C语言进阶-深度剖析数据在内存中的存储之整形在内存的存储
目录
- 01 前言
- 02 原码、反码、补码
-
- 2.1 基本介绍
- 2.2 为什么会以补码的形式存储整形数据
- 2.3 为什么原码、反码、补码
- 03 大小端介绍
-
- 3.1 什么是大小端
- 3.2 为什么会存在大小端
- 04 练习
- 04 总结
01 前言
首先,我们来思考一下下面的代码的输出结果是什么。
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
你可能毫不犹豫的回答,1000;但正确的答案并不是1000。学习了本节之后,我们再来做这道题就能easy地得到正确答案了。
02 原码、反码、补码
2.1 基本介绍
你可能在之前的学习过程中了解过原码、反码、补码,也知道整形数据在内存中是以补码的形式存储。但,你知道为什么会以补码的形式存储吗,以补码的形式存储又有什么好处呢,那为什么会有原码、反码呢。
在讲原码、反码、补码之前,我先列出整形的归类,照顾一下基础相对薄弱的同学。
整形家族:
char:
unsigned char
signed char [char]
short:
unsigned short
signed short [short]
int:
unsigned int
signed int [int]
long:
unsigned long
signed long [long]
三种表示方式均由符号位和数值位两部分组成,符号位都是用0表示正,用1表示负,而数值位负整数的三种表示方法各不相同。
原码:
直接将二进制按照正负数的形式翻译成二进制就可以
反码:
将原码的符号位不变,其他位一次按位取反就可以得到了
补码:
反码+1就得到补码
正数的原码、反码、补码都相同;对于整形数据来说:数据存放在内存中是以补码的形式来存储的
现在举个简单的例子
char 1:
原码:0000 0001
反码:0000 0001
补码:0000 0001
char -1:
原码:1000 0001 //直接将二进制按照正负的形式翻译成二进制
反码:1111 1110 //符号位不变,数值位按位取反
补码:1111 1111 //反码加一
2.2 为什么会以补码的形式存储整形数据
原因有三。
- 原因一:
CPU只有加法计算器,加法和减法可以统一处理。比如2-1就相当于(2)+(-1) - 原因二:
补码与原码相互转换,其运算过程是相同的,不需要额外的增加硬件电路。(我不经感叹,实在是太妙了,妙不可言,大家可以亲自验证一下) - 原因三:
使用补码可以将符号位和数值域统一处理。
(如若存在其他原因,欢迎大家在评论区补充)
2.3 为什么原码、反码、补码
那为什么会有原码、反码呢?难道仅仅是为了有助于我们描述补码的表达形式。
首先,需要强调一点:计算机并不会区分正负数的(后面的练习题将有所体现),之所以产生正负数是为了满足解决我们人类生活中问题的需求。
为了表示正负数,人们发明了原码,把生活中应该有的正负数概念,原原本本的表示出来。
但是,原码的形式方便了人类却苦了计算机,我们希望(+1)+(-1)=0,但计算只能计算出0001+1001=1010(-2)。另外,这里存在着两种0,即1000(-0)和0000(+0)。
为了解决“正负相加为0”的问题,在原码的基础上,人们发明了反码。
反码虽然很好的解决了正负相加的问题,但正负0的问题依旧存在。更近一步,出现了补码,完全解决了这个问题。
