深入解析 Flink 细粒度资源管理
▼ 关注「Apache Flink」,获取更多技术干货 ▼
摘要:本文整理自阿里巴巴高级开发工程师郭旸泽 (天凌) 在 Flink Forward Asia 2021 核心技术专场的演讲。主要内容包括:
细粒度资源管理与适用场景
Flink 资源调度框架
基于 SlotSharinGroup 的资源配置接口
动态资源切割机制
资源申请策略
总结与未来展望
Tips:点击「阅读原文」查看原文视频 & 演讲PDF~
一、细粒度资源管理与适用场景

在 Flink1.14 之前,使用的是一种粗粒度的资源管理方式,每个算子 slot request 所需要的资源都是未知的,在 Flink 内部用一个 UNKNOWN 的特殊值来表示,这个值可以和任意资源规格的物理 slot 来匹配。从 TaskManager (以下简称 TM) 的角度来说,它拥有的 slot 个数和每个 slot 的资源维度都是根据 Flink 配置静态决定的。

对于多数简单作业,现有的粗粒度资源管理已经可以基本满足对资源效率的要求。比如上图作业,由 Kafka 读入数据后经过一些简单的处理,最终将数据写入到 Redis 中。对于这种作业,我们很容易将上下游并发保持一致,并将作业的整个 pipeline 放到一个 SlotSharingGroup (以下简称 SSG) 中。这种情况下,slot 的资源需求是基本相同的,用户直接调整默认的slot配置即可达到很高的资源利用效率,同时由于不同的 task 热点峰值不一定相同,通过削峰填谷效应,将不同的 task 放到一个大的 slot 里,还可以进一步降低整体的资源开销。
然而对于一些生产中可能遇到的复杂作业,粗粒度资源管理并不能很好地满足他们的需求。
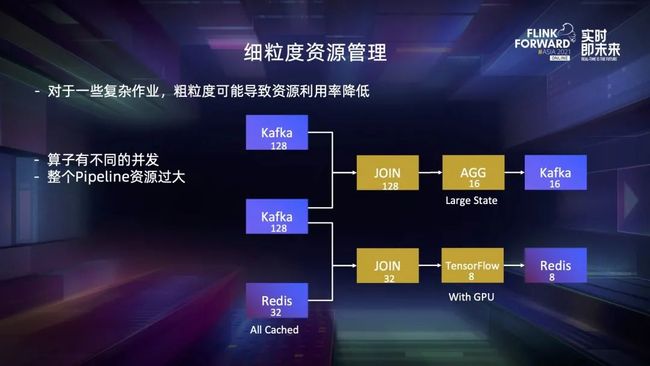
比如图上作业,有两个 128 并发的 Kafka source 和一个 32 并发的 Redis 维表,上下两路数据处理路径。一条是两个 Kafka source,经过 join 以后再经过一些聚合操作,最终将数据 sink 到第三个 16 并发的 Kafka 中;另一条路径则是 Kafka 和 Redis 维表进行 join,结果流入一个基于 TensorFlow 的在线推断模块,最终储存到 Reids 中。
在这个作业中粗粒度资源管理就可能导致资源利用效率降低。
首先作业上下游并发不一致,如果想把整个作业放到一个 slot 中,只能和最高的 128 并发对齐,对齐的过程对于轻量级的算子没有太大问题,但是对于比较重的资源消耗的算子,会导致很大的资源浪费。比如图上的 Redis 维表,它将所有数据都缓存到内存中来提高性能,而聚合算子则需要比较大的 managed memory 来存储 state。对于这两个算子,本来只需要分别申请 32 和 16 份资源,对齐并发以后则分别需要申请 128 份。
同时,整个作业的 pipeline 可能由于资源过大而无法放到一个 slot 或是 TM 中,比如上述算子的内存,再比如 Tensorflow 模块需要 GPU 来保证计算效率。由于 GPU 是一种非常昂贵的资源,集群上不一定有足够的数量,从而导致作业因为对齐并发而无法申请到足够的资源,最终无法执行。
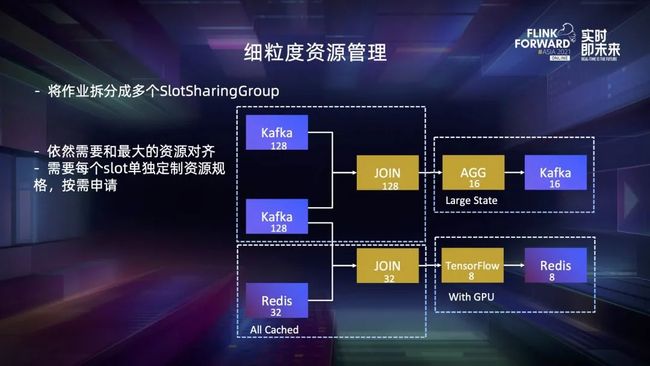
我们可以将整个作业拆分成多个 SSG。如图所示,我们将算子按照并发划分成 4 个 SSG,保证每个 SSG 内部的并发是对齐的。但是由于每个 slot 只有一种默认规格,依然需要将该 slot 的所有资源维度都对齐到各个 SSG 的最大值,比如内存需要和 Redis 维表的需求对齐,managed memory 需要和聚合算子对齐,甚至扩展资源中都需要加入一块 GPU,这依然不能解决资源浪费的问题。
为了解决这个问题,我们提出了细粒度资源管理,其基本思想是,每个 slot 的资源规格都可以单独定制,用户按需申请,最大化资源的利用效率。

