PagedAttention: from interface to kernal
1 Overview
PagedAttention灵感来自于操作系统中虚拟内存和分页的经典思想,它可以允许在非连续空间立存储连续的KV张量。具体来说,PagedAttention把每个序列的KV缓存进行了分块,每个块包含固定长度的token,而在计算attention时可以高效地找到并获取那些块。
2 Block management
相比于RaggedAttention,PagedAttention其实就是维护了一个逻辑block到物理block的映射。接下来,我们结合代码,看一下是vLLM如何实现PagedAttention中Block管理的。
2.1 LogicalTokenBlock and PhysicalTokenBlock
先看一下LogicalTokenBlock 和 PhysicalTokenBlock的数据结构,比较简单,看代码注释就好了。
class LogicalTokenBlock:
"""
Logical blocks are used to represent the states of the corresponding physical blocks in the KV cache.
"""
def __init__(
self,
block_number: int,
block_size: int,
) -> None:
self.block_number = block_number // LogicalTokenBlock id, 由零递增
self.block_size = block_size // 最多容纳token数量(block大小),默认为 16
self.token_ids = [_BLANK_TOKEN_ID] * block_size // 初始化为TOKEN_ID为-1,表示无效token
self.num_tokens = 0 // 此block中存储的有效token的数量
def append_tokens(self, token_ids: List[int]) -> None:
"""核心api, LogicalTokenBlock中的token只能从左到右append"""
assert len(token_ids) <= self.get_num_empty_slots()
curr_idx = self.num_tokens
self.token_ids[curr_idx:curr_idx + len(token_ids)] = token_ids
self.num_tokens += len(token_ids)
class PhysicalTokenBlock:
"""Represents the state of a block in the KV cache."""
def __init__(
self,
device: Device,
block_number: int,
block_size: int,
) -> None:
self.device = device // 记录PhysicalTokenBlock物理存储位置,GPU or CPU
self.block_number = block_number // PhysicalTokenBlock id, 由零递增
self.block_size = block_size // block大小,与LogicalTokenBlock中block_size相等,默认为 16
self.ref_count = 0 // 引用计数,beam search 里面同一个block可能会被多个sequence引用
2.2 BlockAllocator
BlockAllocator是用来管理空闲block的数据结构。其中最核心的数据结构是一个链表free_blocks,存储空闲的PhysicalTokenBlock。
# Mapping: logical block number -> physical block.
BlockTable = List[PhysicalTokenBlock]
class BlockAllocator:
"""Manages free physical token blocks for a device.
The allocator maintains a list of free blocks and allocates a block when
requested. When a block is freed, its reference count is decremented. If
the reference count becomes zero, the block is added back to the free list.
"""
def __init__(
self,
device: Device,
block_size: int,
num_blocks: int,
) -> None:
self.device = device // 维护的blocks存储位置,GPU or CPU
self.block_size = block_size // block大小,默认为 16
self.num_blocks = num_blocks //
# Initialize the free blocks.
self.free_blocks: BlockTable = [] // 一个链表,存储空闲的PhysicalTokenBlock
for i in range(num_blocks):
block = PhysicalTokenBlock(device=device,
block_number=i,
block_size=block_size)
self.free_blocks.append(block)
2.3 BlockSpaceManager
BlockSpaceManager是维护BlockSpace的核心数据结构,维护着LogicalTokenBlock到PhysicalTokenBlock的映射。在vLLM初始化的时候,首先会获取系统可用的CPU端和GPU端存储容量,从而计算出可用的block数量。
- gpu_allocator
- 将系统可用的GPU端存储按照block进行管理。
- 其中维护一个链表free_blocks,存储空闲的PhysicalTokenBlock。
- cpu_allocator
- 将系统可用的CPU端存储按照block进行管理。
- 当GPU显存不够用时,会将存储在GPU显存的block换出至CPU。
- watermark_blocks
- 其实就是设置一个阈值,当gpu_allocator内空闲block数量小于watermark_blocks,停止分配新的sequence。
- 以避免频繁的缓存逐出。
- block_tables
- 存储sequence的BlockTable
- BlockTable 维护者 logical block number -> physical block 的映射
- 假设一个sequence使用了N个logical block,那么,logical block number 为0~N-1
class BlockSpaceManager:
"""Manages the mapping between logical and physical token blocks."""
