2019独角兽企业重金招聘Python工程师标准>>> 
实验平台:操作系统:CentOS 7
软件链接(官网):https://www.elastic.co/products
Elasticsearch介绍
ELK由Elasticsearch、Logstash和Kibana三部分组件组成;他们都是开源免费的工具。简述如下:
Elasticsearch是个开源分布式搜索引擎,特点网上一搜到处是:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等 。
Logstash可以对你的日志进行收集、分析,并将其存储供以后使用(Cloudera的flume也差不多是这些功能)
kibana 为 Logstash 和 ElasticSearch 提供的日志分析的 Web 界面,帮助汇总、分析和搜索重要数据日志
Elasticsearch是一个实时分布式搜索和分析引擎。 它让你以前所未有的速度处理大数据增添可能性。它用于全文搜索、结构化搜索、分析以及将这三者混合使用。
Elasticsearch常常被应用在数据中心的实时协议分析和安全威胁检测,如apache、nginx、操作系统、网络流量等日志的分析,快速定位攻击位置,威胁预警等。
ElasticSearch 提供了一套基于restful风格的全文检索服务组件。前身是compass,直到2010被一家公司接管进行维护,开始商业化,并提供了ElasticSearch 一些相关的产品,包括大家比较熟悉的 kibana、logstash 以及 ElasticSearch 的一些组件,比如 安全组件shield 。当前最新的EElasticSearch 版本为 5.1.1 ,比较应用广泛的为2.X,直到 2016-12 推出了5.x 版本 ,将版本号调为 5.X 。这是为了和 kibana 和 logstash 等产品版本号进行统一 ElasticSearch 。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Filebeat隶属于Beats。目前Beats包含四种工具:
-
- Packetbeat(搜集网络流量数据)
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat(搜集文件数据)
- Winlogbeat(搜集 Windows 事件日志数据)
官方文档:
Filebeat:
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/5.6/index.html
Logstash:
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/5.6/index.html
Kibana:
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/5.5/index.html
Elasticsearch:
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html
elasticsearch中文社区:
https://elasticsearch.cn/
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
ELK是由kibana、logstash 以及 ElasticSearch 组成
ElasticSearch 是一个开源分布式搜索引型、特点:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载,官网:https://www.elastic.co/。提供一个分布式日志存储+搜索引型;
logstash 是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用,负责收集客户端服务器所有的日志(Nginx、内核、mysql、java日志、APP日志);
kibana也是一个完全开源的工具,他可以为Logstash 和ElasticSearch提供的日志分析友好的web界面,提供了一个开源WEB访问平台,供用户、管理员更加便捷操作,基于WEB方式更加的简单;
Logstash 和ElasticSearch是使用Javay语言编写,而kibana使用node.js框架,在配置ELK环境要保证系统有JAVA JDk开发库
ES集群组件介绍:集群(duster),节点(node), shard(primary, replica)
集群有状态:green, red, yellow各自含义、监 听端口、建立通信机制、节点通信等
Logstash四类API:检查集睬节点、索引等健康与否,以及获取其相应状态;管理 集群、节点、索引及元数据;执行CRUD操作;执行高级操作,例如 Paging, Filtering 等。
Elasticsearch 应用领域
一、是搜索领域,相对于solr,真正的后起之秀,成为很多搜索系统的不二之选。
二、是Json文档数据库,相对于MongoDB,读写性能更佳,而且支持更丰富的地理位置查询以及数字、文本的混合查询等。
三、是时序数据分析处理,目前是日志处理、监控数据的存储、分析和可视化方面做得非常好,可以说是该领域的引领者了。
- ELK平台产生背景
- 运维日常工作,主要保证WEB网站、数据库服务器、应用服务器高效稳定的运行;
- 当WEB网站、数据库、应用服务器宕机或者异常,需要运维、开发去登录服务器后台查看日志;
- 当服务器数量很多,日志查看非常不方便,不可能给开发人员root权限,普通查看日志的权限;
- 开发想看WEB、JAVA、Nginx、MYSQL、Redis、内核日志,每台服务器创建开发账号,专门用于查看服务器日志;
- 引入日志管理服务器,将所有的服务器日志统一的集中管理;
- 通过服务器WEB日志,分析用户访问行为,购买商品行为,包括用户喜好;
- 构建企业级日志收集平台,ELK日志平台,Rsyslog等;
- ELK软件概念
- 京东、百度、淘宝、BAT、中小型互联网公司使用ELK平台;
- ELK开源免费的实时日志分布式平台,对其二次开发;
- 大型互联网公司都是基于ELK做二次开发,满足公司内部的需求;
- 个人、中小企业推荐使用原生的ELK平台,满足你的需求;
- ELK分布式日志收集、展示平台,是由三个软件组成;
- ElasticSearch,提供一个分布式日志存储+搜索引擎;
- Logstash,负责收集客户端服务器所有日志(Nginx、内核、MYSQL、JAVA日志、APP日志);
- Kibana,提供了一个开源WEB访问平台,供用户、管理员更加便捷操作,基于WEB方式更加的简单;
ELK软件工作原理

ELK工作流程
(1)、通过 Logstash 收集客户端APP的日志数据,将所有的日志过滤出来,存入ElasticSearch搜索引型里,然后通过 kibanaGUI在WEB前端展示给用户,用户也可以加入redis通过队列
(2)、Logstash 包含Index和Agent(shipper),Agent负责客户端监控和过滤日志,而Index负责收集日志并将日志交给ElasticSearch,ElasticSearch将日志存储到本地,建立索引、提供搜索,kibana可以从ES集群中获取想要的日志信息
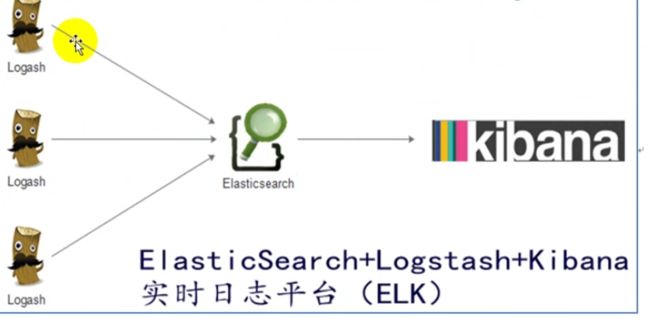
ELK架构图:
架构图一:

