《分布式系统原理介绍》要点简记
数据备份机制
问题: 机器宕机导致数据丢失问题
解决:
无状态节点则无需读取读取任何信息就可以立刻重新“可用”
有状态节点可以 通过读取本地存储设备中的信息或通过读取其他节点数据的方式恢复内存信息
有状态是指是否是保存数据的节点
序列号机制
问题: 消息乱序
解决: 给消息排号,按照版本号进行消费
校验码机制
问题: 数据错误 消息被抓包篡改
解决: 使用一定的校验码机制可以较为简单的检查出网络数据的错误,从而丢弃错误的数据
序列号机制
问题: TCP协议如何保证数据的可靠传输
解决: TCP协议通过为传输的每一个字节设置 顺序递增的序列号,由接收方在收到数据后按序列号重组数据并发送确认信息,当发现数据包丢失 时,TCP协议重传丢失的数据包,从而 TCP 协议解决了网络数据包丢失的问题和数据包乱序问题。
TCP 协议为每个 TCP 数据段(以太网上通常最大为 1460 字节)使用 32 位的校验和从而检查数据错 误问题。
重试+幂等机制
问题: RPC调用的超时问题, rpc调用超时会导致客户端不知道操作是否成功
解决:1. 发起读请求 判断操作是否成功 2. 设计分布式协议时将执行步骤设计为可重试的,即具有所谓的“幂等性”。幂等性 有外部订单号的话直接先查询,存在则返回 否则一般是在数据库中添加唯一索引保证的
异常考虑分析
某分布式协议实现一个 echo 功能,即由节点 A 向节点 B 发送一个消息,内容是一个整数,节点 B 收到后返回相同的消息。节点 A 发送的消息每次递增加 1。 节点 A 的处理流程为:
-
向节点 B 发送一个消息,消息内容为当前需要发送的整数;
-
等待接收从节点 B 发回的响应消息;
-
若 B 发回的消息等于当前需要发送的整数,
-
a) 将当前需要发送的整数加 1;
-
b) 否则返回 1;
-
上述简单的流程可能遇到各种异常且不能正确处理:第一、当前需要发送的整数没有持久化, 在上述流程中,一旦节点 A 宕机,节点 A 无法继续上述流程。第二、节点 B 一旦宕机,节点 A 不会收到响应消息,流程将卡在第二步无法进行下去。第三、若 A 发给 B 或 B 发回 A 的消息有一个丢失,节点 A 也不会收到响应消息
异常处理黄金原则是:任何在设计阶段考虑到的异常情况一定会在 系统实际运行中发生,但在系统实际运行遇到的异常却很有可能在设计时未能考虑
工程中常常容易出问题的一种思路是认为某种异常出现的概率非常小以至于可以忽略不计
机器数的决定因素
完成某一具体任务的所需要的机器数目取决于系统的性能和任务的要求
元数据机制
问题: 哈希方式rehash数据迁移量大
解决: 可以有专门的元数据服务器
1. 元数据保存的是 余数与机器的对应关系
2. hash取模时一般会多于机器个数 这样一台机器就对应多个余数
当我们系统扩容时,可以把一些余数修改为扩容的机器,这样只有这些余数对应的数据会被迁移,减少迁移量
Hash+按量分段机制
问题: 哈希方式引起数据倾斜
当以用户id 进行哈希取模时 ,假如这个用户的数据量特别大,就会超过对应机器的处理上限,会引起该用户请求不能处理问题。
解决2: 在按哈希分数据的基础上引入按数据量分布 数据的方式,解决该数据倾斜问题
