十四、java 异常
文章目录
- 异常
-
- 5.1 初识异常
-
- 5.1.1 NullPointerException
- 5.1.2 NumberFormatException
- 5.2 异常类
-
- 5.2.1 Throwable
- 5.2.2 异常类体系
- 5.2.3 自定义异常
- 5.3 异常处理
-
- 5.3.1 try/catch匹配
- 5.3.2 重新抛出异常
- 5.3.3 finally
- 5.3.4 try-with-resources
- 5.3.5 throws
- 5.3.6 对比受检和未受检异常
- 5.4 如何使用好异常
-
- 5.4.1 异常应该且仅用于异常情况
- 5.4.2 异常处理的目标
- 5.4.3 异常处理的一般逻辑
异常
本文为书籍《Java编程的逻辑》1和《剑指Java:核心原理与应用实践》2阅读笔记
程序中,基本类型、类、接口、枚举都是在表示和操作数据,操作的过程中可能有很多出错的情况,出错的原因可能是多方面的,有的是不可控的内部原因,比如内存不够了、磁盘满了,有的是不可控的外部原因,比如网络连接有问题,更多的可能是程序的编写错误,比如引用变量未初始化就直接调用实例方法。这些非正常情况在Java中统一被认为是异常,Java使用异常机制来统一处理。接下来我们详细讨论Java中的异常机制,首先介绍异常的初步概念,以及异常类本身,然后主要介绍异常的处理。
5.1 初识异常
为认识异常,我们先认识一下两个具体的异常:NullPointerException和NumberFormatException。
5.1.1 NullPointerException
package com.ieening.learnException;
public class TestException {
public static void main(String[] args) {
String str = null;
int strLength = str.length();
System.out.println(strLength);
}
}
运行代码,没有得出结果,反而输出:
Exception in thread "main" java.lang.NullPointerException: Cannot invoke "String.length()" because "str" is null
at com.ieening.learnException.TestException.main(TestException.java:6)
输出是告诉我们:在TestException类的main函数中,代码第 6 6 6行,出现了空指针异常(java.lang.NullPointerException)。但,具体发生了什么呢?当执行str.length()的时候,Java虚拟机发现str的值为null,没有办法继续执行了,这时就启用异常处理机制,首先创建一个异常对象,这里是类NullPointerException的对象,然后查找看谁能处理这个异常,在示例代码中,没有代码能处理这个异常,因此Java启用默认处理机制,即打印异常栈信息到屏幕,并退出程序。异常栈信息就包括了从异常发生点到最上层调用者的轨迹,还包括行号,可以说,这个栈信息是分析异常最为重要的信息。Java的默认异常处理机制是退出程序,异常发生点后的代码都不会执行,所以示例代码中的System.out.println(strLength)不会执行。
5.1.2 NumberFormatException
package com.ieening.learnException;
public class TestException {
public static void main(String[] args) {
int integer = Integer.parseInt("a");
System.out.println(integer);
}
}
运行上面代码,得到结果:
Exception in thread "main" java.lang.NumberFormatException: For input string: "a"
at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:67)
at java.base/java.lang.Integer.parseInt(Integer.java:662)
at java.base/java.lang.Integer.parseInt(Integer.java:778)
at com.ieening.learnException.TestException.main(TestException.java:5)
根据异常栈信息,我们首先定位,NumberFormatException.java:67代码:

之后,回到Integer.java:662代码:

再查看Integer.java:778行代码:

最后回到TestException.java:5处。
将NumberFormatException.java:67和Integer.java:662合在一起可以知道:
throw new new NumberFormatException("For input string: \"" + s + "\"" + (radix == 10 ? "" : " under radix " + radix))
new NumberFormatException是容易理解的,含义是创建了一个类的对象,只是这个类是一个异常类。throw是什么意思呢?就是抛出异常,它会触发Java的异常处理机制。在之前的空指针异常中,我们没有看到throw的代码,可以认为throw是由Java虚拟机自己实现的。throw关键字可以与return关键字进行对比。return代表正常退出,throw代表异常退出;return的返回位置是确定的,就是上一级调用者,而throw后执行哪行代码则经常是不确定的,由异常处理机制动态确定。异常处理机制会从当前函数开始查找看谁“捕获”了这个异常,当前函数没有就查看上一层,直到主函数,如果主函数也没有,就使用默认机制,即输出异常栈信息并退出,这正是我们在屏幕输出中看到的。对于屏幕输出中的异常栈信息,程序员是可以理解的,但普通用户无法理解,也不知道该怎么办,我们需要给用户一个更为友好的信息,告诉用户,他应该输入的是数字,要做到这一点,需要自己“捕获”异常。“捕获”是指使用try/catch关键字,如下代码所示:
public class ExceptionTest {
public static void main(String[] args) {
if(args.length<1){
