只修改一个关键参数,就会毁了整个百亿参数大模型? | 新程序员

【导读】在当今人工智能领域,AI 模型以卓越的语言理解和生成能力重塑了我们对智能交互的认知。然而,在其卓越表现的背后,隐藏着诸多尚未充分挖掘的关键因素。本文将分享大语言模型训练过程中产生的多种独特现象,推导在二阶段预训练时如何巧妙平衡数据量与背景知识的注入,从理论与实践的角度揭示其内在运作机制,深入剖析语言核心区与维度依赖理论的作用及其带来的深刻影响。
本文精选自《新程序员 007:大模型时代的开发者》,《新程序员 007》聚焦开发者成长,其间既有图灵奖得主 Joseph Sifakis、前 OpenAI 科学家 Joel Lehman 等高瞻远瞩,又有对于开发者们至关重要的成长路径、工程实践及趟坑经验等,欢迎大家点击订阅年卡。
作者 | 张奇
责编 | 王启隆
出品 | 《新程序员》编辑部

自然语言处理领域存在着一个非常有趣的现象:在多语言模型中,不同的语言之间似乎存在着一种隐含的对齐关系。复旦 NLP 团队在早期便开始做了一些相关的工作,于 2022 年发布了一篇关于 Multilingual BERT 的分析[1],随后团队持续进行对大语言模型内语言对齐机制、语言与知识结构之间内在联系的深入研究,并在 AAAI 2024 提交了一份研究报告,提出了关于大语言模型中语言对齐部分的若干猜想。基于这些研究成果,本文将分享一些大语言模型中语言和知识分离的现象。

现象 1:mBERT 模型的跨语言迁移
2022 年开始,我们发现 Multilingual BERT 是一个经过大规模跨语言训练验证的模型实例,其展示出了优异的跨语言迁移能力。具体表现为,该模型能够在某单一语言环境下训练完成一个部分后,可以非常容易地成功迁移到其他语言环境中执行任务。这一现象不禁令人思考:模型中是否存在某种特定的部分?为了探索这种多语言对齐的现象,研究采用了 Prompt 搜索方法对模型逐层分析(见图 1),针对每种语言的每一层网络及各个 head(全称 attention-head,BERT 的基本组成模块)单元进行了细致研究,旨在考察它们对语法分类任务的执行能力。

mBERT 不同层恢复各类语言语法关系的准确性
在针对多语言样本的测试中,我们选取了每种语言不同层次的部分 head 进行测试,评估它们在语法关系预测任务上的表现。实验结果显示了一个较为显著的现象:在大规模预训练过程中,即使未注入任何显式的语法先验知识,模型依然能够在语法结构层面展现出良好的对齐特性,并能在不同层次间保持一定的精度一致性。这一趋势在大多数语言中尤为突出,但在某些特殊或较少使用的语言中则不甚明显。
通过对多种不同语法现象的预测比较,研究着重对比了英语与西班牙语、英语与日语之间的差异。在第 7 层网络的语法关系可视化中,数据显示亲缘性较高的语言,其预测位置更为接近且分布趋于均匀。而像英语与日语这样差异较大的语言,部分语法成分的预测位置相对集中(见图 2),未能有效区分开来。

mBERT 第 7 层的不同语法关系表示的可视化
接下来我们发现了更为不寻常的现象:当针对特定任务对模型进行微调(Fine-tune)时,比如运用 Multilingual BERT 进行任务倾向性分析或命名实体识别等任务的微调后,模型在处理语法成分的对齐关系及区分边界的表现会得到显著提升(见图 3)。
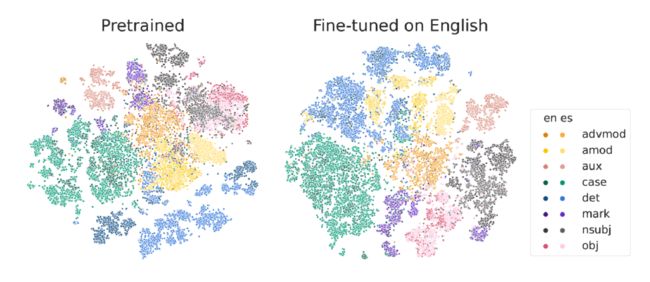
在进行任务 Fine-Tune 之后,聚合对齐更加明显
在未经微调的原始模型中,其内部蕴含了大量的语法预测信息,这些预测主要聚集在模型的中间层级,混合度比较高。但在执行相应的任务预测微调之后,这些预测分布会变得更为清晰、更具独立性。基于这一现象,可以合理推测 Multilingual BERT 模型上用单一语言微调特定任务后,其学习到的能力能够快速迁移到其他语言的原因。