def __init__(
self,
block_size: int,
num_gpu_blocks: int,
num_cpu_blocks: int,
watermark: float = 0.01
) -> None:
self.block_size = block_size
self.num_total_gpu_blocks = num_gpu_blocks
self.num_total_cpu_blocks = num_cpu_blocks
self.watermark = watermark
assert watermark >= 0.0
self.watermark_blocks = int(watermark * num_gpu_blocks)
self.gpu_allocator = BlockAllocator(Device.GPU, block_size,
num_gpu_blocks)
self.cpu_allocator = BlockAllocator(Device.CPU, block_size,
num_cpu_blocks)
# Mapping: seq_id -> BlockTable.
self.block_tables: Dict[int, BlockTable] = {}
2.4 Sequence
一个Sequence对应一个推理上下文。
- logical_token_blocks
- 一个链表,维护着Sequence使用的LogicalTokenBlock
- 链表中LogicalTokenBlock的logical block number 依次为0~N-1
- 根据logical block number就可以在BlockSpaceManager中的block_tables获取physical block
class Sequence:
"""Stores the data, status, and block information of a sequence.
Args:
seq_id: The ID of the sequence.
prompt: The prompt of the sequence.
prompt_token_ids: The token IDs of the prompt.
block_size: The block size of the sequence. Should be the same as the
block size used by the block manager and cache engine.
"""
def __init__(
self,
seq_id: int,
prompt: str,
prompt_token_ids: List[int],
block_size: int,
) -> None:
self.seq_id = seq_id
self.prompt = prompt
self.block_size = block_size
self.logical_token_blocks: List[LogicalTokenBlock] = []
# Initialize the logical token blocks with the prompt token ids.
self._append_tokens_to_blocks(prompt_token_ids)
3 PagedAttention kernal
Transformer推理过程中最重要的算子是attention算子。当拿到物理block,就可以获取到当前context中token对应的kv vector,然后进行attention操作。
这是一张Multi-head attention(NUM_HEAD = 2)的示意图,q向量与kv向量进行attention操作,产生下一个token。

3.1 attention 伪代码
attention 的C语言串行代码非常简单,容易理解。
-
q 向量与 MAX_SEQ个 k向量分别进行向量内积计算。
计算出来MAX_SEQ个logit,代表了 q 向量和 k 向量之间的相关性。
-
对MAX_SEQ个logit进行softmax
-
q 向量和 k 向量之间的相关性作用于v向量,获取最终的ans向量。
typedef struct _query
{
vector vectors[NUM_HEAD];
} query;
typedef query answer;
typedef struct _kv_cache
{
uint32_t num_token;
vector k_cache[NUM_HEAD][MAX_SEQ_LEN];
vector v_cache[NUM_HEAD][MAX_SEQ_LEN];
} kv_cache;
void multi_head_attention(query *q, kv_cache *kv, answer *ans)
{
int32_t logits[MAX_SEQ_LEN];
vector *head_ans;
answer_init(ans);
// NUM_HEAD个attention操作相互独立
for (int i = 0; i < NUM_HEAD; i++)
{
// q 向量与 MAX_SEQ个 k向量分别进行向量内积计算。logits[j]代表了q->vectors[i]和kv->k_cache[i][j]之间的相关性
