1. 起源
在使用 StarRocks 之前,短暂的先学习了解过 ClickHouse。ClickHouse 的起源和 StarRocks 有很多相似性。
1.1. ClickHouse起源
ClickHouse 全称是 Click Stream,Data WareHouse。根据名字可以分析为:在采集数据过程中,一次页面点击(click)会产生一个事件(event)。其逻辑就是,基于页面的点击事件流,面向数据仓库进行 OLAP 分析。
ClickHouse 最初是由俄罗斯搜索巨头 Yandex 的工程师开发的,用于加强其Web分析和广告技术的内部数据处理能力。Yandex 是俄罗斯最大的搜索引擎,在全球搜索引擎排名第五,仅次于 Google、Bing、Yahoo 和 Baidu。
2016年,Yandex 决定将 ClickHouse 开源,发布在 GitHub 上,这标志着 ClickHouse 对外部开发者社区的开放。2017年,ClickHouse 被 Apache 软件基金会认定为顶级项目。
ClickHouse 开源后,大家也发现了巨大的商业价值,纷纷推出商业版产品。核心研发团队分离 Yandex 成立了
ClickHouse, Inc. 公司,很多新功能只在商业版维护。类似商业版还包括 Altinity、Yandex.Cloud 等等。
国内各大厂商也基于开源版本推出自己的商业版本,提供商业化服务。例如字节就成立了一家叫 ByteHouse 的公司,推出自己的同名商业化产品。
在了解ClickHouse的起源时,就有些感慨。同样是搜索引擎公司,Google 的三驾马车推动了Hadoop大数据生态的发展,俄罗斯的 Yandex 诞生了 ClickHouse,咱国内的百度又有啥成就?
1.2. StarRocks起源(Doris)
1.2.1. Apache Doris
作为搜索引擎门户,百度最核心的业务就是广告投放。和 Yandex 研发 ClickHouse 类似,百度也是基于广告业务研发了 Doris。广告商在百度投放了广告,就需要可以通过各种统计报表、大盘看板,看到自己广告投放的效果。
产品最早的名字是Palo(OLAP倒过来),2018年贡献给 Apache 基金会时由于和其他项目重名,改名为 Apache Doris。
开源后,Doris 在社区内蓬勃发展,和 ClickHouse 一样,也有不少人发掘它的商业价值。
1.2.2. StarRocks
2020年,百度 Doris 团队少量贡献者率先出来创业,基于 Apache Doris 当时的开源版本做了自己的商业化闭源产品 DorisDB。
但这些贡献者从此再也没有在 Apache Doris 项目上贡献过一行代码,将所有的精力都投入 DorisDB。DorisDB 作为商业化独立分支,新提交的代码也没有反哺回 Apache Doris,被Apache Doris 社区斥责违背了开源精神。
而且 DorisDB 的名字就让人误会,商业宣传时又常以 Apache Doris 社区作为宣传点,也被人诟病。后来该团队所在鼎石科技公司,将 DorisDB 改名为 StarRocks。
1.2.3. SelectDB
百度 Doris 团队剩下人继续孵化 Apache Doris 项目,直至2022年,Apache Doris 也被 Apache 软件基金会认定为顶级项目。
同年,百度 Doris 团队一些人也出来开了飞轮科技公司,推出自己的商业版本 SelectDB。
SelectDB 团队吸取经验,在外以 Apache Doris 正统自居,和Apache Doris 社区保持良好关系,商业化之后依然继续贡献代码。
但是毕竟起步慢了两年,商业化市场已经被 StarRocks 占据了大半,就看未来是否能迎头赶上了。
所以 StarRocks 源自于 Apache Doris,可以对比 《Apache Doris Docs文档》 和 《StarRocks Docs文档》,可以发现二者的系统架构基本一致,仅在表引擎、查询优化等功能上有部分差异。
市场上基本没有StarRocks的书,但是关于Apache Doris的书和文档挺多,如果想深入了解StarRocks的架构设计,可以退一步看看 Apache Doris 的。
2. 架构设计
StarRocks 的分布式架构和 ElasticSearch 及其相似,无论是集群节点上,还是数据存储上。
- ES 中由“数据节点”(对应 SR 中 BE节点)来做数据存储和执行读写。
- ES 的集群和配置管理由主节点们负责,主节点选举后胜出1个“Master节点”,其他的为“候选节点”,还包括不参与选举的“只读节点”(对应 SR 中FE节点的 Master、Follower、Observer 角色节点)。
没有像 ClickHouse 一样,引用 ZooKeeper 实现集群管理。
2.1. FE节点 VS BE节点