因为在反码中“-0”1111再加一,就会变成1 0000,丢掉最高位的1就是0000了。
同时,补码的存在有2.2中所列举的几个原因,所以就沿用至今了。(不经感叹,计算机真的是人类社会最高的智慧结晶,(不接受反驳,狗头保命))
03 大小端介绍
通过上面的学习,有的同学可能已经在编译器中去验证,最后发现内存中数据和我们学的似乎不太一样。例如:

通过,下面的学习,你将理解了为什么不是FF FF FF F6。
3.1 什么是大小端
大端存储模式:数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中。
小端存储模式:数据的低位保存在内存的低地址中,而数据的高位,保存在内存的高地址中。
3.2 为什么会存在大小端
计算机系统中内存是以字节为单位进行编址的,每个地址单元都唯一的对应着1个字节(8 bit)。这可以应对char类型数据的存储要求,因为char类型长度刚好是1个字节,但是有些类型的长度是超过1个字节的(字符串虽然是多字节的,但它本质是由一个个char类型组成的类似数组的结构而已),比如C/C++中,short类型一般是2个字节,int类型一般4个字节等。因此这里就存在着一个如何安排多个字节数据中各字节存放顺序的问题。正是因为不同的安排顺序导致了大端存储模式和小端存储模式的存在。
两种存储方式各有千秋。
- 小端模式优点:
1、内存的低地址处存放低字节,所以在强制转换数据时不需要调整字节的内容(注解:比如把int的4字节强制转换成short的2字节时,就直接把int数据存储的前两个字节给short就行,因为其前两个字节刚好就是最低的两个字节,符合转换逻辑);
2、CPU做数值运算时从内存中依顺序依次从低位到高位取数据进行运算,直到最后刷新最高位的符号位,这样的运算方式会更高效。 - 大端模式优点:
符号位在所表示的数据的内存的第一个字节中,便于快速判断数据的正负和大小。
正因为两种存储形式各有优点,有不同的应用场景。加之一些厂商的坚持,两种存储方式难分伯仲。所以,一直没有一个统一的标准。
对于我们的绝大多数C\C++编译器来说,他们采用的存储方式都是小端存储。这也就解释了-10在内存中显示的是 F6 FF FF FF,而不是FF FF FF F6
04 练习
首先,让我们先解决文章开头的问题
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
解释:
第一点,a[i] =-1-i存在隐式类型转换,int类型转换成了char,即由原来的4字节变成了1字节;
第二点,随着i的增大,a[i]越变越小,直到-128。再由127减小至0。再接着上面过程循环,直到填满数组。如图所示
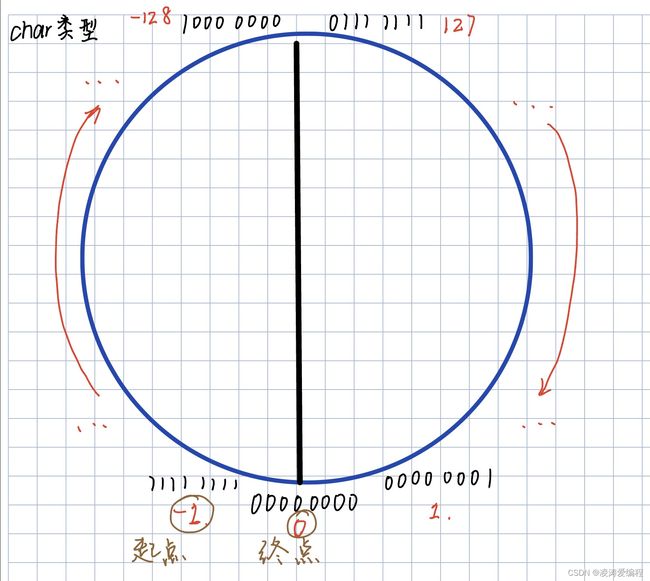
这也能帮助我们理解char类型的范围为-128到127
第三点,strlen函数遇到0时结束统计后面的数据。也就是统计第一次的-1到-128,再由127到1,共有255个数。
开始做练习前,我想强调一点:计算机并不会区分正负数的,最终输出的正负数是由我们自己决定的
答案我放在了评论区,如有疑问欢迎讨论
练习1
#include 练习2
#include 练习3
#include 练习4
#include 练习5
#include 04 总结
整形数据在内存中是以补码、大小端的方式来存储的。计算机并不能区分正负数,之所以存在正负数,是为了满足解决我们人类社会一些问题的需求。