现象 2:大语言模型同样存在显著的语言对齐
鉴于我们已经在上述 2022 年的研究中做了相关工作,并揭示了 Multilingual BERT 中的语言对齐现象,那么在大语言模型上面,除了 decoder-only 结构的设计改进外,剩下的就是模型的宽度和深度拓展。此现象在 Multilingual BERT 中的存在,自然引起了我们对大语言模型内部语言对齐和语法-语义对齐特性的探究。
为了更深入地解释这一问题,我们首先在 2023 年 EMNLP 发表了一篇论文[2],不仅在原始 Multilingual BERT 上进行了相应的分析工作,还在 LLaMa 模型上复现了这一现象。研究采用了一系列额外的语言评价指标,诸如 RSA 等,以期望获得更全面和准确的结论。研究结果表明,该现象在大语言模型上面与 Multilingual BERT 非常类似(见图 4)。若按照先前提出的分层逻辑,模型在语法层面展现出明显的对齐性,这与我们早期的研究结果高度一致。

语言直接在句法关系上具有很强的对齐性
其次,我们探索了将 Multilingual BERT 上的迁移工作应用到更大规模的语言模型上。具体来说,我们在词性标注任务(POS tag, Parts-of-speech tagging)上设计了一种特殊的方法(见图 5)。在面对单个语言的小规模数据集时,我们选取了若干位置,无须任何标注数据,直接使用 Multilingual BERT 的迁移方式,从而在多语言环境中获得了优秀的标注效果。举例来说,即使缺乏阿拉伯语的标注数据集,仅拥有英语和法语的数据集,也能成功地迁移到其他语言环境。
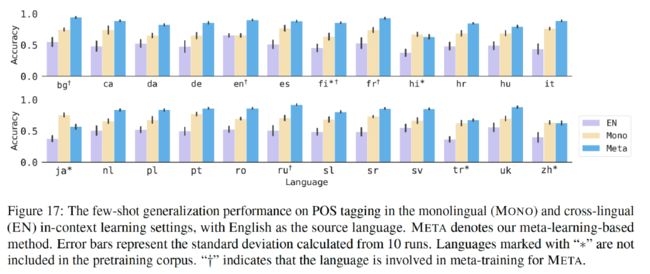
词性标注任务,可以通过跨语言训练得到非常高的结果
所以,在大语言模型当中也依然存在这种语言对齐现象。模型已成功实现了词形(单词形式,word form)与中间层语义表示、语法表示之间的转换,脱离了原有的词形,这一转换使得模型能够去处理别的任务。
通过前面的分析和工作,我们得出结论,大语言模型在多语言预训练阶段确实有效地实现了不同语言间语义层面上的对齐。我们认为,相较于可能不太重要的形式层面,语义层面的一致性可能是关键所在。一旦语义层面实现统一,理论上可以直接应对多种相关的下游任务。为了验证这一猜想,我们进一步开展了一系列研究工作。