综上,细粒度资源管理就是通过使作业各个模块按需申请和使用资源来提高资源的整体利用效率。它的适用场景包括以下几种:作业中上下游 task 并发有显著差异、pipeline 的资源过大或者其中包含比较昂贵的扩展资源。这几种情况都需要将作业拆分成多个 SSG,而不同的 SSG 资源需求存在差异,这时通过细粒度资源管理就能减少资源浪费。此外,对于批任务,作业可能包含一个或多个 stage,不同 stage 之间资源消耗存在显著差异,同样需要细粒度资源管理来减少资源开销。
二、Flink 资源调度框架
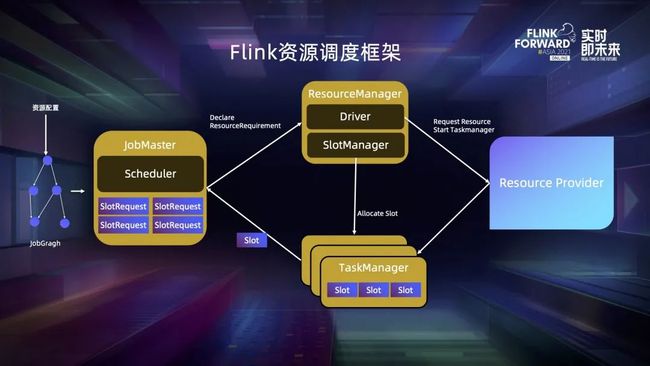
Flink 的资源调度框架中主要有三个角色,分别是 JobMaster (以下简称 JM),ResourceManager (以下简称 RM) 和 TaskManager。用户写好的任务首先会被编译成 JobGraph,注入资源后提交到 JM,JM 的作用就是管理 JobGraph 的资源申请以及执行部署。
JM 中的调度相关的组件是 Scheduler,它会根据 JobGraph 生成一系列 SlotRequest,然后将这些 SlotRequest 进行聚合,生成一个 ResourceRequirement 发送给 RM,RM 接到资源声明以后,首先会检查集群中现有的资源能否满足其需求,可以的话就会向 TM 发出请求,让他给对应的 JM 去 offer slot (这里 slot 的分配由 SlotManager 组件来完成)。如果现有资源不够,它会通过内部的 driver 向外部的 K8s 或者 Yarn 申请新的资源,最终 JM 接收足够多的 slot 之后就会开始部署算子,作业才能运行起来。
顺着这个框架,接下来对细粒度资源管理中的技术实现细节和 design choice 进行分析阐述。
三、基于 SlotSharingGroup 的
资源配置接口