按用户 id 的哈希值分数据,当某个用户 id 的数据量特别大时, 该用户的数据始终落在某一台机器上。此时,引入按数据量分布数据的方式,统计用户的数据量, 并按某一阈值将用户的数据切为多个均匀的数据段,将这些数据段分布到集群中去。由于大部分用 户的数据量不会超过阈值,所以元数据中仅仅保存超过阈值的用户的数据段分布信息,从而可以控 制元数据的规模
解决方案3:一致性哈希
首先通过数据 的哈希值在环上找到对应的虚节点,进而查找元数据找到对应的真实节点。
数据分段机制
问题: 3台机器互为副本的设计
缺点:1. 拷贝数据效率低 2. 可扩展性差
假如一台机器宕机,需要从其他2台机器拷贝数据,一般有2种方法,一种一台副本专门用做拷贝,但是这样只剩下一台副本工作,数据安全性不能保证;另一种是限速拷贝,在压力较小的时段进行拷贝,但是这样速度很慢。
扩展性差,比如新增加了2台机器,无法形成3台机器相互备份的机制,导致扩容失败。
解决:采用数据分段式管理 数据段大小相同
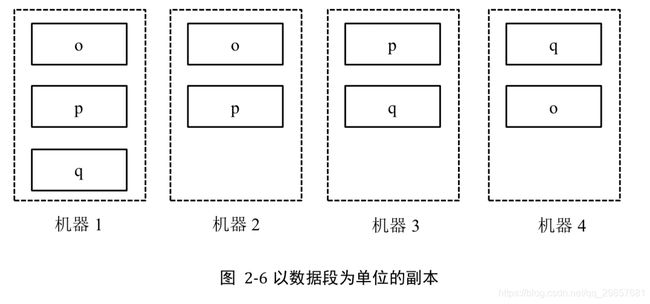
这样一台机器宕机后,就可以使用机器中多台机器同时进行数据恢复,每台机器的压力很小
缺点:需要记录数据段存储在机器的元数据信息
本地化计算
问题:计算节点和存储节点位于不同的物理机器上,需要网络传输数据,带宽会成为系统瓶颈
解决:将计算与存储放在同一个节点上
Quorum机制
问题: 如何实现强一致性(每个副本读到的数据都是最新的)
解决1: 只读主副本
使用主从副本+数据分段存储
主副本做读写,从副本做同步,当从副本同步完成,将从副本设置为可用,对外提供读服务
解决2:
读副本数 > 总数 - 写副本数
- 这样能保证一定读到最新的一条记录
- 然后根据记录的版本号,取最新的记录,这样可以在多个副本中保证读到最新数据.
事务的ACID的实现
问题: 数据库如何实现事务的ACID?
解决:
- 当事务开启时,会将当前记录记录到undo日志中, 失败时可以根据日志回滚
- 然后执行事务 将数据提交到 data buffer中
- 将执行后结果记录到redo日志中
- databuffer 满后 刷新到data file 中 记录check point 点
- 如果刷新时数据库宕机,可以使用redo日志中最近的一次check point记录重新刷新,不用刷新整个redo日志.
0/1 目录机制
问题: mysql的批量操作的原子性怎么实现? 要么同时成功,要么全部失败
解决:
- 通过使用0/1目录,数据底层保存在2个目录上,标记一个目录为活动目录1
- 当进行批量操作时,先把数据都在非活动目录0上进行修改
- 当修改完毕后,将活动目录指定为0
分布式MVCC
问题: 分布式事务
解决:
- 基于 MVCC 的分布式事务的方法为:为每个事务分配一个递增的事务编号,这个编号也代表了 数据的版本号。
- 当事务在各个节点上执行时,各个节点只需记录更新操作及事务编号,当事务在各 个节点都完成后,在全局元信息中记录本次事务的编号。
- 在读取数据时,先读取元信息中已成功的 最大事务编号,再于各个节点上读取数据,只读取更新操作编号小于等于最后最大已成功提交事务 编号的操作,并将这些操作应用到基础数据形成读取结果。