现象 3:知识与语言分离
以下是我们投稿至 AAAI 2024 的论文[3]。假设语义层面已经实现了很好的对齐,那么词汇形式的具体表达的重要性便会相应大幅削弱。为此,我们深入探究了如何从 LLaMa 模型出发,将其语言能力迁移至其他小型语种的过程中,即便面对词形的变化,模型内部已经具备一层进行语义转换的能力。
从以英语为主的训练语言转向中文或任何其他语言时,实际上的转换需求就仅限于形式上的改变。通常,将 LLaMA 扩展为小语言需要经历三步(见图 6):第一步是词表扩展(Vocabulary Extension);第二步是继续预训练(Further Pre-training);第三步是任务添加,所以需要使用 SFT(Supervised Fine-Tuning)数据。
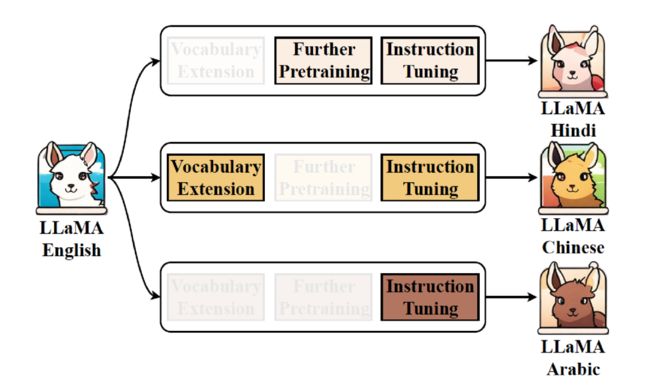
将英文 LLaMA 扩展为其他语言
为了更清晰地理解这一过程,我们将其分解为三种形式进行观察。第一种形式是完全不改动词表,直接进行继续预训练和指令微调。第二种形式只进行词表扩展,而不进行其他操作。第三种形式则完全省略前两步,直接使用大量的 SFT 数据进行训练。
基于这些设定,我们进行了对比实验。首先,直接使用 LLaMA 或 LLaMA 2 进行 SFT 训练,观察使用经过词料扩展和大规模负责培训后的效果,例如 Chinese LLaMA、Chinese LLaMA 2 和我们实验室开源的 Open Chinese LLaMA(经过 200b 数据训练)。此外,我们还测试了不进行词表扩展,直接使用 100k 和 1m 数据对中文语料进行 SFT 训练的情况。
由于评测的目的是模型生成能力,所以我们使用了能提供生成式问答题目的 LLMEVAL 评测方式,基于模型生成数据的正确性、信息量、流畅性、逻辑性等部分,分别用 GPT-4 进行打分,结果如下(见图 7)。
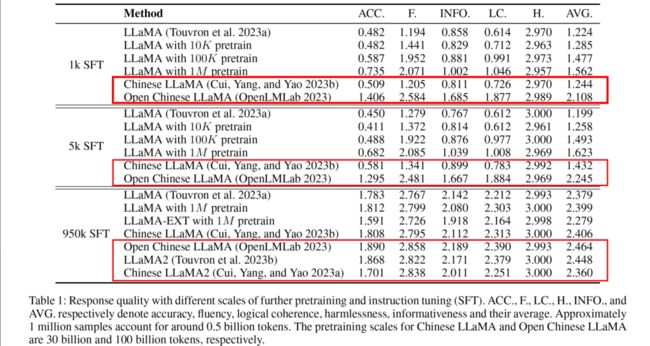
Token 扩展会导致原始信息丢失,需要大量训练才能恢复
因此,以 Chinese LLaMA 为例,恢复信息需要达到 200 倍以上的二次预训练数据,这会大幅增加训练成本。如果使用需求是让 token 的生成速度变快,我们认为依旧可以扩展词表。反之,若对生成速度没有特别大的需求,如 LLaMA 根据 UTF-8 编码生成可能需要 2 ~ 3 个 token 才能产生一个汉字,在只追求生成质量的情况下,直接进行大量中文的 SFT 数据训练,就已经可以实现非常好的处理效果。也就是说,词形和语义在语言层面已经进行了分离,提供其中文能力并不需要特别大量的数据训练。在 SFT 非常少量时,大规模的二次预训练可以加快模型对于指令的响应学习,但当 SFT 数据量扩展到 950k 之后,再去增加中文的二次预训练数据其实并没有什么特别的意义,例如在 950k SFT 的情况下,LLaMA 对比经过 1M 中文二次预训练的 LLaMA 模型,效果并没有大幅度的变化。
这也是我们之后在语言解释工作上的基础:语言的词形消失,知识和语言被分离,加入少量的中文数据无法在知识层面提升模型能力。基于这种思考,我们开始了新的评测(见图 8),其中蓝色的部分是 LLaMA-7b 模型,粉红色的部分是 LLaMA-2-7B 模型,绿色的部分是 LLaMA-13B 模型。我们希望借此看看,在经过大量的训练之后,模型的知识层面会产生哪些变化。
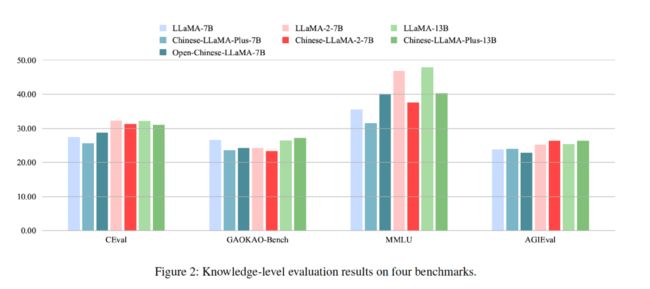
使用中文进行二次预训练并不能在知识层面提升模型能力
在经过 C-Eval、GAOKAO-Bench、MMLU 和 AGIEval 等基准评测之后,观察到大量未经针对性优化的预训练模型并未显著提升其内在的知识掌握程度,反而在某些情况下相较于原始 LLaMA 模型有所下滑。这主要是由于目前普遍采用的中文语料库训练数据规模有限,进而制约了模型在语言理解和生成方面的性能表现,导致了此类评测结果的出现。因此,如何有效地开展针对中文环境的第二阶段预训练亟需更多思考。单纯依赖现有方法,并不能充分反映出模型在特定中文领域知识的进步。值得注意的是,仅在现有的通用模型中融入少量涵盖世界知识或是物理、化学、数学等领域专业知识的中文数据,是没有太大意义的。
在其他语言中,我们也做了类似的工作(见图 9)。研究选了十几种语言,每种语言都用相应的 SFT 数据进行训练和测试,观察发现数据达到一定量级,如 65k SFT 之后,都处于相对可用的版本。但因为这些 SFT 数据有一部分是机器翻译的,不如中文直接使用的效果。