在入口处 Flink 需要将资源配置注入 JobGraph 中。这部分是 FLIP-156 中提出的基于 SlotSharingGroup 的资源配置接口,关于资源配置接口的设计选择,主要问题是资源配置的粒度:
首先是最小的算子粒度 operator。如果用户在 operator 上配置资源的话,Filnk 需要根据 chaining 和 slot sharing 进一步将资源聚合成 slot 级别再进行资源调度。
使用这个粒度的好处是,我们可以将资源配置与 chaining 和 slot sharing 的逻辑解耦,用户只需要考虑当前算子的需求,而无须考虑它是否和其他算子嵌在一起或者是否调度到一个 slot 中。其次,它使 Flink 可以更准确地计算每个slot的资源。假如某一个 SSG 中上下游算子拥有不同的并发,那么可能 SSG 对应的物理 slot 需要的资源也是有差异的;而如果 Flink 掌握了每个算子的资源,它就有机会进一步优化资源效率。
当然它也存在一些缺点,首先是用户配置成本过高,生产中的复杂作业包含了大量算子,用户很难一一配置。其次,这种情况下,很难支持粗细粒度混合资源配置。一个 SSG 中如果既存在粗粒度,又存在细粒度的算子,会导致 Flink 无法判断其所需要的资源到底是多少。最后,由于用户对资源的配置或估计会存在一定程度的偏差,这种偏差会不断累积,算子的削峰填谷效应也无法被有效利用。

第二种选择是将算子 chaining 后形成的 task 作为资源配置的粒度。这种情况下,我们必须向用户暴露 Flink 内部的 chaining 逻辑,同时 Flink 的 runtime 依然需要根据 task 的 slot sharing 的配置进一步将资源聚合成 slot 级别再进行资源调度。
它的优缺点和算子粒度大致一样,只不过相比算子,它在用户的配置成本上有了一定程度的降低,但这依然是一个痛点。同时它的代价是无法将资源配置和 chaining 解耦,将 chaining 和 Flink 内部的逻辑暴露给用户,导致内部潜在的优化受到限制。因为一旦用户配置了某个 task 的资源,chaining 逻辑的改变可能让 task 分裂成两个或者三个,造成用户配置不兼容。

第三种选择是直接将 SlotSharingGroup 作为资源配置的粒度,这样对 Flink 来说资源配置所见既所得,省略了前面的资源聚合逻辑。
同时这种选择还有以下几个优点:
第一,使用户的配置更灵活。我们将配置粒度的选择权交给用户,既可以配置算子的资源,也可以配置 task 资源,甚至配置子图的资源,只需要将子图放到一个 SSG 里然后配置它的资源即可。
第二,可以较为简单地支持粗细粒度混合配置。所有配置的粒度都是 slot,不用担心同一个 slot 中既包含粗粒度又包含细粒度的 task。对于粗粒度的 slot,可以简单地按照 TM 默认的规格计算它的资源大小,这个特性也使得细粒度资源管理的分配逻辑可以兼容粗粒度调度的,我们可以把粗粒度看作是细粒度的一种特例。
第三,它使得用户可以利用不同算子之间的削峰填谷效应,有效减少偏差产生的影响。
当然,也会引入一些限制,它将资源配置的 chaining 以及 Slot Sharing 耦合在了一起。此外如果一个 SSG 里算子存在并发差异,那么为了最大化资源利用效率,可能需要用户手动拆组。

综合考虑,我们在 FLIP-156 中,最终选择了基于 SlotSharingGroup 的资源配置接口。除了上述提到的优点,最重要的是从资源调度框架中可以发现,slot 实际上就是资源调度中最基本的单位,从 Scheduler 到 RM\TM 都是以 slot 为单位进行资源调度申请的,直接使用这个粒度,避免了增加系统的复杂度。
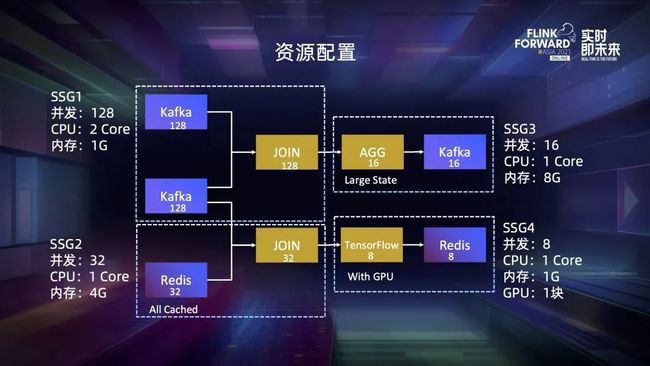
回到示例作业,在支持了细粒度资源管理配置接口后,我们就可以为 4 个 SSG 配置不同的资源,如上图所示。只要调度框架严格按照这个原则进行匹配,我们就可以最大化资源利用效率。
四、动态资源切割机制
解决了资源配置以后,下一步就是为这些资源申请 slot,这一步需要用到 FLIP-56 提出的动态资源切割机制。