for (int j = 0; j < MAX_SEQ_LEN; j++)
{
logits[j] = vector_dot(&(q->vectors[i]), &(kv->k_cache[i][j]));
}
// 对MAX_SEQ个logit进行softmax
soft_max(logits);
head_ans = &(ans->vectors[i]);
// logits[j]作用于kv->v_cache[i][j],获取最终的ans向量。
// head_ans+=logits[j]×kv->v_cache[i][j]
for (int j = 0; j < MAX_SEQ_LEN; j++)
{
vector_add(head_ans, &(kv->v_cache[i][j]), logits[j]);
}
}
}
3.2 paged_attention_v1_kernel
将上述的 C 串行代码改成cuda并行代码,并且充分发挥出GPU硬件算力,这并不是一件容易的事情。PagedAttention提供了两个version的kernal代码,我们先来看paged_attention_v1_kernel。
3.2.1 Input
const scalar_t* __restrict__ q, // [num_seqs, num_heads, head_size]
const scalar_t* __restrict__ k_cache, // [num_blocks, num_kv_heads, head_size/x, block_size, x]
const scalar_t* __restrict__ v_cache, // [num_blocks, num_kv_heads, head_size, block_size]
- 任何一个q k v向量的长度都是head_size。
- q 存储没什么好说的,其实就是num_seqs×num_heads个向量存储在连续的内存空间。
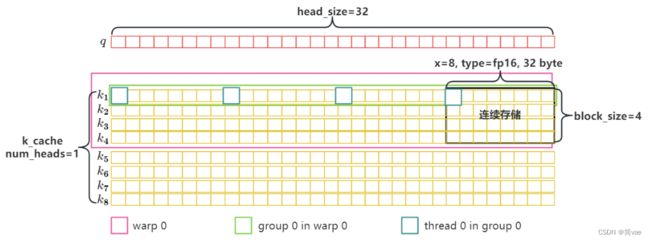
- k_cache中的 k 向量并没有存储在连续内存空间。其中,最后1维是x ,占用16字节(如果参数为FP16,则x=16/2;如果参数为FP32,则x=16/4)。
- block_size默认为16,也就是说,一个token block中16个token对应的16个 k 向量segment(16字节)存储在一块。
- 这儿太绕了,还是看图吧。
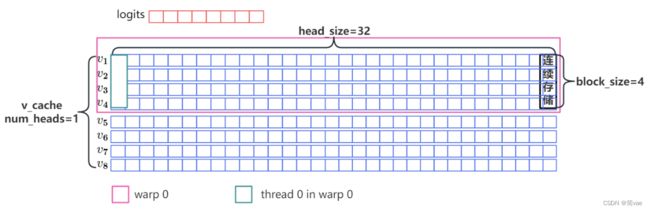
- k_cache中的 v 向量也没有存储在连续内存空间。
- block_size默认为16,也就是说,一个token block中16个token对应的16个 k 向量以interleave的方式存储在一块。
- 还是看图吧。一图胜千言。
为了突出重点,图中num_head=1, block_size=4,只有两个token block:

3.2.2 workload partition
attention算子对并行计算很友好。我们来看一下paged_attention_v1_kernel中的并行计算任务划分,其实就是搞清楚cuda block、warp和thread各自承担了那些计算任务。
3.2.2.1 cuda grid
dim3 grid(num_heads, num_seqs, 1);
不同sequence中的attention任务互不干扰,同一sequence中不同head中的attention任务也互不干扰。
因此,paged_attention_v1_kernel将一个head中的attention任务交给一个cuda block完成。这样的话,不涉及不同cuda block间的同步,通信开销会比较小。
3.2.2.2 cuda block
1个cuda block 负责1个 head 中的attention任务。在PagedAttention中1个cuda block 中的任务划分比较复杂,不仅包含warp和thread,还包含group。整个过程可以分成两个主要阶段:1. 计算logits参数;2. 将logits参数作用于v_cache,得出结果。
cuda block中创建了128个cuda thread,也就是4个warp,1个warp中包含32个cuda thread。
-
阶段1,计算logits参数
-
单独拿出C串行伪代码:
// head_ans+=logits[j]×kv->v_cache[i][j] for (int j = 0; j < MAX_SEQ_LEN; j++) { logits[j] = vector_dot(&(q->vectors[i]), &(kv->k_cache[i][j])); } -
在paged_attention_v1_kernel中的任务划分:
-
warp
一个或多个token block分配给一个warp执行。
warp 会对 token block 按 x × block_size 字节的连续存储块依次进行处理。
-
thread group
一个warp会划分成block_size个thread group,也就是说一个thread group负责处理一个token。