在其他低资源语言中表现类似

现象 4:语义和词形对齐
训练过程中,我们发现了一些有趣的现象,也可以从一定程度上说明这种语义和词形对齐的关系。例如,用 95k 的 SFT 对某些进行训练,并将早前的一些 checkpoint(在训练过程中不同时间点保存的模型版本)打印出来,并询问以下问题(见图 10):

图 10 训练过程中非常明显的 Coding-Switch(语码转换)现象
模型在响应查询时,输出的部分内容以红色和蓝色标示。我们观察到,模型能够在保持语义连贯正确的前提下,自动插入其他语言的词汇,而且这些词汇与前面的内容衔接自然流畅,仿佛原本就应该属于同一句话。这就从某种程度上表明,模型在内部实现了语义与词形的解耦,即模型有能力在维持语义完整性的同时,灵活处理不同语言的词形表达,引证了我们前文中的一些猜想。我们做了十几种语言,每种语言都出现了一定比例的 Coding-Switch 现象,所以这并不仅仅是中文特有的个例。

现象 5:少量的数据就能影响整个大模型
基于上述发现,我们开始深入思考。除了之前观察到的这些现象之外,其实在大语言模型的训练过程当中还有很多别的现象,比如“毛刺”(见图 11),即“噪音”(Noise)。在进行大规模预训练时,我们自身也进行了 30b 和 50b 参数级别的模型预训练,同样发现了类似情况。每当遇到这些噪音数据,我们的解决办法通常是回溯,回滚到出现问题的预训练阶段,检查那一阶段的数据。多数情况下,我们发现是由预训练数据所引起的,这部分有问题的数据会导致模型的 PPL(perplexity)值急剧升高。
“毛刺”
为何少量的数据会对如此大规模的模型造成如此严重的影响呢?OpenAI 和 Anthropic 在他们的论文[4][5]中均对此有所涉及,他们在研究 SFT 和预训练相关课题时,大多得出类似的结论:模型进行两三轮的微调通常就已经接近最优状态,过多的训练轮次往往会导致模型性能下降。这一结论在我们自身的实验中均得到了印证。
在传统训练流程中,我们可能对某部分数据训练 30 轮或 50 轮,即便数据质量不高,也只是导致这部分训练效果不佳。然而,在大语言模型上,当我们引入少量 SFT 数据并进行六轮甚至十轮微调时,整个模型的能力却可能会急剧下降,且在 SFT 数据上的表现也并未改善。这究竟是什么原因呢?这一系列疑问驱使我们去探寻深层次的答案,促使我们开始想要打开黑盒,去对它做更进一步的解释和分析。
以前,想对人脑的认知功能进行深入分析是很难的,因为直接观测和测量人脑各区域的功能是不可行,同时现代伦理准则也严格约束了对动物(如猴子)进行复杂神经科学实验的可能性。例如,我看过一则关于剥夺猴子视觉社交刺激的研究引发争议,因其可能对动物造成不可逆的影响。
在人工智能领域,BERT 模型的出现虽然为语言处理带来了重大突破,但其智能程度相对有限,且结构和动态行为相对易于分析。随着大语言模型的发展,尤其是参数量庞大的预训练模型,它们展现了更高水平的智能表现,同时也带来了新的挑战——模型的内部工作机理更加复杂且难以直观理解。那怎么办呢?我觉得不能像电视剧里刘华强说的那样,“给你机会还不中用”。既然有了机会,我们还是得把握住。