简单回顾一下这幅图,现在最左侧的 JobGraph 已经有资源了,往右走就进入了 JM、RM 和 TM 的资源调度。在粗粒度资源管理下,TM 的 slot 都是固定大小、根据启动配置来决定的,RM 在这种情况没法满足不同规格的 slot 请求的,因此我们需要对 slot 的创建方式进行一定的改造。
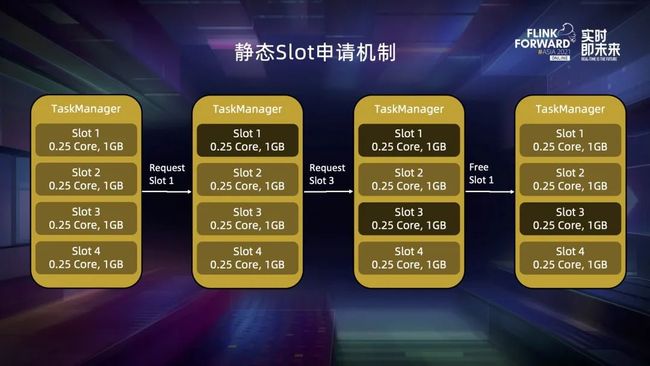
先来看现有的静态 slot 申请机制。实际上 TM 启动的时候 slot 就已经划分好了,并且标记了编号。它会将这些 slot 上报给 Slot Manager,slot request 来临时 Slot Manager 会决定申请 slot1、slot3,最后 slot1 上的 task 运行完以后会释放 slot。这种情况下,只有 slot3 处于占用的状态。我们可以发现,这时虽然 TM 有 0.75 core,3G 的空闲资源,但如果 job 去申请对应资源大小的 slot,TM 也无法满足它,因为 slot 已经提前划分好了。

因此我们提出了动态资源切割机制。slot 不再是 TM 启动后就生成并且不变的,而是根据实际 slot 的请求动态地从 TM 上切割下来。TM 启动时,我们把能分配给 slot 的资源看作是一整个资源池,比如上图有 1core,4G 内存的资源,现在有一个细粒度的作业,Slot Manager 决定从 TM 上要一个 0.25core,1G 的 slot,TM 会检查自己的资源池是否能够切下这个 slot,然后动态生成 slot 并分配对应的资源给 JM,接下来这个作业又申请一个 0.5core,2G 的 slot,Slot Manager 还是可以从同一个 TM 上申请 slot,只要不超过空闲资源就可以。当某个 slot 不再需要时,我们可以将它销毁,对应的资源会回到空闲资源池。
通过这种机制,我们解决了细粒度资源请求如何满足的问题。
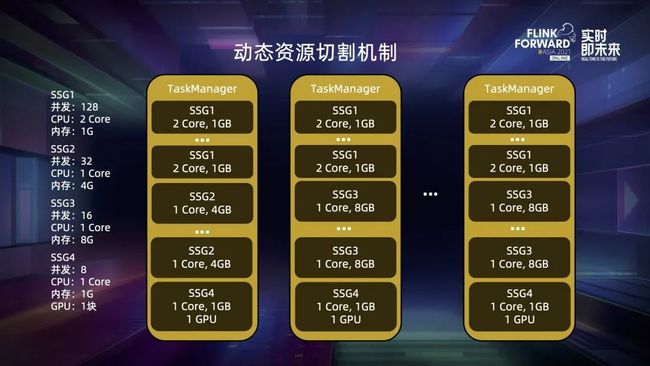
回到示例作业,我们只需要起 8 个同样规格的 TM 就能调度作业,每个 TM 上带一块 GPU 来满足 SSG4,之后将 CPU 密集型的 SSG1 和内存密集型的 SSG2 和 SSG3 进行混布,对齐 TM 上整体的 CPU 内存比即可。
五、资源申请策略
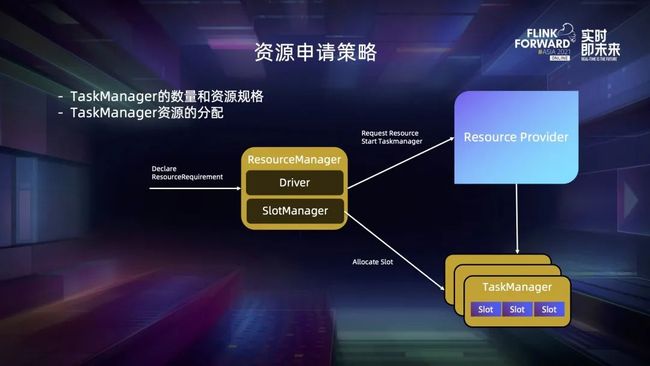
何谓资源申请策略?它包含 RM 与 Resource Provider 还有 TM 交互时的两个决策,一个是从 Resource Provider 处申请什么资源规格的 TM 以及各个规格 TM 各需要几个,另一个是如何将 slot 摆放到各个 TM 中。实际上这两个决策都是在 Slot Manager 组件内部进行的。