System.out.println("请输入数字");
return;
}
try{
int num = Integer.parseInt(args[0]);
System.out.println(num);
}catch(NumberFormatException e){
System.err.println("参数" + args[0] + "不是有效的数字,请输入数字");
}
}
}
上述代码使用try/catch捕获并处理了异常,try后面的花括号{}内包含可能抛出异常的代码,括号后的catch语句包含能捕获的异常和处理代码,catch后面括号内是异常信息,包括异常类型和变量名,这里是NumberFormatException e,通过它可以获取更多异常信息,花括号{}内是处理代码,这里输出了一个更为友好的提示信息。捕获异常后,程序就不会异常退出了,但try语句内异常点之后的其他代码就不会执行了,执行完catch内的语句后,程序会继续执行catch花括号外的代码。
至此,我们就对异常有了一个初步的了解。异常是相对于return的一种退出机制,可以由系统触发,也可以由程序通过throw语句触发,异常可以通过try/catch语句进行捕获并处理,如果没有捕获,则会导致程序退出并输出异常栈信息。
5.2 异常类
NullPointerException和NumberFormatException都是异常类,所有异常类都有一个共同的父类Throwable,我们首先学习这个父类,接着学习Java中的异常类体系,最后学习怎么自定义异常。
5.2.1 Throwable
追溯NullPointerException和NumberFormatException的继承体系,可以发现,两者的超类都是Throwable类。观察Throwable类,其有五个构造函数:
/**
* Constructs a new throwable with {@code null} as its detail message.
* The cause is not initialized, and may subsequently be initialized by a
* call to {@link #initCause}.
*
* The {@link #fillInStackTrace()} method is called to initialize
* the stack trace data in the newly created throwable.
*/
public Throwable() {
fillInStackTrace();
}
/**
* Constructs a new throwable with the specified detail message. The
* cause is not initialized, and may subsequently be initialized by
* a call to {@link #initCause}.
*
* The {@link #fillInStackTrace()} method is called to initialize
* the stack trace data in the newly created throwable.
*
* @param message the detail message. The detail message is saved for
* later retrieval by the {@link #getMessage()} method.
*/
public Throwable(String message) {
fillInStackTrace();
detailMessage = message;
}
/**
* Constructs a new throwable with the specified detail message and
* cause. Note that the detail message associated with
* {@code cause} is not automatically incorporated in
* this throwable's detail message.
*
*
The {@link #fillInStackTrace()} method is called to initialize
* the stack trace data in the newly created throwable.
*
* @param message the detail message (which is saved for later retrieval
* by the {@link #getMessage()} method).
* @param cause the cause (which is saved for later retrieval by the
* {@link #getCause()} method). (A {@code null} value is
* permitted, and indicates that the cause is nonexistent or
* unknown.)
* @since 1.4
*/
public Throwable(String message, Throwable cause) {
fillInStackTrace();
detailMessage = message;
this.cause = cause;
}
/**
* Constructs a new throwable with the specified cause and a detail
* message of {@code (cause==null ? null : cause.toString())} (which
* typically contains the class and detail message of {@code cause}).
* This constructor is useful for throwables that are little more than
* wrappers for other throwables (for example, {@link
* java.security.PrivilegedActionException}).
*
* The {@link #fillInStackTrace()} method is called to initialize
* the stack trace data in the newly created throwable.