Paxos协议
问题: 分布式一致性问题 (主要是指在多副本的情况下,如何在机器宕机或者网络分化等异常下保证各个副本间数据的一致性)
解决: 主要通过quorum协议实现强一致性
基本流程 (提议者,投票者,学习者):
在满足N/2+1的机器返回null时,发起赋值请求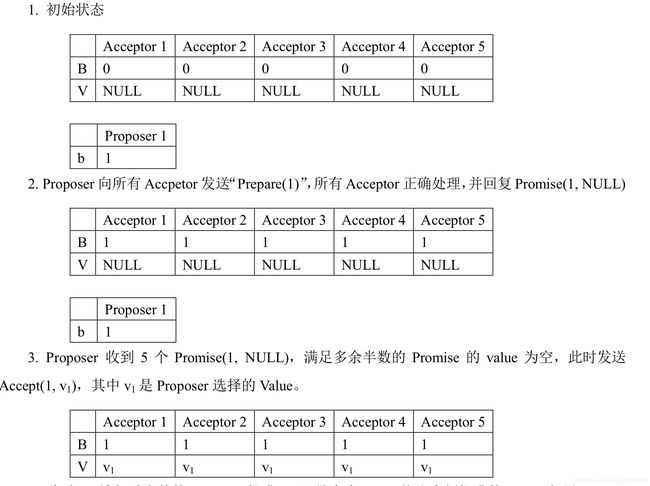
只要在某一轮中选出票数 大于N/2 + 1 者,则后续轮中投票结果不会改变
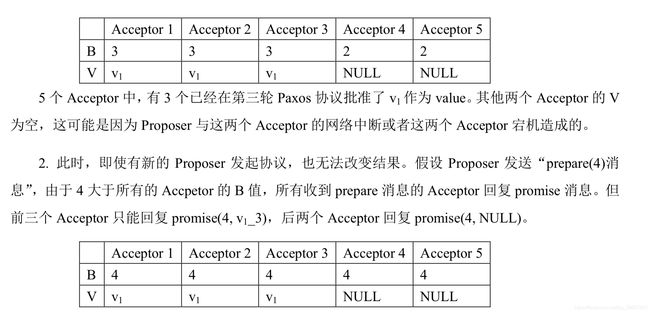
这样无论机器宕机还是网络分化(机器4,5出现不一致)都不会影响数据的一致性
ZAB协议
核心解决的问题:
分布式一致性
主收到消息 保存本地 开启事务
从节点收到消息保存本地 然后反馈ack
主收到过半ack 提交事务 进行广播
从提交事务 然后ack
主响应客户端
为什么要收到过半ack?
quorum机制 读的节点数 > 总数 - 写的节点数 保证一定可以读到最新的事务
怎么避免脑裂?
强制节点数是奇数, 这样比如有9个节点, 网络分化后变成 4,5 那么 5的局域网还是可以收到9/2 过半的响应
leader + quorum
1. 首先选举leader
2. 两阶段提交 prepare(1. 广播事务 2. 收到半数以上回复即可) + commit
数据同步过程:
- leader将请求封装成一个事务,分配全局唯一的zxid
- leader将事务放到为每个follower分配的消息队列中异步解偶提高性能
- follower收到消息后,先存储本地日志,然后反馈ack
- leader 收到过半ack后,广播提交事务,自己提交事务
- follower提交事务,并反馈ack
- leader收到过半ack后,告诉客户端操作成功
Zookeeper 客户端会随机的链接到 zookeeper 集群中的一个节点,如果是读请求,就直接从当前节点中读取数据;如果是写请求,那么节点就会向 Leader 提交事务,Leader 接收到事务提交,会广播该事务,只要超过半数节点写入成功,该事务就会被提交
leader单节点问题:
当整个集群启动过程中,或者当 Leader 服务器出现网络中弄断、崩溃退出或重启等异常时,Zab协议就会 进入崩溃恢复模式,选举产生新的Leader。然后同步各节点数据与新leader数据一致,将集群状态改为可用.
leader选举 (Fast Leader Election):
FLE 会选举拥有最新lastZxid最大的节点作为 Leader,这样就省去了发现最新提议的步骤。这是基于拥有最新提议的节点也拥有最新的提交记录
1)选 epoch 最大的
2)若 epoch 相等,选 zxid 最大的
3)若 epoch 和 zxid 相等,选择 server_id 最大的(zoo.cfg中的myid)
zab协议怎么解决脑裂问题?
每当选举产生一个新的 Leader ,就会从这个 Leader 服务器上取出本地事务日志充最大编号 Proposal 的 zxid,并从 zxid 中解析得到对应的 epoch 编号,然后再对其加1,之后该编号就作为新的 epoch 值,并将低32位数字归零,由0开始重新生成zxid。