python数据分析——对numpy的ndarray进行索引、切片、以及数组的一些计算函数
对数组进行索引
对数组进行索引时,直接使用[]中加入数字进行索引,有两种代码写法,如下:
import numpy as np
a = np.random.random((2,3,4))
print(a)
# 索引
print(a[0][1][1])
print(a[0,1,1])#结果与上面代码相同,但是更简洁
表示索引到第0维数组的一行一列,运行结果如下:

利用布尔类型的数组进行数据索引,最终返回的结果是对应索引数组中数据为True位置的值,如下:
print('bool值的索引')
b = np.random.random((2,4,2))
print(b)
c = b >0.5
print(c)
d = b[c]#这里表示的是c为True的b值
print(d)
代码运行结果如下:

还可以利用整数数组进行索引,叫做花式索引,代码示例:
import numpy as np
#花式索引:利用整数数组进行索引的方式
a = np.arange(32).reshape((8,-1))
print(a)
print('------')
print(a[1:3])#连续
print(a[[0,3,5]])#非连续行 连续的列
print(a[[0,3,5],[0,3,2]])#非连续行 非连续列 交叉的值
print(a[np.ix_([0,3,5],[0,3,2])])
得到的结果如下:

切片
在对数组进行切片时,切片的范围不包含数据最后一个,范围用‘起始:结束’来进行切割,若这一维的所有值都要包括那么不用写起始值和结束值,只需要使用:即可,如下:
import numpy as np
a = np.random.random((2,3,4))
print(a)
print(a[0,0,1:3])
print(a[0,1,1:3])
print(a[0,2,1:3])
print(a[0,:,1:3])
print(a[0][:][1:3])#这两个不一样
运行结果如图所示:
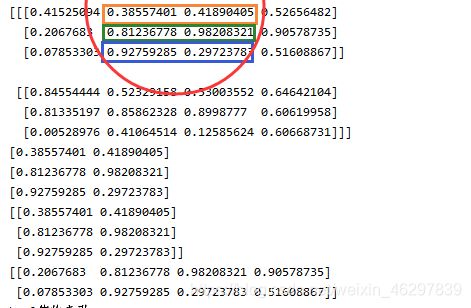
但是此刻可以观察到最后两行代码结果不一样,注意两者的区别
数组的一些计算函数
一元函数
数组的绝对值:abs
数组浮点型的绝对值:fabs
数组开平方:sqrt
数组的平方:square
数组中各个元素以e为底的arr次方:exp(arr)
数组各个元素的正负号:sign(),1为正数,-1为负数
isnan NaN(不是一个数字) 布尔类型数组
isfinite isinf 有穷的(非inf 非NaN)np.NaN np.inf 无穷的 布尔类型数组
cos cosh sin sinh tan tanh 普通以及双曲型三角函数
import numpy as np
#一元函数
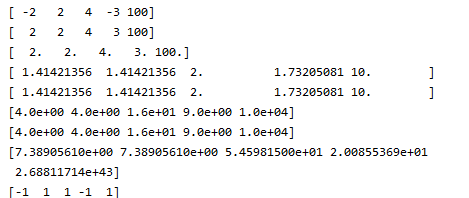
arr = np.array([-2,2,4,-3,100])
print(arr)
print(np.abs(arr))#计算数组的绝对值
print(np.fabs(arr))#计算数组浮点型的绝对值
arr1 = np.fabs(arr)
print(np.sqrt(arr1))#计算arr1开平方的数
print(arr1**0.5)#计算结果与开平方相同
print(np.square(arr1))#计算平方
print(arr1**2)#结果与上式相同
print(np.exp(arr1))#计算各个元素的指数e的arr1次方
print(np.sign(arr))#sign计算各个元素的正负号,1为正数,-1为负数,0
二元数组
mod 元素级的取模%
dot 点积 矩阵积
greater greater_equal less less_equal equal not_equal 元素级的比较运算,最终返回一个布尔型数组
logical_and logical_or logical_xor
power 对数组中的每个元素执行给定次数的指数值
print(np.power(arr,3))#表示arr的3次方
![]()
聚合函数
聚合函数的对一组值进行操作,返回一个单一值作为结果的函数, 常见的聚合函数有:平均值、最大值、最小值、方差等等, arr.mean() arr.max() arr.min() arr.std() arr.sum()
方差公式:np.sqrt(np.power(arr-arr.mean(),2).sum()/arr.size)
a = np.random.randint(2,100,(3,4,5))
print(a)
print(a.max(),a.min(),a.sum(),a.mean(),a.std())
b = np.array([[2,3,5,6],[3,4,9,1]])
print(b)
print(b.max(axis=0))
print(b.max(axis=1))

当axis=0的时候表示索引列,当axis=1时表示索引行
三元数组
np.where 的意思就是x if condition else y
c = np.array([[3,5],[2,8]])
d = np.array([[1,6],[4,3]])
print(c)
print(d)
e = c>d
print(e)
print(c[e])
condition = c>d
print(np.where(condition,c,d))#计算在condition情况下,此处是c>d,若c>d输出就是c里面的值,否则输出是d的值

数据处理
清除数据中包含的nan值或者无穷大inf值,将它们转换成0
q = np.array([[2,3,np.nan],[4,5,8],[np.inf,np.nan,33]])
print(q)
condition = np.isnan(q) | np.isinf(q)#数据处理,若出现nan或者inf这些无效数据,将其转换成0
print(np.where(condition,0,q))

有时还需要将数据集里面的数据进行数据去重,应该使用numpy中的unique来进行去重,去重的代码如下:
print('开始数据去重例子')
aa = np.random.randint(4,9,(4,4))
print(aa)
print(np.unique(aa))

最后得到的结果是数据去重后得到的数据