微服务—DSL基础语法与RestClient操作
本博客为个人学习笔记,学习网站:黑马程序员SpringCloud 2021教程
目录
DSL语法
索引库操作
mapping属性
创建索引库
字段拷贝
查询、删除、修改索引库
文档操作
新增文档
查询、删除文档
修改文档
全量修改
增量修改
DSL文档语法小结
RestClient操作
初始化RestClient
索引库操作
RestClient创建索引库
RestClient删除索引库
RestClient判断索引库是否存在
文档操作
RestClient新增文档
RestClient查询文档
RestClient修改文档
全量修改
增量修改
RestClient删除文档
RestClient批量新增文档
RestClient文档操作小结
DSL语法
索引库操作
mapping属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
1. type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址、分词无意义的值)
数值:long、integer、short、byte、double、float
布尔:boolean
日期:date
对象:object
2. index:是否创建索引,默认为true
3. analyzer:使用哪种分词器
4. properties:该字段的子字段
创建索引库

示例 :
按以下json文档的字段创建一个索引库
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "黑马程序员Java讲师",
"email": "[email protected]",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "云",
"lastName": "赵"
}
}创建索引库DSL语句如下
# 创建索引库
PUT /heima
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstName":{
"type": "keyword"
},
"lastName":{
"type":"keyword"
}
}
}
}
}
}字段拷贝
如果在查询文档时,想要同时基于多个字段进行查询,那么在创建索引库时,可以把这些字段通过"copy_to"拷贝到另外一个字段all中,在之后的搜索中,直接搜索all字段即可。而且,all字段在查询得到的结果文档中是不会显示出来的,但是在查询的时候,会提示可以查询all字段。

查询、删除、修改索引库
查询索引库:
#语法
GET /索引库名
#示例如下
GET /heima删除索引库:
#语法如下
DELETE /索引库名
#示例如下
DELETE /heima修改索引库:
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,就无法修改mapping。虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为这样不会对倒排索引产生影响。
新增字段:
#语法如下
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
#示例如下(新字段名必须和存在的字段名不同)
PUT /heima/_mapping
{
"properties":{
"age":{
"type":"long"
}
}
}文档操作
新增文档
#语法如下
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
#示例如下
POST /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "[email protected]",
"name": {
"firstName": "云",
"lastName": "赵"
}
}查询、删除文档
查询文档:
#语法如下
GET /{索引库名称}/_doc/{id}
#示例如下
GET /heima/_doc/1删除文档:
#语法如下
DELETE /{索引库名}/_doc/id值
#示例如下(根据id删除文档)
DELETE /heima/_doc/1修改文档
修改文档有两种方式:
1. 全量修改:直接覆盖原来的文档
2. 增量修改:修改文档中的部分字段
全量修改
全量修改是覆盖原来的文档,其本质是:先根据指定的id删除文档,再新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
#语法如下
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
#示例如下
PUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "[email protected]",
"name": {
"firstName": "云",
"lastName": "赵"
}
}增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
#语法如下
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
#示例如下
POST /heima/_update/1
{
"doc": {
"email": "[email protected]"
}
}DSL文档语法小结
创建文档:POST/(索引库名}/_doc/文档id {json文档}
查询文档:GET /(索引库名}/_doc/文档id
删除文档:DELETE /(索引库名}/_doc/文档id
修改文档:
全量修改:PUT /(索引库名}/doc/文档id {json文档 }
增量修改:POST/{索引库名}/_update/文档id {“doc":{字段}}
RestClient操作
初始化RestClient
在elasticsearch提供的API中,与elasticsearch一切交互都封装在一个名为RestHighLevelClient的类中,必须先完成这个对象的初始化,建立与elasticsearch的连接。
步骤1. 引入es的RestHighLevelClient依赖:
org.elasticsearch.client
elasticsearch-rest-high-level-client
步骤2. 因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
1.8
7.12.1
步骤3. 初始化RestHighLevelClient,代码如下:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));步骤4. 这里为了单元测试方便,我们创建一个测试类HotelIndexTest,然后将初始化的代码编写在@BeforeEach方法中:
package cn.itcast.hotel;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
public class HotelIndexTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}索引库操作
RestClient创建索引库
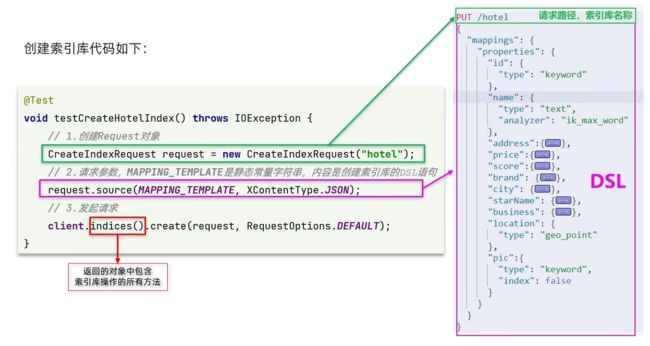
代码如下:
@Test
void createHotelIndex() throws IOException {
// 1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2.准备请求的参数:DSL语句
request.source(MAPPING_TEMPLATE, XContentType.JSON);
// 3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}RestClient删除索引库
@Test
void testDeleteHotelIndex() throws IOException {
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}RestClient判断索引库是否存在
@Test
void testExistsHotelIndex() throws IOException {
// 1.创建Request对象
GetIndexRequest request = new GetIndexRequest("hotel");
// 2.发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3.输出
System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}文档操作
RestClient新增文档
我们需要将数据库的酒店数据查询出来,写入elasticsearch中。而数据库查询后得到的结果是一个Hotel类型的对象。结构如下:
@Data
@TableName("tb_hotel")
public class Hotel {
@TableId(type = IdType.INPUT)
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String longitude;
private String latitude;
private String pic;
}由于该对象的结构与elasticsearch索引库结构存在差异,因此我们需要定义一个新的类型,与索引库结构吻合,结构如下:
package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
新增文档语法:
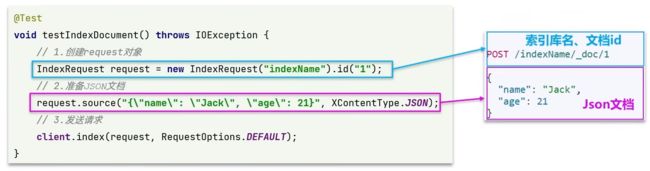
从数据库中查询数据,并新增到ES文档实现:
@Test
void testAddDocument() throws IOException {
// 1.根据id查询酒店数据
Hotel hotel = hotelService.getById(61083L);
// 2.转换为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3.将HotelDoc转json
String json = JSON.toJSONString(hotelDoc);
// 1.准备Request对象
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2.准备Json文档
request.source(json, XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
}RestClient查询文档
查询语法:

代码如下:
@Test
void testGetDocumentById() throws IOException {
// 1.准备Request
GetRequest request = new GetRequest("hotel", "61082");
// 2.发送请求,得到响应
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.解析响应结果
String json = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}RestClient修改文档
在DSL语法中,我们讲过修改文档的两种方式:
1. 全量修改:本质是先根据id删除,再新增
2. 增量修改:修改文档中的指定字段值
全量修改
在Restclient的API中,全量修改与新增的API完全一致,判断依据是ID:
如果新增时,ID已存在,则修改;
如果新增时,ID不存在,则新增。
全量修改的语法这里不再赘述,参考前面的新增文档即可,这里我们主要关注增量修改。
增量修改
增量修改语法如下:
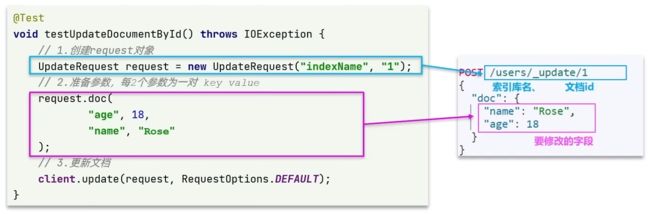
代码如下:
@Test
void testUpdateDocument() throws IOException {
// 1.准备Request
UpdateRequest request = new UpdateRequest("hotel", "61083");
// 2.准备请求参数
request.doc(
"price", "952",
"starName", "四钻"
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
}RestClient删除文档
根据id删除文档,代码如下:
@Test
void testDeleteDocument() throws IOException {
// 1.准备Request
DeleteRequest request = new DeleteRequest("hotel", "61083");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
}RestClient批量新增文档
利用BulkRequest实现批量操作,其本质就是将多个普通的CRUD请求组合在一起发送。
其中提供了一个add方法,我们可以把IndexRequest(新增)、UpdateRequest(修改)、DeleteRequest(删除) 通过add方法进行添加,从而实现批量操作。
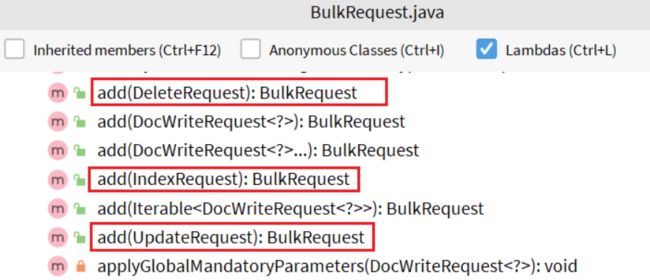
示例:
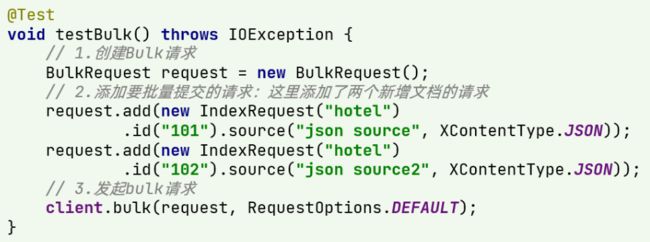
利用MP从数据库获取数据,并批量新增完整代码:
@Test
void testBulkRequest() throws IOException {
// 批量查询酒店数据
List hotels = hotelService.list();
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备参数,添加多个新增的Request
for (Hotel hotel : hotels) {
// 2.1.转换为文档类型HotelDoc
HotelDoc hotelDoc = new HotelDoc(hotel);
// 2.2.创建新增文档的Request对象
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc), XContentType.JSON));
}
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
} RestClient文档操作小结
文档操作的基本步骤:
1. 初始化RestHighLevelClient
2. 创建XxxRequest。XXX是Index、Get、Update、Delete、Bulk
3. 准备参数(Index、Update、Bulk时需要)
4. 发送请求。调用RestHighLevelClient#.xxx()方法,xx是index、get、update、delete、bulk
5. 解析结果(Get时需要)