这是最简单的一种ELK架构方式。优点是搭建简单,易于上手。缺点是Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。
此架构由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch将数据以分片的形式压缩存储并提供多种API供用户查询,操作。用户亦可以更直观的通过配置Kibana Web方便的对日志查询,并根据数据生成报表。
架构图二:

此种架构引入了消息队列机制,位于各个节点上的Logstash Agent先将数据/日志传递给Kafka(或者Redis),并将队列中消息或数据间接传递给Logstash,Logstash过滤、分析后将数据传递给Elasticsearch存储。最后由Kibana将日志和数据呈现给用户。因为引入了Kafka(或者Redis),所以即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
架构图三:
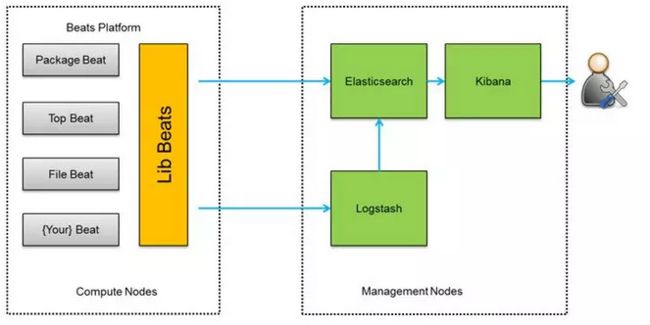
此种架构将收集端logstash替换为beats,更灵活,消耗资源更少,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。
Filebeat工作原理:
Filebeat由两个主要组件组成:prospectors 和 harvesters。这两个组件协同工作将文件变动发送到指定的输出中。
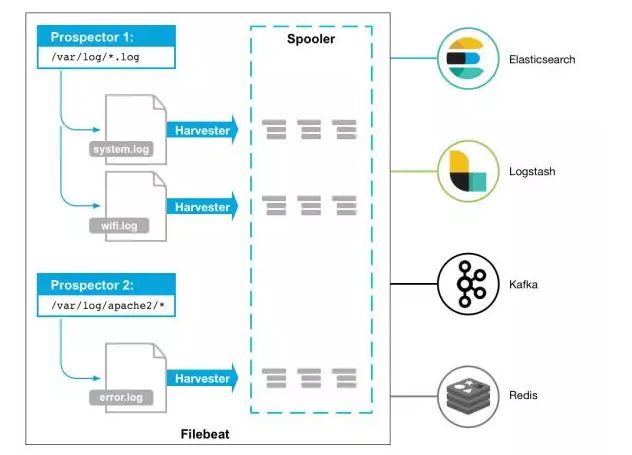
Harvester(收割机):负责读取单个文件内容。每个文件会启动一个Harvester,每个Harvester会逐行读取各个文件,并将文件内容发送到制定输出中。Harvester负责打开和关闭文件,意味在Harvester运行的时候,文件描述符处于打开状态,如果文件在收集中被重命名或者被删除,Filebeat会继续读取此文件。所以在Harvester关闭之前,磁盘不会被释放。默认情况filebeat会保持文件打开的状态,直到达到close_inactive(如果此选项开启,filebeat会在指定时间内将不再更新的文件句柄关闭,时间从harvester读取最后一行的时间开始计时。若文件句柄被关闭后,文件发生变化,则会启动一个新的harvester。关闭文件句柄的时间不取决于文件的修改时间,若此参数配置不当,则可能发生日志不实时的情况,由scan_frequency参数决定,默认10s。Harvester使用内部时间戳来记录文件最后被收集的时间。例如:设置5m,则在Harvester读取文件的最后一行之后,开始倒计时5分钟,若5分钟内文件无变化,则关闭文件句柄。默认5m)。
Prospector(勘测者):负责管理Harvester并找到所有读取源。
| 1 2 3 4 |
|
Prospector会找到/apps/logs/*目录下的所有info.log文件,并为每个文件启动一个Harvester。Prospector会检查每个文件,看Harvester是否已经启动,是否需要启动,或者文件是否可以忽略。若Harvester关闭,只有在文件大小发生变化的时候Prospector才会执行检查。只能检测本地的文件。
Filebeat如何记录文件状态:
将文件状态记录在文件中(默认在/var/lib/filebeat/registry)。此状态可以记住Harvester收集文件的偏移量。若连接不上输出设备,如ES等,filebeat会记录发送前的最后一行,并再可以连接的时候继续发送。Filebeat在运行的时候,Prospector状态会被记录在内存中。Filebeat重启的时候,利用registry记录的状态来进行重建,用来还原到重启之前的状态。每个Prospector会为每个找到的文件记录一个状态,对于每个文件,Filebeat存储唯一标识符以检测文件是否先前被收集。
Filebeat如何保证事件至少被输出一次:
Filebeat之所以能保证事件至少被传递到配置的输出一次,没有数据丢失,是因为filebeat将每个事件的传递状态保存在文件中。在未得到输出方确认时,filebeat会尝试一直发送,直到得到回应。若filebeat在传输过程中被关闭,则不会再关闭之前确认所有时事件。任何在filebeat关闭之前为确认的时间,都会在filebeat重启之后重新发送。这可确保至少发送一次,但有可能会重复。可通过设置shutdown_timeout 参数来设置关闭之前的等待事件回应的时间(默认禁用)。
Logstash工作原理:
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。