大语言模型参数中记录了知识有明显的语言核心区
经过先前的一系列分析,我们旨在探究这些现象如何具体表现在大型语言模型的参数结构中,并从参数当中研究出一些解释和情况。过去半年以来,我们不停地实验就是围绕这一目标展开。在某种程度上,这与人脑的功能分区原理相似——人脑中有专门的语言区及核心区,而在大语言模型中也可能存在着负责语言理解与知识表达的部分结构。现在有相当一部分共识,认为一部分知识存储和处理功能可能对应于模型中的前馈神经网络(Feedforward Neural Network, FFN)部分,尤其是其中的多层感知器(Multi-Layer Perceptron, MLP)组件。然而,目前我们的研究结果其实还比较初步,有些实验结论其实并不一定十分可靠。
研究中,我们认为大模型中明显存在着承载语言能力的核心区域。为什么会这么说?这一判断基于如下实验设计:首先,我们选取了六种语言,针对每种语言收集了约十万条未曾出现在 LLaMA 原始训练集中的文本数据,这些数据源自书籍并经由转换获取,出现重叠的概率较低。接下来,我们利用这些数据对 LLaMA 模型进行了二次预训练。
预训练完成后,我们对比了模型训练前后参数的变化情况,针对每种语言独立进行。首先对韩语进行预训练并记录参数变化,随后依次对俄语、越南语等其余语言进行相同操作。实验中,我们特别关注了权重变化最大的 1% 至 5% 的参数部分,因为直觉上人们通常认为权重变化较大的区域更为重要。经过四个月的研究,我们发现并非权重变化大的区域才最关键,相反,那些经过大规模预训练后变化很小的参数区域才是模型的核心稳定部分。
为验证这一点,我们进一步做了若干实验。我们发现有非常少数的参数在所有语言二次预训练中变化都很小(见图 12),无论在哪一层、哪个矩阵,都有一个显著的集中区域,其参数变化极其微小,在不同语言上的变化都非常有限。因此,我们将六种语言训练前后参数变化幅度累计起来,考察各个位置变化的综合程度,并挑选出变化最小的 1% 至 5% 的参数。
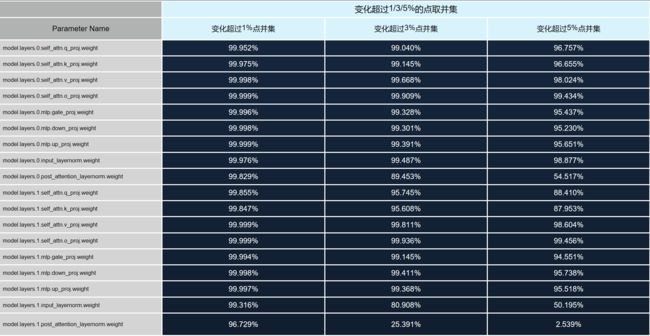
有非常少数的参数在所有语言二次预训练中变化都很小
把这部分参数拿出来之后,我们将这些变化极小的参数区域进行扰动实验。通过 7b 参数规模的模型,我们选取底层变化最小的 3% 参数进行随机化处理,然后观察模型的 PPL 指标(见图 13)。实验结果显示,当扰动这最小变化的 3% 参数时,PPL 值会显著上升;而如果我们从模型中随意选取 3% 的参数进行同样的扰动,PPL 虽会下降,但下降幅度并不明显。反之,如果我们对权重变化最大的那部分参数(同样取 3%)进行扰动,虽然 PPL 会比随机扰动稍高,但只要扰动那些变化最小的核心区域,PPL 值就会剧烈上升。同样,我们还尝试了仅扰动 1% 参数的情况,尽管变化幅度略有减小,但总体影响仍然较大,表现为几千到几万的增量。
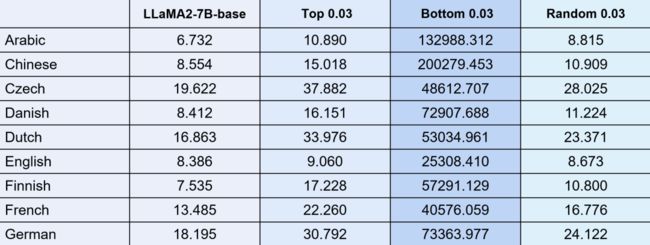
扰动核心区域在 130 种语言上 PPL 全都呈现爆炸趋势
如果用 13b 参数的模型重复上述工作,得到的结论是完全一致的(见图 14)。只要是变动这个区域 3% 的部分,整个模型语言能力基本上就会完全丧失掉了。

