Elasticsearch实战(二)--- 高级查询语法使用
Elasticsearch实战-高级查询语法使用
文章目录
-
-
- Elasticsearch实战-高级查询语法使用
-
- 1.ElasticSearch 基本语法查询
-
- 1.1 Match_all 匹配所有查询
- 1.2 Match 查询具体字段
- 1.3 全文检索匹配 match
- 1.4 短语匹配 match_phrase
- 1.5 from,to 分页查询
- 1.6 order 结果排序
- 1.7 查询指定列结果 _source
- 2.ElasticSearch 高级查询进阶
-
- 2.1 And 且条件,多条件查询
- 2.2 Or 或条件,多条件查询
- 2.3 大于,小于 条件,多条件查询
- 2.3 大于,小于 条件 且 And 多条件查询
- 2.4 聚合查询 group count 累加
- 2.5 聚合查询 取最大值, 最小值
- 2.6 聚合查询 Sum求和,Avg求平均
-
1.ElasticSearch 基本语法查询
基于文章 Elasticsearch实战(一)—安装及基本语法使用 我们已经在ES中插入了8条数据,现在我们使用下基本的查询语法
1.1 Match_all 匹配所有查询
DSL 语法中 查询所有 query : { “match_all”: {} }
# 查询所有
GET /test/_search
{
"query": {
"match_all": {}
}
}
1.2 Match 查询具体字段
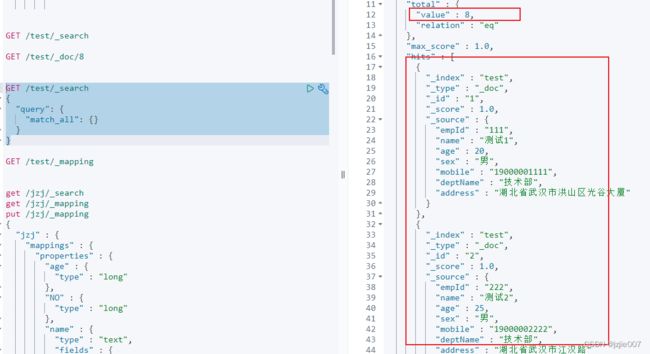
DSL 语法中 查询所有 query : { “match”: { “field”: “value” } } 查询字段的值, 现在我们的字段是 text类型,默认是按照一个个字取分词的
# 查询 mobile手机号为 19000002222的文档信息
get /test/_search
{
"query":{
"match": {
"mobile": "19000002222"
}
}
}
1条记录,精确匹配

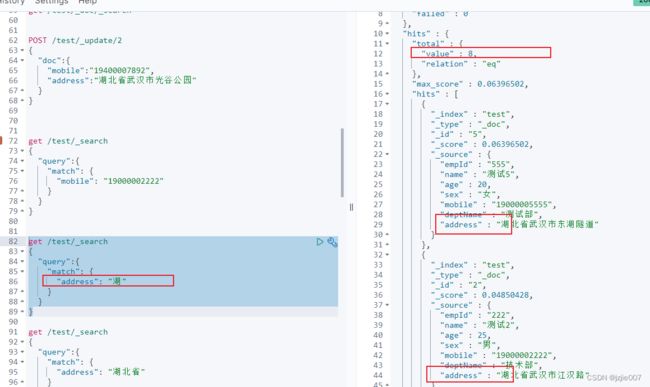
如果地址是长句子,比如 “湖北省武汉市江汉路” 我能根据 某个关键字去匹配么?我们试一试 搜一下
搜一个 “湖” 他会把所有记录全都搜出来
get /test/_search
{
"query":{
"match": {
"address": "湖"
}
}
}
搜一个黄 ,因为只有一条 黄冈市的 ,所以只有1条记录
get /test/_search
{
"query":{
"match": {
"address": "黄"
}
}
}

1.3 全文检索匹配 match
我们 按照地址 address 搜江汉, 试一试,期望是搜到 江汉路 相关的
# 搜 “江汉” 会出现所有地址中含有 江 字, 有汉字 记录, 因为我们的 mapping建立的时候没有指定分词,所以他就是一个一个字去拆解的
get /test/_search
{
"query":{
"match": {
"address": "江汉"
}
}
}
不仅仅搜出了 江汉 相关的, 而且把 湖北省 武 汉 市 的汉字 相关的 也搜了出来, 这就是全文检索, 我们会对text文本进行分词,然后存储的就是 湖 北 省 武 汉 市 这样一个一个词的 倒排索引 ,所以ES 会帮我们查出来 %江% , %汉% 所有相关的数据 进行查询