Input:输入数据到logstash。
一些常用的输入为:
file:从文件系统的文件中读取,类似于tial -f命令
syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
redis:从redis service中读取
beats:从filebeat中读取
Filters:数据中间处理,对数据进行操作。
一些常用的过滤器为:
grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。内置120多个解析语法。
官方提供的grok表达式:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
grok在线调试:https://grokdebug.herokuapp.com/
mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
drop:丢弃一部分events不进行处理。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
Outputs:outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。
一些常见的outputs为:
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。
Codecs:codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。
一些常见的codecs:
json:使用json格式对数据进行编码/解码。
multiline:将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息。
更多介绍:http://www.cnblogs.com/aresxin/p/8035137.html
使用案例:
1.维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-as-you-type)和搜索纠错(did-youmean)等搜索建议功能。
2.英国卫报使用Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表 的文章的回应。
3.StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。
4.Github使用Elasticsearch检索1300亿行的代码。
Elasticsearch 集群架构
节点(Node):物理概念,一个运行的Elasticearch实例,一般是一台机器上的一个进程。
索引(Index),逻辑概念,包括配置信息mapping和倒排正排数据文件,一个索引的数据文件可能会分布于一台机器,也有可能分布于多台机器。索引的另外一层意思是倒排索引文件。
分片(Shard):为了支持更大量的数据,索引一般会按某个维度分成多个部分,每个部分就是一个分片,分片被节点(Node)管理。一个节点(Node)一般会管理多个分片,这些分片可能是属于同一份索引,也有可能属于不同索引,但是为了可靠性和可用性,同一个索引的分片尽量会分布在不同节点(Node)上。分片有两种,主分片和副本分片。
副本(Replica):同一个分片(Shard)的备份数据,一个分片可能会有0个或多个副本,这些副本中的数据保证强一致或最终一致。
图形表示:
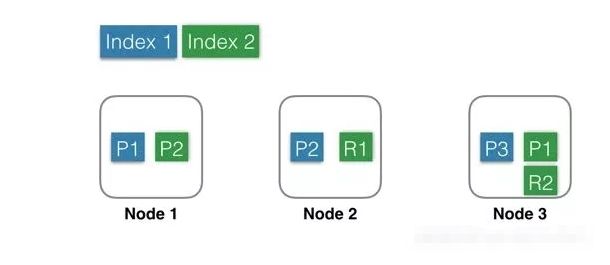
Index 1:蓝色部分,有3个shard,分别是P1,P2,P3,位于3个不同的Node中,这里没有Replica。
Index 2:绿色部分,有2个shard,分别是P1,P2,位于2个不同的Node中。并且每个shard有一个replica,分别是R1和R2。基于系统可用性的考虑,同一个shard的primary和replica不能位于同一个Node中。这里Shard1的P1和R1分别位于Node3和Node2中,如果某一刻Node2发生宕机,服务基本不会受影响,因为还有一个P1和R2都还是可用的。因为是主备架构,当主分片发生故障时,需要切换,这时候需要选举一个副本作为新主,这里除了会耗费一点点时间外,也会有丢失数据的风险。
Index流程
建索引(Index)的时候,一个Doc先是经过路由规则定位到主Shard,发送这个doc到主Shard上建索引,成功后再发送这个Doc到这个Shard的副本上建索引,等副本上建索引成功后才返回成功。
在这种架构中,索引数据全部位于Shard中,主Shard和副本Shard各存储一份。当某个副本Shard或者主Shard丢失(比如机器宕机,网络中断等)时,需要将丢失的Shard在其他Node中恢复回来,这时候就需要从其他副本(Replica)全量拷贝这个Shard的所有数据到新Node上构造新Shard。这个拷贝过程需要一段时间,这段时间内只能由剩余主副本来承载流量,在恢复完成之前,整个系统会处于一个比较危险的状态,直到failover结束。
这里就体现了副本(Replica)存在的一个理由,避免数据丢失,提高数据可靠性。副本(Replica)存在的另一个理由是读请求量很大的时候,一个Node无法承载所有流量,这个时候就需要一个副本来分流查询压力,目的就是扩展查询能力。
角色部署方式
接下来再看看角色分工的两种不同方式:

