子打开才可以完成这种事。所以这种逻辑就是错误的。
这个例子反映到代码里也是一样,如果你先往区对象里塞进镇对象集合,然后再去往镇对象里塞对应的村对象,就会像上边的第二个步骤一样,逻辑就错了。我的代码如下:(最下边还有别人分享给我的好方法,先贴上我的,瞬间感觉自己弱爆了)
for(String qu:quMap.keySet()){ //遍历所有的区
for(String zhen:zhenMap.keySet()){ //遍历所有的镇
if(qu.equals(zhen.substring(0,6))){ //该区下找到该镇
FpzjXzdwArray zhenXzdw = null;//定义这个是有必要的,这样可以先完成对村对象塞到镇对象里,然后再完成镇对象塞到区对象的步骤。
for(String cun:cunMap.keySet()){ //有区有镇,然后再找下一级村
if(zhen.equals(cun.substring(0,9))){ //该镇下找到村
zhenXzdw = zhenMap.get(zhen); //得到该镇对象,
List xzdwArrayZhenList = zhenXzdw.getChildren(); //取出镇对象下的村集合
if(xzdwArrayZhenList == null){
xzdwArrayZhenList = new ArrayList<>();
xzdwArrayZhenList.add(cunMap.get(cun));
zhenXzdw.setChildren(xzdwArrayZhenList); //将符合该镇下的村塞到镇对象里
}else{
xzdwArrayZhenList.add(cunMap.get(cun));
zhenXzdw.setChildren(xzdwArrayZhenList); //将符合该镇下的村塞到镇对象里
}
}
}
FpzjXzdwArray quXzdw = quMap.get(qu); //得到该区对象,
List xzdwArrayList = quXzdw.getChildren();//取出区对象下的镇集合
if(xzdwArrayList == null){
xzdwArrayList = new ArrayList<>();
xzdwArrayList.add(zhenXzdw);
quXzdw.setChildren(xzdwArrayList); //将符合该区下的镇对象塞到区对象里
quMap.put(qu,quXzdw);
}else{
xzdwArrayList.add(zhenXzdw);
quXzdw.setChildren(xzdwArrayList);//将符合该区下的镇对象塞到区对象里
quMap.put(qu,quXzdw);
}
}
}
}
return quMap.values(); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
以上就是我写的实现的逻辑,我还没有用上递归,本质是这样。
消耗的时间我也测试了,对我来说几毫秒,最多7ms。
我的数据的数量是:
| 数量 | 区 | 镇 | 村 |
|---|---|---|---|
| 总数 | 8 | 66 | 674 |
遍历的总次数:8*66*674=? //其实也挺多的次数。。
分享一:
在我加的技术群里吆喝了半天,有一位朋友分享他们的工具类,我感觉写的很好了。他需要数据的结构是:
| 主键ID | 名字 | 父ID |
|---|---|---|
| ID | REGION_NAME | PARENT_ID |
| 121100 | 尼龙区 | 0 |
| 121100001 | 尼龙区钢丝镇 | 121100 |
| 121100001001 | 尼龙区钢丝镇螺丝村 | 121100001 |
对应封装好的实体类对象可以是这样的:
public class TestTree{
private String id;
private String name;
private String pid;
private List testTrees;
//省略get/set方法
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
赋上他给我的两个工具类:
工具类下载地址
使用的主要逻辑在TreeUtils类里,在这里边我加了一个main方法,模拟了一个例子,大家可以参考。最后实现的结果如下图:
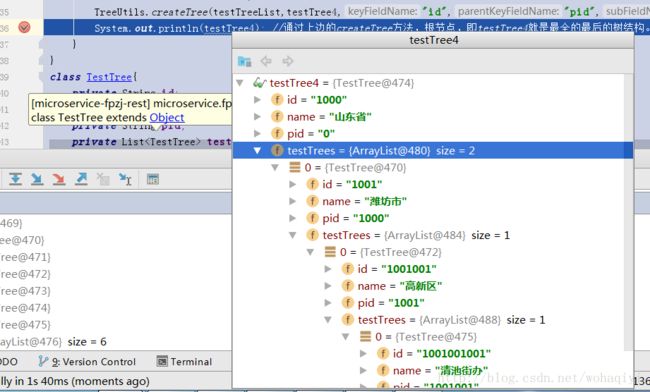
他的这个工具类的好处是,利用了反射,只要你的数据结构符合上边的id、pid、name这样的数据,叫什么名字都无所谓,不管多少层,都可以给弄出来。觉得这个特别好了。感谢@小太阳の !!
造树我觉得是挺重要的,挺常用的,如果有多级树,我这种方式就不适用,所以我想找到一个可以封装多级树的好代码,希望有能看到,留言共享一下,我再把好的方法补充到这个文章里。