StarRocks 架构通常包括两类节点:Frontend(FE)节点和 Backend(BE)节点。
1. Frontend(FE)节点
- 协调器(Coordinator):FE 节点接收来自客户端的所有 SQL 请求,并对其进行解析、编译和优化生成执行计划。
- 元数据管理:FE 节点存储和管理所有的元数据,包括数据库、表、列、分区以及其他对象的定义和状态信息。
- 集群管理:FE 节点管理集群的状态,确保 BE 节点之间的负载均衡和数据分布。
- 用户权限控制:FE 节点处理用户的认证和授权,管理访问控制和安全相关的操作。
- 日志记录:FE 节点记录集群操作的日志,以便于故障恢复和数据一致性保证。
- 任务调度:FE 节点负责数据导入、例行维护任务和其他管理操作的调度。
2. Backend(BE)节点
- 数据存储:BE 节点负责实际的数据存储,以列式存储格式存放数据以支持高效查询。
- 查询执行:BE 节点根据 FE 节点生成的执行计划,执行查询操作并返回结果。
- 数据处理:BE 节点执行数据更新、删除和插入等数据操纵语言(DML)操作,处理数据压缩、索引维护等任务。
- 数据副本管理:BE 节点负责数据的副本管理,实现数据的高可用性和容错。
FE 节点更像是数据库的大脑,负责理解 SQL 请求、计划查询以及管理集群的配置和状态。BE 节点则像是执行器,负责存储数据和在物理硬件上执行查询计划。
2.2. 三种FE节点角色
在 StarRocks 的架构中,FE(Frontend)节点可以有三种不同的角色,每个角色都有其特定的职责。这三种角色分别是:
1. Master
Master FE 节点是集群的主节点,它负责处理所有的写操作,包括更新元数据(如数据库、表、分区等的变更)、处理 DDL(数据定义语言)操作,以及处理客户端的查询请求。Master FE 节点还负责协调和管理其他 FE 节点,包括同步元数据的变更给 Follower 和 Observer FE 节点。在集群中通常只有一个 Master FE 节点。
2. Follower
Follower FE 节点是主节点的热备份。它们通过复制 Master FE 节点的日志来同步元数据变化。在 Master FE 发生故障时,其中一个 Follower FE 节点可以被提升为新的 Master FE,从而确保集群的高可用性。Follower FE 节点可以处理读操作,但所有的写操作都需要通过 Master FE 节点来协调。
3. Observer
Observer FE 节点提供了一个只读视图的集群状态,它们同样通过复制 Master FE 的日志来保持元数据的同步。Observer FE 节点主要用于提供冗余和读取扩展,以及在一些架构中,可能用于负载均衡或实现读写分离。Observer 节点在故障转移中不会被提升为 Master FE 节点。
这种设计允许 StarRocks 集群实现高可用性,通过 Follower 和 Observer 节点可以在 Master 节点宕机时快速进行故障切换,而不会丢失关键的元数据信息,并且还可以在高负载情况下扩展读操作。
此外,Observer FE 节点可以用作备份,以便在集群升级或维护时保证服务的持续可用性。
2.3. FE、CN
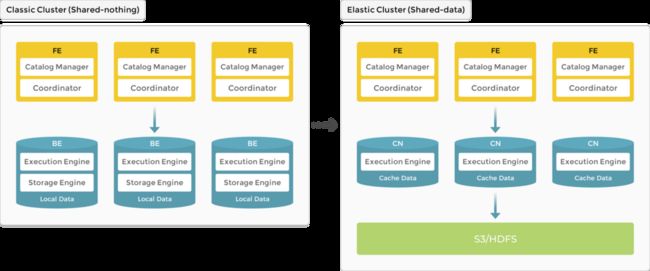
业务中随着用户存储数据量的增加,往往需要不断扩容存储资源,从而增加 BE 节点,但导致 BE 节点上计算资源的浪费。
3.0 版本开始引入 存算分离 架构,数据存储功能从原来的 BE 中抽离,BE 节点升级为无状态的 CN (Compute Node) 节点。
数据可持久存储在远端对象存储或 HDFS 上,CN 本地磁盘只用于缓存热数据来加速查询。
3. 分区、分桶、副本
FE、BE是从集群架构上体现分布式,从表数据存储上,也同样有分布式的体现。
1. 分区(Partitioning)
表数据首先被逻辑上划分为多个分区,通常基于一个或多个列的值,这些列称为分区键。
每个分区可以包含一段连续的数据范围,比如日期列,可以按月或年来分区。
分区使得数据管理更为高效,特别是针对大数据量的表,因为它可以缩小查询作用域,提高数据访问速度。
2. 分桶(Bucketing)
在每个分区内部,数据进一步被划分为多个桶(Bucket),这通常是基于数据的某个列的哈希值。
分桶策略有助于在 BE 节点间均衡数据分布,保证负载均衡和高效地并行处理查询。
3. 数据副本(Replication)
为了提高数据的可靠性和可用性,StarRocks 会在不同的 BE 节点上创建数据的副本。
数据副本可以保证在某个 BE 节点失败时,系统仍然能够访问到数据,从而实现故障恢复。
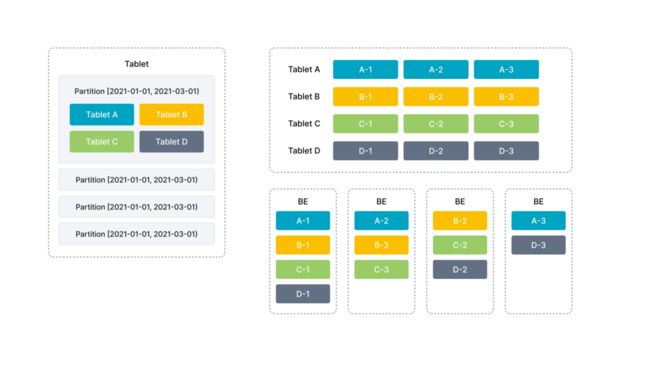
如图中:
- 表按照日期划分为 4 个分区,第一个分区进一步切分成 4 个桶(Tablet)。
- 每个桶使用 3 副本进行备份,分布在 3 个不同的 BE 节点上