机器学习(一) 从一个R语言案例学线性回归
写在前面的话 按照正常的顺序,本文应该先讲一些线性回归的基本概念,比如什么叫线性回归,线性回规的常用解法等。但既然本文名为《从一个R语言案例学会线性回归》,那就更重视如何使用R语言去解决线性回归问题,因此本文会先讲案例。
线性回归简介
如下图所示,如果把自变量(也叫independent variable)和因变量(也叫dependent variable)画在二维坐标上,则每条记录对应一个点。线性回规最常见的应用场景则是用一条直线去拟和已知的点,并对给定的x值预测其y值。而我们要做的就是找出一条合适的曲线,也就是找出合适的斜率及纵截矩。
SSE & RMSE
上图中的SSE指sum of squared error,也即预测值与实际值之差的平方和,可由此判断该模型的误差。但使用SSE表征模型的误差有些弊端,比如它依赖于点的个数,且不好定其单位。所以我们有另外一个值去称量模型的误差。RMSE(Root-Mean-Square Error)。$$RMSE=\sqrt{\frac{SSE}{N}}$$
由N将其标准化,并且其单位与变量单位相同。
$R^2$
在选择用于预测的直线时,我们可以使用已知记录的y值的平均值作为直线,如上图红线所示,这条线我们称之为baseline model。SST(total sum of squares)指是的baseline的SSE。用SSE表征模型好坏也有不便之处,比如给定SSE=10,我们并不知道这个模型是好还是好,因此我们引入另一个变量,$R^2$,定义如下:$$R^2 = 1 - \frac{SSE}{SST}$$
$R^2$用来表明我们所选的模型在baseline model的基础之上提升了多少(对于任意给定数据集,我们都可以用baseline作为模型,而事实上,我们总希望我们最后选出的模型在baseline基础之上有所提升),并且这个值的范围是[0,1]。$R^2=0$意味着它并未在baseline model的基础之上有所提升,而$R^2=1$(此时$SSE=0$)意味着一个一个非常完美的模型。
Adjusted $R^2$
在多元回归模型中,选用的feature越多,我们所能得到的$R^2$越大。所以$R^2$不能用于帮助我们在feature特别多时,选择合适的feature用于建模。因此又有了Adjusted $R^2$,它会补偿由feature增多/减少而引起的$R^2$的增加/减少,从而可通过它选择出真正适合用于建模的feature。
案例
许多研究表明,全球平均气温在过去几十年中有所升高,以此引起的海平面上升和极端天气频现将会影响无数人。本文所讲案例就试图研究全球平均气温与一些其它因素的关系。
读者可由此下载本文所使用的数据climate_change.csv。
https://courses.edx.org/c4x/MITx/15.071x_2/asset/climate_change.csv
此数据集包含了从1983年5月到2008年12月的数据。
本例我们以1983年5月到2006年12月的数据作为训练数据集,以之后的数据作为测试数据集。
数据
首先加载数据
temp <- read.csv("climate_change.csv")数据解释
- Year 年份 M
- Month 月份 T
- emp 当前周期内的全球平均气温与一个参考值之差
- CO2, N2O,CH4,CFC.11,CFC.12:这几个气体的大气浓度 Aerosols
模型选择
线性回归模型保留两部分。
- 选择目标feature。我们数据中,有多个feature,但并非所有的feature都对预测有帮助,或者并非所有的feature都需要一起工作来做预测,因此我们需要筛选出最小的最能预测出接近事实的feature组合。
- 确定feature系数(coefficient)。feature选出来后,我们要确定每个feature对预测结果所占的权重,这个权重即为coefficient
前向选择
- 以每个feature为模型,分别算出其Adjusted $R^2$,最后取使得Adjusted $R^2$最大的feature作为第一轮的feature,并记下这个最大Adjusted $R^2$
- 在其它未被使用的feature中选一个出来,与上轮作组合,并分别算出使其Adjusted $R^2$。若所有组合的Adjusted $R^2$都比上一轮小,则结束,以上一轮feature组合作为最组的model。否则选出使得Adjusted $R^2$最大的feature与上一轮的feature结合,作为本轮feature,并记下这个最大Adjusted $R^2$。
- 循环步骤2直到结束
后向选择
- 首先把所有feature作为第一个模型,并算出其Adjusted $R^2$。
- 在上一轮的feature组合中,分别去掉每个feature,并算出其Adjusted $R^2$,如果去掉任一一个feature都不能使得Adjusted $R^2$比上一轮大,则结束,取上一轮的feature组合为最终的model。否则取使得Adjusted $R^2$最大的组合作为本轮的结果,并记下对应的Adjusted $R^2$。
- 循环步骤2直到结束
结合实例选择模型
初始选择所有feature
选择所有feature作为第一个model1,并使用summary函数算出其Adjusted $R^2$为0.7371。
model1 <- lm(Temp ~ MEI + CO2 + CH4 + N2O + CFC.11 + CFC.12 + TSI + Aerosols, temp)
summary(model1)逐一去掉feature
在model1中去掉任一个feature,并记下相应的Adjusted $R^2$如下
| Feature | Adjusted $R^2$ |
|---|---|
| CO2 + CH4 + N2O + CFC.11 + CFC.12 + TSI + Aerosols | 0.6373 |