thread group 会对 token 按 x 字节的连续存储块依次进行处理。
-
thread
将token 中 x 字节的连续存储块划分成 VEC_SIZE = x / sizeof(type) / THREAD_GROUP_SIZE 的 VEC 进行处理。
每一个 thread 负责 head_size / VEC_SIZE 个 VEC。
-
-
任务划分示意图
-
-
阶段2,将logits参数作用于v_cache,得出结果
-
单独拿出C串行伪代码:
for (int j = 0; j < MAX_SEQ_LEN; j++) { vector_add(head_ans, &(kv->v_cache[i][j]), logits[j]); } -
在paged_attention_v1_kernel中的任务划分:
-
warp
一个或多个token block分配给一个warp执行。
warp 会对 token block 按 sizeof(type) × block_size 字节的连续存储块依次进行处理。
-
thread
如果sizeof(type) × block_size 字节的连续存储块大于16字节,则将其切分为16字节的连续存储块。然后,将16字节的连续存储块依次分配给warp内线程进行处理。
如果sizeof(type) × block_size 字节的连续存储块小于等于16字节,则将其依次分配给warp内线程进行处理。
-
-
任务划分示意图
-
3.2.3 伪代码
简单写一下paged_attention_v1_kernel的伪代码:
__device__ void paged_attention_kernel(
scalar_t* __restrict__ out, // [num_seqs, num_heads, max_num_partitions, head_size]
const scalar_t* __restrict__ q, // [num_seqs, num_heads, head_size]
const scalar_t* __restrict__ k_cache, // [num_blocks, num_kv_heads, head_size/x, block_size, x]
const scalar_t* __restrict__ v_cache, // [num_blocks, num_kv_heads, head_size, block_size]
const int num_kv_heads, // [num_heads]
){
__shared__ Q_vec q_vecs[THREAD_GROUP_SIZE][NUM_VECS_PER_THREAD];
/*
* load q_vecs
*/
__syncthreads();
// Memory planning.
float* logits = reinterpret_cast(shared_mem);
for (int block_idx = start_block_idx + warp_idx; block_idx < end_block_idx; block_idx += NUM_WARPS) {
K_vec k_vecs[NUM_VECS_PER_THREAD];
for (int i = 0; i < NUM_TOKENS_PER_THREAD_GROUP; i++) {
for (int j = 0; j < NUM_VECS_PER_THREAD; j++){
/*
* load k_vecs
*/
}
}
/*
* compute q k dot
*/
float qk = scale * Qk_dot::dot(q_vecs[thread_group_offset], k_vecs);
logits[token_idx - start_token_idx] = mask ? 0.f : qk;
}
__syncthreads();
/*
* Compute softmax.
*/
__syncthreads();
float accs[NUM_ROWS_PER_THREAD];
for (int block_idx = start_block_idx + warp_idx; block_idx < end_block_idx; block_idx += NUM_WARPS) {
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
accs[i] += dot(logits_vec, v_vec);
}
}
__syncthreads();
/*
* Perform accs reduction across warps.
*/
}
3.3 paged_attention_v2_kernel
paged_attention_v1_kernel将一个head中的attention任务交给一个cuda block完成。如果sequence中context比较长,cuda block承担的任务量将会比较大,甚至有可能出现硬件资源(共享内存,寄存器)不够的情况。这时候,就需要将head中的attention任务拆分成多个cuda block。在vLLM中,每512个token创建一个cuda block。
其他计算逻辑与paged_attention_v1_kernel完全相同。