Elasticsearch支持上述两种方式:
混合部署(左图):
1.默认方式。
2.不考虑MasterNode的情况下,还有两种Node,Data Node和Transport Node,这种部署模式下,这两种不同类型Node角色都位于同一个Node中,相当于一个Node具备两种功能:Data和Transport。
3.当有index或者query请求的时候,请求随机(自定义)发送给任何一个Node,这台Node中会持有一个全局的路由表,通过路由表选择合适的Node,将请求发送给这些Node,然后等所有请求都返回后,合并结果,然后返回给用户。一个Node分饰两种角色。
4.好处就是使用极其简单,易上手,对推广系统有很大价值。最简单的场景下只需要启动一个Node,就能完成所有的功能。
5.缺点就是多种类型的请求会相互影响,在大集群如果某一个Data Node出现热点,那么就会影响途经这个Data Node的所有其他跨Node请求。如果发生故障,故障影响面会变大很多。
6.Elasticsearch中每个Node都需要和其余的每一个Node都保持13个连接。这种情况下,每个Node都需要和其他所有Node保持连接,而一个系统的连接数是有上限的,这样连接数就会限制集群规模。
7.还有就是不能支持集群的热更新。
分层部署(右图):
1.通过配置可以隔离开Node。
2.设置部分Node为Transport Node,专门用来做请求转发和结果合并。
其他Node可以设置为DataNode,专门用来处理数据。
3.缺点是上手复杂,需要提前设置好Transport的数量,且数量和Data Node、流量等相关,否则要么资源闲置,要么机器被打爆。
4.好处就是角色相互独立,不会相互影响,一般Transport Node的流量是平均分配的,很少出现单台机器的CPU或流量被打满的情况,而DataNode由于处理数据,很容易出现单机资源被占满,比如CPU,网络,磁盘等。独立开后,DataNode如果出了故障只是影响单节点的数据处理,不会影响其他节点的请求,影响限制在最小的范围内。
5.角色独立后,只需要Transport Node连接所有的DataNode,而DataNode则不需要和其他DataNode有连接。一个集群中DataNode的数量远大于Transport Node,这样集群的规模可以更大。另外,还可以通过分组,使Transport Node只连接固定分组的DataNode,这样Elasticsearch的连接数问题就彻底解决了。
6.可以支持热更新:先一台一台的升级DataNode,升级完成后再升级Transport Node,整个过程中,可以做到让用户无感知。
上面介绍了Elasticsearch的部署层架构,不同的部署方式适合不同场景,需要根据自己的需求选择适合的方式。
Elasticsearch 数据层架构
数据存储
Elasticsearch的Index和meta,目前支持存储在本地文件系统中,同时支持niofs,mmap,simplefs,smb等不同加载方式,性能最好的是直接将索引LOCK进内存的MMap方式。默认,Elasticsearch会自动选择加载方式,另外可以自己在配置文件中配置。这里有几个细节,具体可以看官方文档。
索引和meta数据都存在本地,会带来一个问题:当某一台机器宕机或者磁盘损坏的时候,数据就丢失了。为了解决这个问题,可以使用Replica(副本)功能。
副本(Replica)
可以为每一个Index设置一个配置项:副本(Replicda)数,如果设置副本数为2,那么就会有3个Shard,其中一个是PrimaryShard,其余两个是ReplicaShard,这三个Shard会被Mater尽量调度到不同机器,甚至机架上,这三个Shard中的数据一样,提供同样的服务能力。
副本(Replica)的目的有三个:
-
保证服务可用性:当设置了多个Replica的时候,如果某一个Replica不可用的时候,那么请求流量可以继续发往其他Replica,服务可以很快恢复开始服务。
-
保证数据可靠性:如果只有一个Primary,没有Replica,那么当Primary的机器磁盘损坏的时候,那么这个Node中所有Shard的数据会丢失,只能reindex了。
-
提供更大的查询能力:当Shard提供的查询能力无法满足业务需求的时候, 可以继续加N个Replica,这样查询能力就能提高N倍,轻松增加系统的并发度。
问题
上面说了一些优势,这种架构同样在一些场景下会有些问题。
1.Elasticsearch采用的是基于本地文件系统,使用Replica保证数据可靠性的技术架构,这种架构一定程度上可以满足大部分需求和场景,但是也存在一些遗憾:
2.Replica带来成本浪费。为了保证数据可靠性,必须使用Replica,但是当一个Shard就能满足处理能力的时候,另一个Shard的计算能力就会浪费。
3.Replica带来写性能和吞吐的下降。每次Index或者update的时候,需要先更新Primary Shard,更新成功后再并行去更新Replica,再加上长尾,写入性能会有不少的下降。
4.当出现热点或者需要紧急扩容的时候动态增加Replica慢。新Shard的数据需要完全从其他Shard拷贝,拷贝时间较长。
5.上面介绍了Elasticsearch数据层的架构,以及副本策略带来的优势和不足,下面简单介绍了几种不同形式的分布式数据系统架构。
分布式系统
第一种:基于本地文件系统的分布式系统
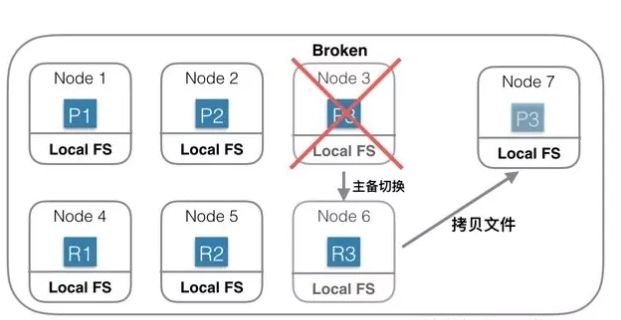
图中是一个基于本地磁盘存储数据的分布式系统。Index一共有3个Shard,每个Shard除了Primary Shard外,还有一个Replica Shard。当Node 3机器宕机或磁盘损坏的时候,首先确认P3已经不可用,重新选举R3位Primary Shard,此Shard发生主备切换。然后重新找一台机器Node 7,在Node7 上重新启动P3的新Replica。由于数据都会存在本地磁盘,此时需要将Shard 3的数据从Node 6上拷贝到Node7上。如果有200G数据,千兆网络,拷贝完需要1600秒。如果没有replica,则这1600秒内这些Shard就不能服务。
为了保证可靠性,就需要冗余Shard,会导致更多的物理资源消耗。
这种思想的另外一种表现形式是使用双集群,集群级别做备份。
在这种架构中,如果你的数据是在其他存储系统中生成的,比如HDFS/HBase,那么你还需要一个数据传输系统,将准备好的数据分发到相应的机器上。
这种架构中为了保证可用性和可靠性,需要双集群或者Replica才能用于生产环境,优势和副作用在上面介绍Elasticsearch的时候已经介绍过了,这里就就不赘述了。
Elasticsearch使用的就是这种架构方式。
第二种:基于分布式文件系统的分布式系统(共享存储)

针对第一种架构中的问题,另一种思路是:存储和计算分离。
第一种思路的问题根源是数据量大,拷贝数据耗时多,那么有没有办法可以不拷贝数据?为了实现这个目的,一种思路是底层存储层使用共享存储,每个Shard只需要连接到一个分布式文件系统中的一个目录/文件即可,Shard中不含有数据,只含有计算部分。相当于每个Node中只负责计算部分,存储部分放在底层的另一个分布式文件系统中,比如HDFS。
上图中,Node 1 连接到第一个文件;Node 2连接到第二个文件;Node3连接到第三个文件。当Node 3机器宕机后,只需要在Node 4机器上新建一个空的Shard,然后构造一个新连接,连接到底层分布式文件系统的第三个文件即可,创建连接的速度是很快的,总耗时会非常短。
这种是一种典型的存储和计算分离的架构,优势有以下几个方面:
-
在这种架构下,资源可以更加弹性,当存储不够的时候只需要扩容存储系统的容量;当计算不够的时候,只需要扩容计算部分容量。
-
存储和计算是独立管理的,资源管理粒度更小,管理更加精细化,浪费更少,结果就是总体成本可以更低。
-
负载更加突出,抗热点能力更强。一般热点问题基本都出现在计算部分,对于存储和计算分离系统,计算部分由于没有绑定数据,可以实时的扩容、缩容和迁移,当出现热点的时候,可以第一时间将计算调度到新节点上。
这种架构同时也有一个不足:
访问分布式文件系统的性能可能不及访问本地文件系统。在上一代分布式文件系统中,这是一个比较明显的问题,但是目前使用了各种用户态协议栈后,这个差距已经越来越小了。
HBase使用的就是这种架构方式。
Solr也支持这种形式的架构。
需要三台机器:ES、kibana、logstash,分别在三台机器上面下载,
ES上面操作
[root@localhost ~]# tar xzf jdk-8u121-linux-x64.tar.gz
[root@localhost ~]# mkdir -p /usr/java/
[root@localhost ~]# mv jdk1.8.0_121/ /usr/java/
[root@localhost ~]# ll /usr/java/jdk1.8.0_121/
[root@localhost ~]# /usr/java/jdk1.8.0_121/bin/java -version #查看安装版本,

[root@localhost ~]# du -sh jdk-8u121-linux-x64.tar.gz
[root@localhost ~]# du -sh jdk-8u121-linux-x64