LLaMA2-7B 和 13B 现象完全一样
语言能力区域非常重要,所以我们通过冻结它做了另一个实验(见图 15)。实验中,我们首先锁定了模型的语言核心区参数,并用中文知乎数据对该模型进行再训练。另一组对照实验则是不解冻核心区参数。通过在中文微信公众号和英文 Falcon 数据集各选取 1 万条样本计算 PPL,我们发现:若冻结语言核心区并用 5 万条中文知乎数据进行训练,模型的中文 PPL 可以恢复至约 7 左右,表明模型通过其他区域的参数补偿了语言能力;但英文能力在这种条件下无法恢复到先前的爆炸趋势中。
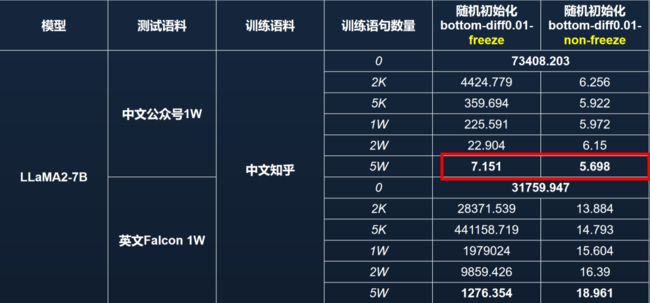
模型具备一定的“代偿”能力,可以使用中文数据训练以恢复中文能力
然而,如果仅扰乱而不冻结语言核心区参数,仅通过中文知乎数据训练,无论是中文 PPL 还是英文 PPL 都能恢复至接近原始模型的良好状态(见图 16)。因此,语言核心区的参数至关重要,且对模型能力的影响呈现出平滑而敏感的特点,只需几千条数据即可相对容易地恢复其原有功能。然而,一旦该区域被锁定,模型能力的恢复将变得困难,性能指标会出现显著变化。
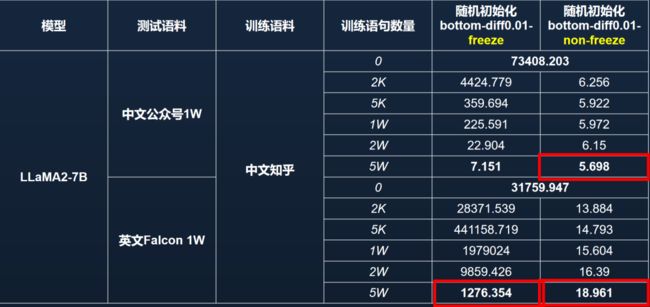
在语言区不锁定的情况下,仅训练中文,英文也能恢复一定能力
观察打印出的区域(见图 17),可以发现 QKVO 矩阵在维度上具有明显的集中现象,即主要集中在一小部分维度上。

QKVO矩阵都呈现维度集中现象
虽然 MLP 层没有那么明显的集中性,但在进一步放大查看后,发现在某些列上也存在显著的现象(见图 18)。

FFN-UP & Down某些维度上具有明显的列聚集现象
例如,在最后一层的 mlp.down 这个区域里面,少量维度尤其集中(见图 19)。
维度集中现象明显
基于此,我们进一步分析,这种维度集中性与 Layer Norm(层归一化,Layer normalization)中的单个维度扰动在计算上等效,于是我们尝试直接扰动 Layer Norm 中的单个维度。
实验结果显示,在 LLaMA 2-13B 模型中,如果仅扰动第一层的 input Layer Norm 2100 维度,将其随机化,模型的 PPL 值会由 5.877 突升至 21.42;若将该值乘以 10,PPL 值则更剧烈地增加到为 3 亿多(见图 20)。这表明尽管其他 Layer Norm 参数在理论上同样重要,但扰动它们并不会导致如此严重的性能崩溃。然而,对于这些特定维度,即便是微小的改动也会带来显著的性能变化。