*
* @param cause the cause (which is saved for later retrieval by the
* {@link #getCause()} method). (A {@code null} value is
* permitted, and indicates that the cause is nonexistent or
* unknown.)
* @since 1.4
*/
public Throwable(Throwable cause) {
fillInStackTrace();
detailMessage = (cause==null ? null : cause.toString());
this.cause = cause;
}
/**
* Constructs a new throwable with the specified detail message,
* cause, {@linkplain #addSuppressed suppression} enabled or
* disabled, and writable stack trace enabled or disabled. If
* suppression is disabled, {@link #getSuppressed} for this object
* will return a zero-length array and calls to {@link
* #addSuppressed} that would otherwise append an exception to the
* suppressed list will have no effect. If the writable stack
* trace is false, this constructor will not call {@link
* #fillInStackTrace()}, a {@code null} will be written to the
* {@code stackTrace} field, and subsequent calls to {@code
* fillInStackTrace} and {@link
* #setStackTrace(StackTraceElement[])} will not set the stack
* trace. If the writable stack trace is false, {@link
* #getStackTrace} will return a zero length array.
*
* Note that the other constructors of {@code Throwable} treat
* suppression as being enabled and the stack trace as being
* writable. Subclasses of {@code Throwable} should document any
* conditions under which suppression is disabled and document
* conditions under which the stack trace is not writable.
* Disabling of suppression should only occur in exceptional
* circumstances where special requirements exist, such as a
* virtual machine reusing exception objects under low-memory
* situations. Circumstances where a given exception object is
* repeatedly caught and rethrown, such as to implement control
* flow between two sub-systems, is another situation where
* immutable throwable objects would be appropriate.
*
* @param message the detail message.
* @param cause the cause. (A {@code null} value is permitted,
* and indicates that the cause is nonexistent or unknown.)
* @param enableSuppression whether or not suppression is enabled
* @param writableStackTrace whether or not the stack trace is writable
*
* @see OutOfMemoryError
* @see NullPointerException
* @see ArithmeticException
* @since 1.7
*/
protected Throwable(String message, Throwable cause,
boolean enableSuppression,
boolean writableStackTrace) {
if (writableStackTrace) {
fillInStackTrace();
} else {
stackTrace = null;
}
detailMessage = message;
this.cause = cause;
if (!enableSuppression)
suppressedExceptions = null;
}
Throwable类有两个主要参数:一个是message,表示异常消息;另一个是cause,表示触发该异常的其他异常。异常可以形成一个异常链,上层的异常由底层异常触发,cause表示底层异常。Throwable还有一个public方法用于设置cause:
/**
* Initializes the cause of this throwable to the specified value.
* (The cause is the throwable that caused this throwable to get thrown.)
*
* This method can be called at most once. It is generally called from
* within the constructor, or immediately after creating the
* throwable. If this throwable was created
* with {@link #Throwable(Throwable)} or
* {@link #Throwable(String,Throwable)}, this method cannot be called
* even once.
*
*
An example of using this method on a legacy throwable type
* without other support for setting the cause is:
*
*
* try {
* lowLevelOp();
* } catch (LowLevelException le) {
* throw (HighLevelException)
* new HighLevelException().initCause(le); // Legacy constructor
* }
*
*
* @param cause the cause (which is saved for later retrieval by the
* {@link #getCause()} method). (A {@code null} value is
* permitted, and indicates that the cause is nonexistent or
* unknown.)
* @return a reference to this {@code Throwable} instance.
* @throws IllegalArgumentException if {@code cause} is this
* throwable. (A throwable cannot be its own cause.)
* @throws IllegalStateException if this throwable was
* created with {@link #Throwable(Throwable)} or
* {@link #Throwable(String,Throwable)}, or this method has already
* been called on this throwable.