上面的操作,在Logstash操作
在文件末尾,添加红色字

[root@localhost ~]# source /etc/profile
[root@localhost ~]# java -version

ES上面操作
[root@localhost ~]# cd elk/
[root@localhost ~]# ls
[root@localhost ~]# tar -zxf elasticsearch-5.3.0.tar.ga
[root@localhost ~]# rm -rf /usr/local/elasticsearch/
[root@localhost ~]# ls
[root@localhost ~]# mv elasticsearch-5.3.0 /usr/local/elasticsearch
[root@localhost ~]# cd /usr/local/elasticsearch
[root@localhost ~]# ll

[root@localhost ~]#cd
[root@localhost ~]# useradd elk -s
[root@localhost ~]# chown -R elk.elk /usr/local/elasticsearch/
[root@localhost ~]# cd /usr/local/elasticsearch/
[root@localhost ~]# ls
[root@localhost ~]# su elk
[root@localhost ~]# pwd
[root@localhost ~]# ls
[root@localhost ~]# cd bin/
[root@localhost ~]#ls
[root@localhost ~]# ./elasticsearch -d #启动

原因内存不足
解决办法:
[root@localhost ~]# cd ..
[root@localhost ~]# ls
[root@localhost ~]# cd config/
[root@localhost ~]# ls
[root@localhost ~]# pwd
[root@localhost ~]# vim jvm.options
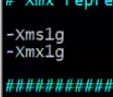
修改成一个G
[root@localhost ~]# /usr/local/elasticsearch/bin/elasticsearch/ -d #启动
[root@localhost ~]# ps -ef | ggrep java #说明elk启动了

[root@localhost ~]# tail -fn 10 logs/elasticsearch.log 显示两个端口,9200和9300

[root@localhost ~]# ps -ef | grep java

[root@localhost ~]# pkill -9 1336
[root@localhost ~]# ps -ef | grep java #查看有没有杀掉
[root@localhost ~]# cd config/
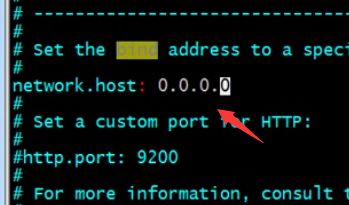
[root@localhost ~]# vim elasticsearch.yml
搜索/bind,把192修改成四个零
[root@localhost ~]# /usr/local/elasticsearch/bin/elasticsearch/ -d #启动
[root@localhost ~]#!tail #发现很多模块

在kib上面操作
[root@localhost ~]# cd elk/
[root@localhost ~]# ls
[root@localhost ~]# tar zxf kibana-5.3.0-linux-x86_64.tar.gz
[root@localhost ~]# ls
![]()
[root@localhost ~]# rm -rf /usr/local/kibana/
[root@localhost ~]# mv libana-5.3.0-linux-x86_64 /usr/local/kibana
[root@localhost ~]# cd /usr/local/libana
[root@localhost ~]#ls
[root@localhost ~]# cd config/
[root@localhost ~]# vim kibana.yml

localhost修改成四个零


[root@localhost ~]# cd ..
[root@localhost ~]# cd bin/
[root@localhost ~]# ls

[root@localhost ~]# nohup ./kibana & #放到后台
[root@localhost ~]# tail -fn 100 nohup.out
在Logstash
[root@localhost ~]# cd elk/
[root@localhost ~]#ls
[root@localhost ~]# tar zxf logstash-5.3.0.tar.gz
[root@localhost ~]# rm -rf /usr/local/logstach/
[root@localhost ~]# mv logstash-5.3.0 /usr/local/logstatsh
[root@localhost ~]# cd /usr/local/logstash/
[root@localhost ~]# ls
[root@localhost ~]# ll
[root@localhost ~]# cd bin/
[root@localhost ~]# cd ..
[root@localhost ~]# ls
[root@localhost ~]# mkdir etc
[root@localhost ~]# cd etc/
[root@localhost ~]# ls
[root@localhost ~]# vim 1.conf #在配置文件中,写一个收集日志,
input {
stdin{ }
}
output {
stdout {
codec => rubydebug {}
}
elasticsearch {
hosts => "192.168.1.161"} #IP是ES的
}
[root@localhost ~]# ll
[root@localhost ~]# ../bin/logstash -f 1.conf
在kibana上面操作
[root@localhost ~]# netstat -lntp | grep 5601
[root@localhost ~]# netstat -lntp | grep 5601 --color
在Logstash
[root@localhost ~]# ../bin/logstash -f 1.conf #启动配置i文件
在浏览器里面输入lkibana的IP 192.168.1.162

在配置文件里面输入hellod world,然后回车,然后刷新页面

在ES
[root@localhost ~]# tail -fn 100 /usr/local/elasticsearch/log/elasticsearch.log
[root@localhost ~]#cd elasticsearch-head/
[root@localhost ~]# netstat lnt | grep 9100
[root@localhost ~]# nohup./node_modules/grunt/bin/grunt server &
刷新页面,IP是ES的

[root@localhost ~]# netstat lnt | grep 9200
[root@localhost ~]# /etc/init.d/iptables stop
[root@localhost ~]# sestatus
[root@localhost ~]# date
[root@localhost ~]# ntpdate cn.pool.ntp.org #同步时间,如果时间都不相同,都执行这一条目命令
[root@localhost ~]# ps -ef | grep java

[root@localhost ~]# kill -9 1495
[root@localhost ~]# !ps
[root@localhost ~]# su -elk
[root@localhost ~]# /usr/local/elasticsearch/elasticsearch -d
[root@localhost ~]# #看日志
kib操作
[root@localhost ~]# ps -ef | grep node
[root@localhost ~]# kill -9 1138

[root@localhost ~]# cd /ussr/local/kibana/bin/
[root@localhost ~]#ls
[root@localhost ~]# nohup ./kibana &
在Log
[root@localhost ~]# ../bin/logstash -f 1.conf
在浏览器刷新一下,如果连不上,说明有问题
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]#
ELK安装
1
环境说明
操作系统:Centos 7
软件链接(官网):https://www.elastic.co/products
2
安装步骤
创建账号
1.linux创建新用户
相关命令:adduser elkstack 、 passwd elkstack输入两次密码
2.为elkstack用户添加sudo权限
相关命令:visudo
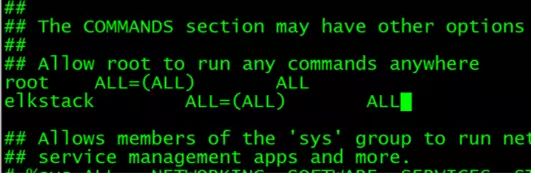
3、安装jdk1.8