| MEI + CH4 + N2O + CFC.11 + CFC.12 + TSI + Aerosols | 0.7331 |
| MEI + CO2 + N2O + CFC.11 + CFC.12 + TSI + Aerosols | 0.738 |
| MEI + CO2 + CH4 + CFC.11 + CFC.12 + TSI + Aerosols | 0.7339 |
| MEI + CO2 + CH4 + N2O + CFC.12 + TSI + Aerosols | 0.7163 |
| MEI + CO2 + CH4 + N2O + CFC.11 + TSI + Aerosols | 0.7172 |
| MEI + CO2 + CH4 + N2O + CFC.11 + CFC.12 + Aerosols | 0.697 |
| MEI + CO2 + CH4 + N2O + CFC.11 + CFC.12 + TSI | 0.6883 |
本轮得到Temp ~ MEI + CO2 + N2O + CFC.11 + CFC.12 + TSI + Aerosols
从model2中任意去掉1个feature,并记下相应的Adjusted $R^2$如下
| Feature | Adjusted $R^2$ |
|---|---|
| CO2 + N2O + CFC.11 + CFC.12 + TSI + Aerosols | 0.6377 |
| MEI + N2O + CFC.11 + CFC.12 + TSI + Aerosols | 0.7339 |
| MEI + CO2 + CFC.11 + CFC.12 + TSI + Aerosols | 0.7346 |
| MEI + CO2 + N2O + CFC.12 + TSI + Aerosols | 0.7171 |
| MEI + CO2 + N2O + CFC.11 + TSI + Aerosols | 0.7166 |
| MEI + CO2 + N2O + CFC.11 + CFC.12 + Aerosols | 0.698 |
| MEI + CO2 + N2O + CFC.11 + CFC.12 + TSI | 0.6891 |
任一组合的Adjusted $R^2$都比上一轮小,因此选择上一轮的feature组合作为最终的模型,也即Temp ~ MEI + CO2 + N2O + CFC.11 + CFC.12 + TSI + Aerosols
由summary(model2)可算出每个feature的coefficient如下 。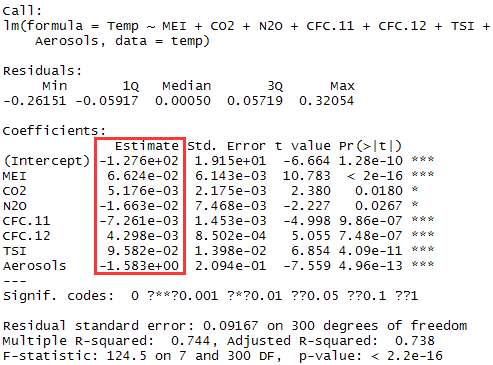
线性回归介绍
在线性回归中,数据使用线性预测函数来建模,并且未知的模型参数也是通过数据来估计。这些模型被叫做线性模型。最常用的线性回归建模是给定X值的y的条件均值是X的仿射函数。
线性回归是回归分析中第一种经过严格研究并在实际应用中广泛使用的类型。这是因为线性依赖于其未知参数的模型比非线性依赖于其位置参数的模型更容易拟合,而且产生的估计的统计特性也更容易确定。
上面这段定义来自于维基百科。
线性回归假设特征和结果满足线性关系。我们用$X_1,X_2..X_n$ 去描述feature里面的分量,比如$x_1$=房间的面积,$x_2$=房间的朝向,等等,我们可以做出一个估计函数: $$h(x)=h_θ(x)=θ_0+θ_1x_1+θ_2x_2$$
θ在这儿称为参数(coefficient),在这的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。如果我们令$x_0 = 1$,就可以用向量的方式来表示了: $$h_θ(x)=θ^TX$$
我们的程序也需要一个机制去评估我们θ是否比较好,所以说需要对我们做出的h函数进行评估,一般这个函数称为损失函数(loss function)或者错误函数(error function),也有叫代价函数(cost function)的。在本文中,我们称这个函数为J函数。
在这里,我们可以认为J函数如下: $$J(0)=\frac{1}{2m}\sum_{i=1}^m(h_0x^{(i)}-y^{(i)})^2$$
这个错误估计函数是去对$x(i)$的估计值与真实值$y(i)$差的平方和作为错误估计函数,前面乘上的$1/2m$是为了在求导的时候,这个系数就不见了。至于为何选择平方和作为错误估计函数,就得从概率分布的角度来解释了。
如何调整$θ$以使得$J(θ)$取得最小值有很多方法,本文会重点介绍梯度下降法和正规方程法。
梯度下降
在选定线性回归模型后,只需要确定参数$θ$,就可以将模型用来预测。然而$θ$需要使得$J(θ)$最小。因此问题归结为求极小值问题。
梯度下降法流程如下:
1. 首先对$θ$赋值,这个值可以是随机的,也可以让$θ$为一个全零向量。
2. 改变$θ$的值,使得$J(θ)$按梯度下降的方向进行调整。
梯度方向由$J(θ)$对$θ$的偏导数确定,由于求的是极小值,因此梯度方向是偏导数的反方向。更新公式为为: $$0_j = 0_j - α\frac{1}{m}\sum^m_{i=1}(h_θ(x^{(i)})-y^{(i)})x_j^{i}$$
这种方法需要对全部的训练数据求得误差后再对$θ$进行更新。($α$为学习速度)
正规方程(Normal Equation)
$Xθ=y$
=>
$X^TXθ=X^Ty$
=>
$θ = (X^TX)^{-1}X^Ty$
利用以上公式可直接算出$θ$
看到这里,读者可能注意到了,正规方程法,不需要像梯度下降那样迭代多次,更关键的是从编程的角度更直接,那为什么不直接用正规,还要保留梯度下降呢?想必学过线性代数的朋友一眼能看出来,正规方程需要求$(X^TX)$的逆,这就要求$(X^TX)$是可逆的。同时,如果feature数比较多,比如共有100个feature,那么$(X^TX)$的维度会非常高,求其逆会非常耗时。