* @since 1.4
*/
public synchronized Throwable initCause(Throwable cause) {
if (this.cause != this)
throw new IllegalStateException("Can't overwrite cause with " +
Objects.toString(cause, "a null"), this);
if (cause == this)
throw new IllegalArgumentException("Self-causation not permitted", this);
this.cause = cause;
return this;
}
Throwable的某些子类没有带cause参数的构造方法,就可以通过这个方法来设置,这个方法最多只能被调用一次。
在所有构造方法的内部,都有一句重要的函数调用:fillInStackTrace()。它会将异常栈信息保存下来,这是我们能看到异常栈的关键。Throwable有一些常用方法用于获取异常信息,比如:
void printStackTrace():打印异常栈信息到标准错误输出流;void printStackTrace(PrintStream s)和void printStackTrace(PrintWriter s):打印栈信息到指定的流;String getMessage():获取设置的异常message;Throwable getCause():获取异常的`cause;StackTraceElement[] getStackTrace():获取异常栈每一层的信息, 每个StackTraceElement包括文件名、类名、函数名、行号等信息;
5.2.2 异常类体系
以Throwable为根,Java定义了非常多的异常类,表示各种类型的异常,部分类如下图所示。
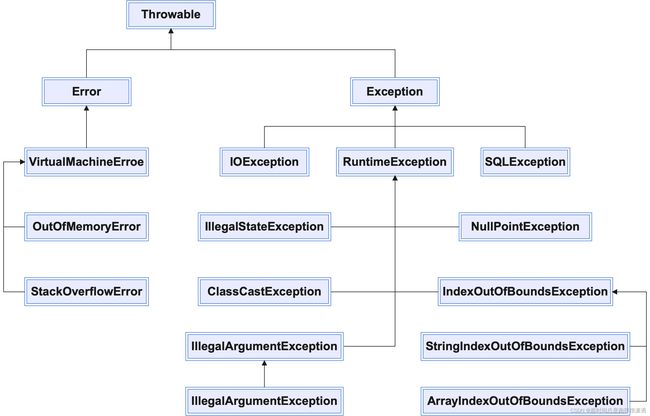
Throwable是所有异常的基类,它有两个子类:Error和Exception。Error表示系统错误或资源耗尽,由Java系统自己使用,应用程序不应抛出和处理,比如上图中列出的虚拟机错误(VirtualMacheError)及其子类内存溢出错误(OutOfMemoryError)和栈溢出错误(StackOverflowError)。Exception表示应用程序错误,它有很多子类,应用程序也可以通过继承Exception或其子类创建自定义异常,上图中列出了三个直接子类:IOException(输入输出I/O异常)、RuntimeException(运行时异常)、SQLException(数据库SQL异常)。RuntimeException比较特殊,它的名字有点误导,因为其他异常也是运行时产生的,它表示的实际含义是未受检异常(unchecked exception),相对而言,Exception的其他子类和Exception自身则是受检异常(checked exception),Error及其子类也是未受检异常。
受检(checked)和未受检(unchecked)的区别在于Java如何处理这两种异常。对于受检异常,Java会强制要求程序员进行处理,否则会有编译错误,而对于未受检异常则没有这个要求。
如此多不同的异常类其实并没有比Throwable这个基类多多少属性和方法,大部分类在继承父类后只是定义了几个构造方法,这些构造方法也只是调用了父类的构造方法,并没有额外的操作。那为什么定义这么多不同的类呢?主要是为了名字不同。异常类的名字本身就代表了异常的关键信息,无论是抛出还是捕获异常,使用合适的名字都有助于代码的可读性和可维护性。
5.2.3 自定义异常
除了Java API中定义的异常类,也可以自己定义异常类,一般是继承Exception或者它的某个子类。如果父类是RuntimeException或它的某个子类,则自定义异常也是未受检异常;如果是Exception或Exception的其他子类,则自定义异常是受检异常。我们通过继承Exception来定义一个异常,代码如下所示。
public class AppException extends Exception {
public AppException() {
super();
}
public AppException(String message, Throwable cause) {
super(message, cause);
}
public AppException(String message) {
super(message);
}
public AppException(Throwable cause) {
super(cause);
}
}