4、安装elasticsearch
0.以普通用户登陆
1.解压elasticseach
![]()
2.解压文件移动到/opt目录下
![]()
3.更改elasticsearch目录所有者为elkstack
![]()
5、安装elasticsearch-servicewrapper
下载地址: https://github.com/elastic/elasticsearch-servicewrapper
0.解压elasticsearch-servicewrapper
![]()
1.移动到elasticsearch/bin/ 目录下
![]()
2.验证
a.启动elasticsearch

b. 测试ElasticSearch服务是否正常,预期返回200的状态码:
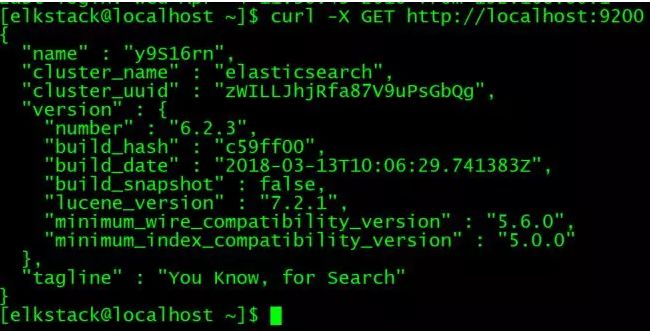
6、安装Logstash
0.安装

1.更改logstash所有权
![]()
2.简单测试Logstash服务是否正常,预期可以将输入内容以简单的日志形式打印在界面上:
/opt/logstash/bin/logstash -e 'input { stdin { } } output { stdout {} }'

7、安装Kibana
0.安装

1.更改logstash所有权
![]()
2.修改配置文件kibana/config/kibana.yml
elasticsearch.url: "http://localhost:9200"

server.host:"0.0.0.0"

3.运行
![]()
4.访问http://IP:5601,安装完成。
常见问题:

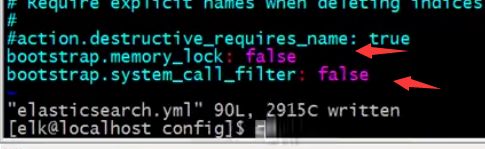
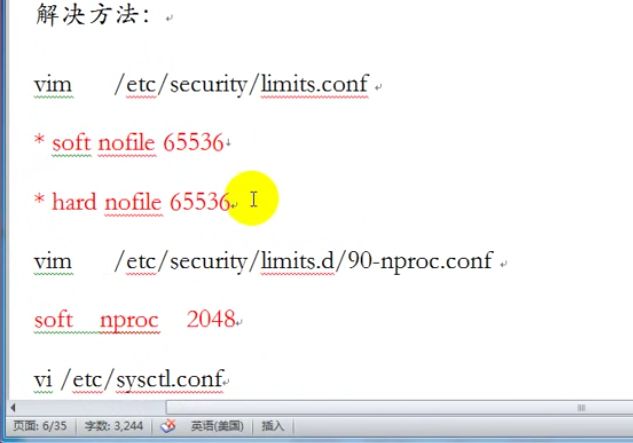
2、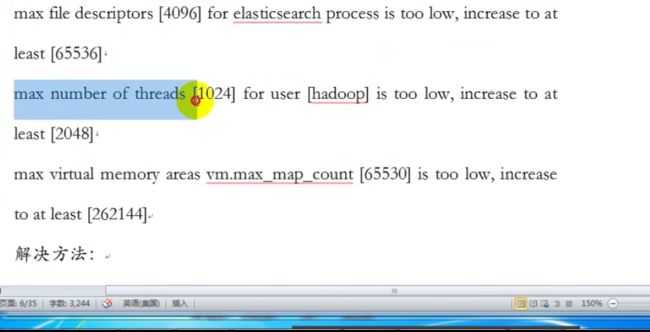

参考链接:https://mp.weixin.qq.com/s/gqxeNWjiVs2p0H9TCKWnEg
链接:
安装Elasticsearch及其遇到的坑 : https://mp.weixin.qq.com/s/vyBkKe9BNut6ocrGsnde9A
Elasticsearch 权威指南(中文版) :http://www.voidcn.com/course/project/mluqbg
ELK日志分析系统简介 : https://mp.weixin.qq.com/s/C0wldeFrHHQtLWJdgS0ryw
Elasticsearch 入门教程 : https://mp.weixin.qq.com/s/c_kJwGTYY6yJlULVCAhTlw
如何解决centos下root运行Elasticsearch异常 : https://www.jb51.net/os/RedHat/514009.html
ElasticSearch ——单台服务器部署多个节点:https://mp.weixin.qq.com/s/2wFT31RqGBRTIuVQy_wz3Q
用Elasticsearch构建电商搜索平台:https://mp.weixin.qq.com/s/QoLQXZqi4P0VC3C7Ea86tA
ELK系列:https://www.aliyun.com/jiaocheng/topic_23933_1.html
通过ELK快速搭建一个你可能需要的集中化日志平台l: https://mp.weixin.qq.com/s/kAwpekl-DGCIulWoLCedxw
10 分钟快速搭建 ELK 日志分析系统:http://mp.weixin.qq.com/s/CBSoBXmQbRsJZs2N5-qjyg
快速搭建企业级ELK日志分析系统:http://mp.weixin.qq.com/s/VBl45xLZq0l1_0bj7s-epQ
ELK日志分析集群部署笔记 : http://blog.51cto.com/zlyang/1737622
Elasticsearch快速搭建食谱搜索系统 : https://mp.weixin.qq.com/s/kB_BDQKE8rhQq1TmpKPbFA
Elasticsearch面试题 : https://mp.weixin.qq.com/s/XEYsgYOcI7Wv0PZq4Sf-Hw
用Ansible部署ELK STACK:http://mp.weixin.qq.com/s/hnAv5lrAHR-IZesPeOvLGA
保护好你的Elasticsearch全文检索库 : https://www.csharpkit.com/2017-11-29_58506.html
基于Elasticsearch搜索平台设计 : https://www.csharpkit.com/2017-10-15_51699.html
【通天塔之日志分析平台】壹 ELK 环境搭建 : https://wdxtub.com/2016/11/19/babel-log-analysis-platform-1/
【通天塔之日志分析平台】贰 Kafka 缓冲区 : https://wdxtub.com/2016/11/19/babel-log-analysis-platform-2/
【通天塔之日志分析平台】叁 监控、安全、报警与通知 : https://wdxtub.com/2016/11/19/babel-log-analysis-platform-3/
【通天塔之日志分析平台】肆 从单机到集群 : https://wdxtub.com/2016/11/19/babel-log-analysis-platform-4/
【通天塔之日志分析平台】伍 Logstash 技巧指南 : https://wdxtub.com/2016/11/19/babel-log-analysis-platform-5/
【通天塔之日志分析平台】陆 Elasticsearch 技巧指南 : https://wdxtub.com/2016/11/19/babel-log-analysis-platform-6/
【通天塔之日志分析平台】柒 Kibana 技巧指南 : https://wdxtub.com/2016/11/19/babel-log-analysis-platform-7/
【通天塔之日志分析平台】捌 实例:接入外部应用日志 : https://wdxtub.com/2016/11/19/babel-log-analysis-platform-8/
Elasticsearch 集群指南 : https://wdxtub.com/2016/09/28/elasticsearch-cluster-guide/
Logstash 连接 Kafka 指南 : https://wdxtub.com/2016/08/18/logstash-kafka-guide/
Rsyslog 连接 Kafka 指南 : https://wdxtub.com/2016/08/17/rsyslog-kafka-guide/
Kafka 指南 : https://wdxtub.com/2016/08/15/kafka-guide/
Rsyslog + Logstash 日志传输指南 : https://wdxtub.com/2016/08/12/rsyslog-logstash-guide/
ELK 指南 : https://wdxtub.com/2016/07/26/elk-guide/