1.4 短语匹配 match_phrase
如果不想全文索引, 不是一个字一个字的匹配, 而是把这个词当作关键字去查询 只需要江 match 改为 match_phrase 即可, 我们在看一下结果
get /test/_search
{
"query":{
"match_phrase": {
"address": "江汉"
}
}
}
查询结果 只有3条, 全都是 江汉 相关的, 不会再有 武 汉 的汉 字相关的数据结果, 就是我们要的结果

1.5 from,to 分页查询
DSL 语法中 分页查询,需要参数 from, to 指定 页码,from 从0开始
#分页查询 从from=0 页开始 每页 size=2
get /test/_search
{
"query":{
"match": {
"address": "湖北省"
}
},
"from":0,
"size":2
}
查询结果 8条记录, 每页只有2条数据, 顺序是 id=5 和 id=2的 两条数据

1.6 order 结果排序
ES搜索进行排序都是内存排序的, 指定 sort 排序 用 order 指定字段 及升降规则 即可 , 注意 order的字段 类型不能是 文本
# 取湖北省关键字的地址 , 0页开始, 每页 3条, 按照 年龄age 降序 排列
get /test/_search
{
"query":{
"match": {
"address": "湖北省"
}
},
"from":0,
"size":3,
"sort":{
"age":"desc"
}
}
可以看到查询结果的确是 降序,且每页3条

1.7 查询指定列结果 _source
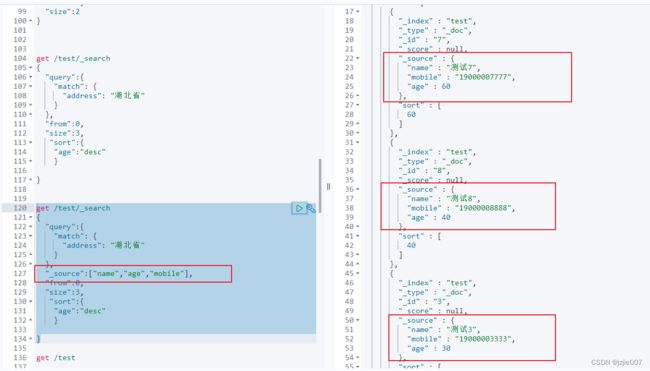
DSL 语法中 可以指定查询指定列 ,比如 只想要 name,age,mobile 信息,可以指定 查询结果列
# 查询指定列
get /test/_search
{
"query":{
"match": {
"address": "湖北省"
}
},
"_source":["name","age","mobile"],
"from":0,
"size":3,
"sort":{
"age":"desc"
}
}
查询结果,可以看到结果只有3列, 就是查询指定的结果列
2.ElasticSearch 高级查询进阶
2.1 And 且条件,多条件查询
DSL 语法中 查询And 操作嵌套有点深… 可以通过 bool操作 然后把几个查询 如 must (And), must_not (必须不), should (or)条件 组合起来
# 查询多个条件 And操作 ,查询 年龄是20, 且 性别是男 的 员工 使用 must
# bool 内 must 嵌套 match sex:男, match:age:20
get /test/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"sex": "男"
}
},
{
"match": {
"age": "20"
}
}
]
}
}
}
查询结果只有1条 既是男生,年龄又是20的员工

2.2 Or 或条件,多条件查询
DSL 语法中 查询Or和And类似 , 可以把 bool操作 的must (And) 换成 should (or)条件 即可
# 查询多个条件 or操作 ,查询 年龄是20, 或者 性别是男 的 员工 使用 should
# bool 内 should 嵌套 match sex:男, match:age:20
get /test/_search
{
"query":{
"bool": {
"should": [
{
"match": {
"sex": "男"
}
},
{
"match": {
"age": "20"
}
}
]
}
}
}
查询结果有5条 是男生,或者 年龄是20的员工,任意一条满足即可满足查询结果