和很多其他异常类一样,我们没有定义额外的属性和代码,只是继承了Exception,定义了构造方法并调用了父类的构造方法。
5.3 异常处理
Java语言对异常处理的支持,包括catch、throw、finally、try-with-resources和throws。
5.3.1 try/catch匹配
如下代码所示,使用try/catch捕获异常,其中catch可以捕获一条或者多条,每条对应一种异常类型。
try{
//可能触发异常的代码
}catch(NumberFormatException e){
System.out.println("not valid number");
}catch(RuntimeException e){
System.out.println("runtime exception "+e.getMessage());
}catch(Exception e){
e.printStackTrace();
}
异常处理机制将根据抛出的异常类型找第一个匹配的catch块,找到后,执行catch块内的代码,不再执行其他catch块,如果没有找到,会继续到上层方法中查找。需要注意的是,抛出的异常类型是catch中声明异常的子类也算匹配,所以需要将最具体的子类放在前面,如果基类Exception放在前面,则其他更具体的catch代码将得不到执行。代码中也利用了异常信息,e.getMessage()获取异常消息,e.printStackTrace()打印异常栈到标准错误输出流。这些信息有助于理解为什么会出现异常,这是解决编程错误的常用方法。示例是直接将信息输出到标准流上,实际系统中更常用的做法是输出到专门的日志中。
在示例中,每种异常类型都有单独的catch语句,如果多种异常处理的代码是类似的,这种写法比较烦琐。自Java 7开始支持一种新的语法,多个异常之间可以用|操作符,形如:
try {
//可能抛出 ExceptionA和ExceptionB
} catch (ExceptionA | ExceptionB e) {
e.printStackTrace();
}
5.3.2 重新抛出异常
在catch块内处理完后,可以重新抛出异常,异常可以是原来的,也可以是新建的,如下所示:
try{
//可能触发异常的代码
}catch(NumberFormatException e){
System.out.println("not valid number");
throw new AppException("输入格式不正确", e);
}catch(Exception e){
e.printStackTrace();
throw e;
}
对于Exception,在打印出异常栈后,就通过throw e重新抛出了。而对于NumberFormatException,重新抛出了一个AppException,当前Exception作为cause传递给了AppException,这样就形成了一个异常链,捕获到AppException的代码可以通过getCause()得到NumberFormatException。
为什么要重新抛出呢?因为当前代码不能够完全处理该异常,需要调用者进一步处理。为什么要抛出一个新的异常呢?当然是因为当前异常不太合适。不合适可能是信息不够,需要补充一些新信息;还可能是过于细节,不便于调用者理解和使用,如果调用者对细节感兴趣,还可以继续通过getCause()获取到原始异常。
5.3.3 finally
异常机制中还有一个重要的部分,就是finally。catch后面可以跟finally语句,语法如下所示:
try{
//可能抛出异常
}catch(Exception e){
//捕获异常
}finally{
//不管有无异常都执行
}
finally内的代码不管有无异常发生,都会执行,具体来说:
- 如果没有异常发生,在
try内的代码执行结束后执行。 - 如果有异常发生且被
catch捕获,在catch内的代码执行结束后执行。 - 如果有异常发生但没被捕获,则在异常被抛给上层之前执行。
由于finally的这个特点,它一般用于释放资源,如数据库连接、文件流等。try/catch/finally语法中,catch不是必需的,也就是可以只有try/finally,表示不捕获异常,异常自动向上传递,但finally中的代码在异常发生后也执行。
finally语句有一个执行细节,如果在try或者catch语句内有return语句,则return语句在finally语句执行结束后才执行,但finally并不能改变返回值,我们来看下面的代码:
public static int test(){
int ret = 0;
try{
return ret;
}finally{
ret = 2;
}
}