Elasticsearch 的聚合查询及过滤 : http://techlog.cn/article/list/10182851
kibana4 的安装、配置和使用 : http://techlog.cn/article/list/10182920
ELK在广告系统监控中的应用 及 Elasticsearch简介:https://mp.weixin.qq.com/s/i5DEmU7WKiQs-xa4COC6zQ
ELK日志分析系统简介:https://mp.weixin.qq.com/s/C0wldeFrHHQtLWJdgS0ryw
Elasticsearch 入门教程https://mp.weixin.qq.com/s/c_kJwGTYY6yJlULVCAhTlw
Elasticsearch基础教程(上):https://mp.weixin.qq.com/s/WKR2kboG-rjOdmjuMw4AhA
Elasticsearch基础教程(下):https://mp.weixin.qq.com/s/d88IXKd0L6VLwsGJK7cEfA
ELKstack 入门及使用 : http://techlog.cn/article/list/10182847

Elasticsearch专栏 : https://blog.csdn.net/column/details/elasticsearch-action.html

elasticsearch(一)---开始 : https://juejin.im/post/5b78e9606fb9a019d80a878f
elasticsearch(二)---基本数据操作 : https://juejin.im/post/5b79090d51882542f25a4de5
elasticsearch(三)---分布式集群 : https://juejin.im/post/5b7948c3e51d45388f7436b7
elasticsearch(四)---分布式文档存储 : https://juejin.im/post/5b796ea7e51d4538e018d55d
elasticsearch(五)---分布式搜索 : https://juejin.im/post/5b7b8268e51d4538a01ea7b6
elasticsearch(六)---索引管理 :https://juejin.im/post/5b7c10e7f265da436e74cadf
elasticsearch(七)---深入分片 : https://juejin.im/post/5b7e2a2c51882543113d80cc
全文检索引擎
全文检索引擎(一)---准备入坑 : https://juejin.im/post/5b768a12f265da28004ad632
全文检索引擎(二)---为何入坑 : https://juejin.im/post/5b768e3b6fb9a009820daf1c
全文检索引擎(三)---原理剖析 : https://juejin.im/post/5b7692b9518825330d64dade
全文检索引擎(四)---solr初体验 : https://juejin.im/post/5b77ac1a518825431079c3ee
全文检索引擎(五)---solr与mongodb同步 : https://juejin.im/post/5b77befcf265da4320088ba7
全文检索引擎(六)---elasticsearch初体验 : https://juejin.im/post/5b780db96fb9a019b8699a49
全文检索引擎(七)---solr vs es : https://juejin.im/post/5b783fd2f265da4328162eba
Elasticsearch 安装就这么简单 : https://juejin.im/post/5ab4496e518825556d0e0713
Kibana 简单入门教程 :https://mp.weixin.qq.com/s/eT1xrWDMmoqlZkEHqRcIuw
Logstash 简单入门教程 : https://mp.weixin.qq.com/s/Xfa73phV1fhYyN1wO4CNtw
大而全面|Logstash技术入门 : https://mp.weixin.qq.com/s/CrmDAkmoHWaC1uKDML0sDw
kibana 加安全校验 : https://mp.weixin.qq.com/s/FMB_c9rWvj7XsqXMQAzIYg
Service详解 : https://mp.weixin.qq.com/s/eCaquPSYTnVUTaD1YGxPbQ
(阿里云)ELK日志分析系统简介 : https://mp.weixin.qq.com/s/C0wldeFrHHQtLWJdgS0ryw
springboot 发送业务日志到elk : https://mp.weixin.qq.com/s/1AS3PWFnS1g7qNSFlS5LrA
使用Kibana 分析Nginx 日志并在 Dashboard上展示 : https://www.cnblogs.com/hanyifeng/p/5860731.html
利用 ELK系统分析Nginx日志并对数据进行可视化展示 : https://www.cnblogs.com/hanyifeng/p/5857875.html
Centos7 之安装Logstash ELK stack 日志管理系统 : https://www.cnblogs.com/hanyifeng/p/5509985.html
博森瑞 系列:
Kafka的安装与配置 : http://t.bosenrui.com/dev/da3be54fa6b1816486888aa73ab44b16.html
Kafka基本原理 : https://mp.weixin.qq.com/s/ZnWeFphfFF1hdltoRKmwGQ
Flume安装使用实录 : http://t.bosenrui.com/dev/a928ad4d34ce40f47763305859d46a6c.html
Sqoop安装与使用实录 : http://t.bosenrui.com/dev/a02f31ccbed134ac6d13fec24b016f1e.html
Azkaban安装实录 : http://t.bosenrui.com/dev/1c90859ca5a6af651ee7c3ae7166993d.html
亿级 Elasticsearch 性能优化荐 : http://blog.51cto.com/13527416/2132270
使用ElasticSearch踩过的坑 : https://www.jianshu.com/p/fa31f38d241e
用ElasticSearch监控MySQL : https://www.jianshu.com/p/8d25f02535f0
阿里云 ElasticSearch (2134篇) 系列: https://yq.aliyun.com/search?q=ElasticSearch
ElasticSearch ——结构化查询 : https://www.jianshu.com/p/e4f3f94728b1
ElasticSearch ——单台服务器部署多个节点 : https://www.jianshu.com/p/1ccc59dde56a
在 Python 中使用 Elasticsearch : https://www.jianshu.com/p/29dbcb4bfb0e