扰动实验
为了直观展示这种变化,我们用扰动后的模型进行句子补全任务,输入为“Fudan University is located in”(复旦大学位于……)。在正常状态下,LLaMA2-13B 模型能够输出高质量的结果,甚至可以处理中英混合,例如直接给出复旦大学官网的链接。然而,如果将 2100 维度的 Layer Norm 随机化,模型便开始出现知识错误和语言错误,生成的文本不再正确(见图 21)。但同等程度地扰动其他维度,模型的语言输出却不会出现较大变化。

仅修改 130 亿参数中的 1 个就会使模型混乱
再回来看图 20,若将 2100 的维度乘以 10,模型的 PPL 值急剧增大,输出变得杂乱无章。可见,如果在这个特定位置(2100 维度)改动参数,整个语言模型的功能就会严重受损。当然,如果我们对其他位置的参数乘以 10,也会导致一些错误,比如模型可能会错误地将济南等地识别为复旦大学的校区。通过 PPL 指标,我们可以明显看出这些扰动对模型性能的具体影响,更何况未经扰动的 LLaMA2-13B 模型上本身也经不起多次尝试导致的错误。也就是说,130 亿参数的大模型只改一个参数,整个模型的语言能力就能完全归零。

大模型语言核心区与维度依赖理论
这些现象和理论能带来什么?其实我觉得它能在构建大模型时提供诸多有益的解释。以往我们的部分工作采用了一些技巧性的方法,尽管成效显著,但却难以阐明其内在机制。
-
首先,在进行二阶段预训练时,若目标是增强模型在特定领域(如医学或强化中文知识)的表现,而原始训练数据对该领域覆盖不足,传统的经验告诉我们,必须辅以大量相关背景知识的混合数据。例如,在开发 Open Chinese LLaMA 时,我们发现仅添加纯中文数据会导致模型性能大幅下降,而现在我们明白参数各个区域负责部分其实已经确定,如果大量增加某类在预训练时没有的知识,会造成参数的大幅度变化,造成整个语言模型能力损失。
若要对特定分区进行调整,就必须引入与之相关的背景知识,添加 5 ~ 10 倍原始预训练中的数据,并打混后一起训练,这样才能让模型逐步适应变化。否则,一旦触及核心区域,模型将丧失几乎所有能力。
-
其次,大模型语言关键区域参数极为敏感,尤其是那些对模型性能至关重要的小区域。在 SFT 阶段,若训练周期过长,针对少量数据进行多个 EPOCH 的训练,会造成语言关键区域变化,导致 PPL 飙升,甚至整个模型失效。因此,与小模型不同,不能针对少量训练数据进行过度拟合。
-
第三,模型对于噪音数据的敏感性是众所周知的,但其背后的原因值得深挖。比如,预训练数据中如果出现大量连续的噪音数据,比如连续重复单词、非单词序列等,都可能造成特定维度的调整,从而使得模型整体 PPL 大幅度波动。
另外,有监督微调指令中如果有大量与原有大语言模型不匹配的指令片段,也可能造成模型调整特定维度,从而使得模型整体性能大幅度下降。我们可通过语言核心区和维度依赖理论来解释这一现象,这意味着在未来训练和 SFT 阶段,我们需要采取相应的策略进行精细化调整。
相关资料:
[1] Xu et al. Cross-Linguistic Syntactic Difference in Multilingual BERT: How Good is It and How Does It Affect Transfer? EMNLP 2022
[2] Xu et al. Are Structural Concepts Universal in Transformer Language Models? Towards Interpretable Cross-Lingual Generalization, EMNLP 2023
[3] Zhao et al. LLaMA Beyond English: An Empirical Study on Language Capability Transfer. AAAI 2024 submitted
[4] Training language models to follow instructions with human feedback, OpenAI, 2022
[5] Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback, Anthropic, 2023