这个函数的返回值是 0 0 0,而不是 2 2 2。实际执行过程是:在执行到try内的return ret;语句前,会先将返回值ret保存在一个临时变量中,然后才执行finally语句,最后try再返回那个临时变量,finally中对ret的修改不会被返回。
如果在finally中也有return语句呢?try和catch内的return会丢失,实际会返回finally中的返回值。finally中有return不仅会覆盖try和catch内的返回值,还会掩盖try和catch内的异常,就像异常没有发生一样,比如:
public static int test(){
int ret = 0;
try{
int a = 5/0;
return ret;
}finally{
return 2;
}
}
以上代码中,5/0会触发ArithmeticException,但是finally中有return语句,这个方法就会返回 2 2 2,而不再向上传递异常了。finally中,如果finally中抛出了异常,则原异常也会被掩盖,看下面的代码:
public static void test(){
try{
int a = 5/0;
}finally{
throw new RuntimeException("hello");
}
}
finally中抛出了RuntimeException,则原异常ArithmeticException就丢失了。所以,一般而言,为避免混淆,应该避免在finally中使用return语句或者抛出异常,如果调用的其他代码可能抛出异常,则应该捕获异常并进行处理。
5.3.4 try-with-resources
对于一些使用资源的场景,比如文件和数据库连接,典型的使用流程是首先打开资源,最后在finally语句中调用资源的关闭方法,针对这种场景,Java 7开始支持一种新的语法,称之为try-with-resources,这种语法针对实现了java.lang.AutoCloseable接口的对象,该接口的定义为:
public interface AutoCloseable {
void close() throws Exception;
}
没有try-with-resources时,使用形式如下:
public static void useResource() throws Exception {
AutoCloseable r = new FileInputStream("hello"); //创建资源
try {
//使用资源
} finally {
r.close();
}
}
使用try-with-resources语法,形式如下:
public static void useResource() throws Exception {
try(AutoCloseable r = new FileInputStream("hello")) { //创建资源
//使用资源
}
}
资源r的声明和初始化放在try语句内,不用再调用finally,在语句执行完try语句后,会自动调用资源的close()方法。资源可以定义多个,以分号分隔。在Java 9之前,资源必须声明和初始化在try语句块内,Java 9去除了这个限制,资源可以在try语句外被声明和初始化,但必须是final的或者是事实上final的(即虽然没有声明为final但也没有被重新赋值)。
5.3.5 throws
异常机制中,还有一个和throw很像的关键字throws,用于声明一个方法可能抛出的异常,语法如下所示:
public void test() throws AppException,
SQLException, NumberFormatException {
//主体代码
}
throws跟在方法的括号后面,可以声明多个异常,以逗号分隔。这个声明的含义是,这个方法内可能抛出这些异常,且没有对这些异常进行处理,至少没有处理完,调用者必须进行处理。这个声明没有说明具体什么情况会抛出什么异常,作为一个良好的实践,应该将这些信息用注释的方式进行说明,这样调用者才能更好地处理异常。
对于未受检异常,是不要求使用throws进行声明的,但对于受检异常,则必须进行声明,换句话说,如果没有声明,则不能抛出。对于受检异常,不可以抛出而不声明,但可以声明抛出但实际不抛出。这主要用于在父类方法中声明,父类方法内可能没有抛出,但子类重写方法后可能就抛出了,子类不能抛出父类方法中没有声明的受检异常,所以就将所有可能抛出的异常都写到父类上了。
如果一个方法内调用了另一个声明抛出受检异常的方法,则必须处理这些受检异常,处理的方式既可以是catch,也可以是继续使用throws,如下所示:
public void tester() throws AppException {