粗粒度的资源申请策略比较简单,因为只存在一种规格的 TM,并且 slot 规格都是一样的。在分配策略上只需要考虑是否将 slot 尽量平铺到各个 TM。但在细粒度资源管理下的策略就需要考虑到不同的需求。
首先我们引入了动态资源切割机制。slot 的调度就可以看作一个多维装箱问题,既需要考虑如何减少资源碎片,也需要保障资源调度效率。此外还有 slot 是否需要评估,以及集群可能对 TM 的资源规格有一些要求,比如不能过小,在 K8s 上如果 TM 资源过小,会导致启动过慢,最后注册超时,但也不能太大,会影响 K8s 的调度效率。
面对上述复杂性,我们将这个资源申请策略抽象出来,定义了一个 ResourceAllocationStrategy,Slot Manager 会将当前的资源请求和集群中现有的可用资源告诉 strategy,strategy 负责决策并告诉 Slot Manager 现有资源如何分配、还需要申请多少个新的 TM 以及它们分别的规格,还有是否存在无法满足的作业。

目前细粒度资源管理还处于 beta 版本,社区内置了一个简单的默认资源管理策略。在这个策略下 TM 的规格是固定的、根据粗粒度的配置决定的,如果某个 slot 的请求大于资源配置,可能导致无法分配,这是它的局限性。在资源分配方面,它会顺序扫描当前空闲的 TM,只要满足 slot 的请求就会直接切割,这种策略保障了资源调度即使在大规模的任务上也不会成为瓶颈,但代价是无法避免资源碎片的产生。
六、总结与未来展望

细粒度资源管理目前在 Flink 中还只是 beta 版本。上图可以看到,对于 runtime 来说,通过 FLIP-56 与 FLIP-156,细粒度资源管理的工作已经基本完成了。而从用户接口的角度,FLIP-169 已经开放了 Datastream API 上的细粒度配置,具体如何配置,可以参考社区的用户文档。

未来,我们的发展方向主要是以下几个方面:
第一,定制更多的资源管理策略来满足不同场景,比如 session 和 OLAP 等;
第二,目前我们是把扩展资源看作一个 TM 级别的资源,TM 上的每个 slot 都可以看到它的信息,之后我们会对它的 scope 进行进一步限制;
第三,目前细粒度资源管理可以支持粗细粒度混合配置,但是存在一些资源效率上的问题,比如粗粒度的 slot 请求可以被任意大小的 slot 满足,未来我们会进一步优化匹配逻辑,更好地支持混合配置;
第四,我们会考虑适配社区新提出的 Reactive Mode;
最后,对 WebUI 进行优化,能够展示 slot 的切分信息等。
往期精选




更多 Flink 相关技术问题,可扫码加入社区钉钉交流群~

 戳我,查看原文视频&演讲PDF~
戳我,查看原文视频&演讲PDF~