2.3 大于,小于 条件,多条件查询
DSL 语法中 查询比较操作 使用 bool 加上 filter 过滤, 可以通过 filter 的range 操作 把需要的字段 field 的 数字过滤出来
gt 大于, gte 大于等于, lt 小于, lte 小于等于
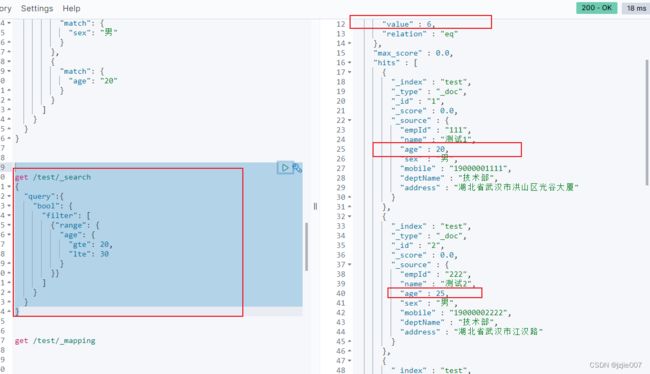
# 查询 年龄在20-50 之间的员工 大
# bool 内 filter 嵌套 range : age >= 20 且 age <=30 的员工
get /test/_search
{
"query":{
"bool": {
"filter": [
{"range": {
"age": {
"gte": 20,
"lte": 30
}
}}
]
}
}
}
查询结果6个, 然后年龄 大于等于 20, 小于等于 30 的员工
2.3 大于,小于 条件 且 And 多条件查询
如果要把 And 和 大于小于条件一期使用, 我们应该如何操作? 比如我要查找 部门: 技术部, 男生, 且 年龄在 20-25之间的这么多条件 该如何操作
需要分层 首先 最外层 query
内层 bool 条件 ,注意 must 和 filter 是同级别的
然后 must 操作 match: deptName=技术部, match:sex=男
然后 filter 操作 range : age (20-25)
# query 外层查询
# bool 内 嵌套 must match 多字段And
# bool 内 嵌套 filter range : age >= 20 且 age <=25 的员工
get /test/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"deptName":"技术部"
}
},
{
"match": {
"sex":"男"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 20,
"lte": 25
}
}
}
]
}
}
}
查询结果2个
技术部 且是 男生的 且 年龄 大于等于 20, 小于等于 25 的员工

2.4 聚合查询 group count 累加
DSL 语法中 允许对文档进行统计聚合操作,类似Mysql的GroupBy 操作, 如累加求和, 求 最大值,最小值等
# 聚合 所有age相同的记录 , age_group 是自定义的分组名, terms是分组, field是字段, size 是聚合后展示多少条记录
get /test/_search
{
//聚合操作
"aggs":{
"age_count":{
"terms": {
"field": "age",
"size": 10
}
}
}
}
查询结果5个, 20年龄的有3个, 30的有2个,25的有1个 等等结果

2.5 聚合查询 取最大值, 最小值
DSL 语法中 允许对文档进行统计聚合操作 , 求最大值
# 聚合 所有age 记录 , age_max是自定义的分组名, max是操作, field是字段, max没有size字段
get /test/_search
{
//聚合操作
"aggs":{
"age_max":{
"max": {
"field": "age"
}
}
}
}
查询结果1个 ,最大值为 age=60

取最小值
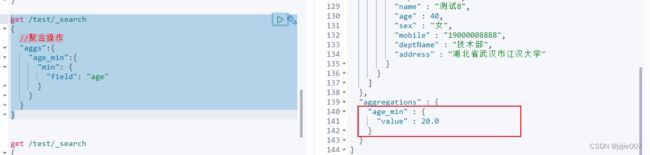
get /test/_search
{
//聚合操作
"aggs":{
"age_min":{
"min": {
"field": "age"
}
}
}
}
最小值只有1个, 年龄age=20
2.6 聚合查询 Sum求和,Avg求平均
DSL 语法中 允许对文档进行统计聚合操作,类似Mysql的GroupBy 操作, 如sum求和, avg求平均
# 聚合 所有age的记录 , age_sum 是自定义的分组名, sum是操作, field是字段
get /test/_search
{
"aggs":{
"age_sum":{
"sum": {
"field": "age"
}
}
}
}
查询结果1个,年龄之和为 245.0

求平均值
get /test/_search
{
"aggs":{
"age_avg":{
"avg": {
"field": "age"
}
}
}
}
查询结果 1个, 平均年龄 30.625

至此 我们已经基本的查询命令已经介绍完毕, 下一篇 介绍下ES索引的映射, 就是全文检索,短语检索是怎么区分配置的