try {
test();
} catch(SQLException e) {
e.printStackTrace();
}
}
对于test抛出的SQLException,这里使用了catch,而对于AppException,则将其添加到了自己方法的throws语句中,表示当前方法处理不了,继续由上层处理。
5.3.6 对比受检和未受检异常
通过以上介绍可以看出,未受检异常和受检异常的区别如下:
受检异常必须出现在throws语句中,调用者必须处理,Java编译器会强制这一点,而未受检异常则没有这个要求。
为什么要有这个区分呢?我们自己定义异常的时候应该使用受检还是未受检异常呢?对于这个问题,业界有各种各样的观点和争论,没有特别一致的结论。一种普遍的说法是:未受检异常表示编程的逻辑错误,编程时应该检查以避免这些错误,比如空指针异常,如果真的出现了这些异常,程序退出也是正常的,程序员应该检查程序代码的bug而不是想办法处理这种异常。受检异常表示程序本身没问题,但由于I/O、网络、数据库等其他不可预测的错误导致的异常,调用者应该进行适当处理。但其实编程错误也是应该进行处理的,尤其是Java被广泛应用于服务器程序中,不能因为一个逻辑错误就使程序退出。所以,目前一种更被认同的观点是:Java中对受检异常和未受检异常的区分是没有太大意义的,可以统一使用未受检异常来代替。
这种观点的基本理由是:无论是受检异常还是未受检异常,无论是否出现在throws声明中,都应该在合适的地方以适当的方式进行处理,而不只是为了满足编译器的要求盲目处理异常,既然都要进行处理异常,受检异常的强制声明和处理就显得烦琐,尤其是在调用层次比较深的情况下。其实观点本身并不太重要,更重要的是一致性,一个项目中,应该对如何使用异常达成一致,并按照约定使用。
5.4 如何使用好异常
针对异常,我们学习了try/catch/finally、catch匹配、重新抛出、throws、受检/未受检异常,那到底该如何使用异常呢?下面从异常的适用情况、异常处理的目标和一般逻辑等多个角度进行介绍。
5.4.1 异常应该且仅用于异常情况
异常应该且仅用于异常情况,是指异常不能代替正常的条件判断。比如,循环处理数组元素的时候,应该先检查索引是否有效再进行处理,而不是等着抛出索引异常再结束循环。对于一个引用变量,如果正常情况下它的值也可能为null,那就应该先检查是不是null,不为null的情况下再进行调用。另一方面,真正出现异常的时候,应该抛出异常,而不是返回特殊值。
5.4.2 异常处理的目标
异常大概可以分为三种来源:用户、程序员、第三方。用户是指用户的输入有问题;程序员是指编程错误;第三方泛指其他情况,如I/O错误、网络、数据库、第三方服务等。每种异常都应该进行适当的处理。处理的目标可以分为恢复和报告。恢复是指通过程序自动解决问题。报告的最终对象可能是用户,即程序使用者,也可能是系统运维人员或程序员。报告的目的也是为了恢复,但这个恢复经常需要人的参与。对用户,如果用户输入不对,可以提示用户具体哪里输入不对,如果是编程错误,可以提示用户系统错误、建议联系客服,如果是第三方连接问题,可以提示用户稍后重试。对系统运维人员或程序员,他们一般不关心用户输入错误,而关注编程错误或第三方错误,对于这些错误,需要报告尽量完整的细节,包括异常链、异常栈等,以便尽快定位和解决问题。用户输入或编程错误一般都是难以通过程序自动解决的,第三方错误则可能可以,甚至很多时候,程序都不应该假定第三方是可靠的,应该有容错机制。比如,某个第三方服务连接不上(比如发短信),可能的容错机制是换另一个提供同样功能的第三方试试,还可能是间隔一段时间进行重试,在多次失败之后再报告错误。
5.4.3 异常处理的一般逻辑
如果自己知道怎么处理异常,就进行处理;如果可以通过程序自动解决,就自动解决;如果异常可以被自己解决,就不需要再向上报告。如果自己不能完全解决,就应该向上报告。如果自己有额外信息可以提供,有助于分析和解决问题,就应该提供,可以以原异常为cause重新抛出一个异常。总有一层代码需要为异常负责,可能是知道如何处理该异常的代码,可能是面对用户的代码,也可能是主程序。如果异常不能自动解决,对于用户,应该根据异常信息提供用户能理解和对用户有帮助的信息;对运维和开发人员,则应该输出详细的异常链和异常栈到日志。这个逻辑与在公司中处理问题的逻辑是类似的,每个级别都有自己应该解决的问题,自己能处理的自己处理,不能处理的就应该报告上级,把下级告诉他的和他自己知道的一并告诉上级,最终,公司老板必须要为所有问题负责。每个级别既不应该掩盖问题,也不应该逃避责任。
马俊昌.Java编程的逻辑[M].北京:机械工业出版社,2018. ↩︎
尚硅谷教育.剑指Java:核心原理与应用实践[M].北京:电子工业出版社,2023. ↩︎