Elasticsearch + Kibana 集群环境搭建 : https://www.jianshu.com/p/1c8ba75b72c8
logstash mysql 准实时同步到 elasticsearch : https://www.jianshu.com/p/62433b9c5c96
ElasticSearch + xpack 使用.md : https://www.jianshu.com/p/0ab1741fd4bc
灵雀云到生产实践之ELK Stack : https://www.jianshu.com/p/9d83ad0cb65b
部署分布式ES-Kibana Server-Centos7 : http://www.pangxie.space/docker/1104
Kubernetes双向TLS配置-Centos7 : http://www.pangxie.space/docker/1164
搭建swarm集群(docker v1.12)-Centos7 : http://www.pangxie.space/docker/1061
部署分布式kubernetes(v1.3.x)-Centos7 : http://www.pangxie.space/docker/1055
搭建swarmkit集群-Centos7 : http://www.pangxie.space/docker/971
部署ELK-centos7 : http://www.pangxie.space/docker/527
互联网亿级日志实时分析平台ELK : https://mp.weixin.qq.com/s/BPUECpBGGIdOJ9CwprdS1g
ELKstack-Elasticsearch各类安装部署方法 : http://blog.51cto.com/vekergu/1784370
ElKstack-解决nginx日志url链接包含中文logstash报错问题 : http://blog.51cto.com/vekergu/1784562
ELKstack-logstash yum安装部署方法 : http://blog.51cto.com/vekergu/1784718
ELKstack-kibana yum安装部署方法 : http://blog.51cto.com/vekergu/1784719
ELKstack-logstash 使用技巧小计 : http://blog.51cto.com/vekergu/1785279
ELKstack-基于java工程tomcat应用日志处理过程-01 : http://blog.51cto.com/vekergu/1787449
ELKstack-基于java工程tomcat应用日志处理过程-02 : http://blog.51cto.com/vekergu/1787459
ES报错Result window is too large问题处理 荐 : http://blog.51cto.com/nolinux/1786656
ES使用脚本进行局部更新的排错记录 荐 : http://blog.51cto.com/nolinux/1775232
Elasticsearch6.2、head插件、x-pack安全模块(security机制)安装 : http://blog.51cto.com/ityunwei2017/2071014
ElasticSearch ——单台服务器部署多个节点 : https://www.jianshu.com/p/1ccc59dde56a
ElasticSearch + xpack 使用.md : https://www.jianshu.com/p/0ab1741fd4bc
logstash mysql 准实时同步到 elasticsearch : https://www.jianshu.com/p/62433b9c5c96
Elasticsearch + Kibana 集群环境搭建 : https://www.jianshu.com/p/1c8ba75b72c8
ELK安装文档及相关优化 : http://blog.51cto.com/youerning/1726338
使用kibana和elasticsearch日志实时绘制图表 荐 : http://blog.51cto.com/rfyiamcool/1421049
ElasticSearch : https://www.cnblogs.com/atomicbomb/tag/ElasticSearch/

原 ElasticSearch分片不均匀,集群负载不均衡 : https://blog.csdn.net/qq_20545159/article/details/80549335
从零开始搭建ELK+GPE监控预警系统 荐 : http://blog.51cto.com/itstyle/1983296
ELK之filebeat详解 : https://www.ixdba.net/archives/2018/01/1111.htm
Elastic stack ——X-Pack安装 : https://www.ixdba.net/archives/2017/11/822.htm
KAFKA 调优笔记 : https://www.ixdba.net/archives/2017/11/803.htm
ElasticSearch 5学习(1)——安装Elasticsearch、Kibana和X-Pack : https://www.ixdba.net/archives/2017/11/818.htm
http://blog.51cto.com/xpleaf/category33.html
ElasticSearch笔记整理(一):简介、REST与安装配置 : http://blog.51cto.com/xpleaf/2096306
ElasticSearch笔记整理(二):CURL操作、ES插件、集群安装与核心概念 : http://blog.51cto.com/xpleaf/2096385
ElasticSearch笔记整理(三):Java API使用与ES中文分词 : http://blog.51cto.com/xpleaf/2096854
ElasticSearch笔记整理(四):ElasticSearch Rest与Settings、M : http://blog.51cto.com/xpleaf/2096863
Elasticsearch:RestClient+SearchSourceBuilder使用案例 http://blog.51cto.com/xpleaf/2294268 :
elasticsearch入门 : https://mp.weixin.qq.com/s/g1w_UU7yk7jQO5pduBY_ew
ELK环境部署+监控Nginx日志 : https://mp.weixin.qq.com/s/X4nG8ysjHS16lnxwlR3tAw
ELK构架图 : https://www.processon.com/view/5cab6c95e4b031d02261289e
利用 ELK 搭建 Docker 容器化应用日志中心 : https://mp.weixin.qq.com/s/4XI2BaThlcVR8_z4f9AbbA
你头疼的ELK难题,本文几乎都解决了 : https://mp.weixin.qq.com/s/7gYVC9TsuoV4LYPGwJ5UHQ
搜索是神器Elasticsearch入门介绍 : https://mp.weixin.qq.com/s/PlQRorBV03oqcnjWvE-uRg
ELK日志平台高级案例,360企业内部监控实战!! : https://mp.weixin.qq.com/s/Sp7FvSrvp3aC3sUYsTmErA