分布式id解决方案
分布式id解决方案
背景: 系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,也常常为这个问题而纠结。生成ID的方法有很多,适应不同的场景、需求以及性能要求。
原因:ID是数据的唯一标识,传统的做法是利用UUID和数据库的自增ID,在互联网企业中,大部分公司使用的都是Mysql,并且因为需要事务支持,所以通常会使用Innodb存储引擎,UUID太长以及无序,所以并不适合在Innodb中来作为主键,自增ID比较合适,但是随着公司的业务发展,数据量将越来越大,需要对数据进行分表,而分表后,每个表中的数据都会按自己的节奏进行自增,很有可能出现ID冲突。这时就需要一个单独的机制来负责生成唯一ID,生成出来的ID也可以叫做分布式ID,或全局ID。
一、用redis实现分布式id
1、Redis实现方式
Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
优点:不依赖于数据库,灵活方便,且性能优于数据库;数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:如果系统中没有Redis,还需要引入新的组件,增加系统复杂度;需要编码和配置的工作量比较大
2、Redis的持久化
使用redis的效率是非常高的,但是要考虑持久化的问题。Redis本身就有自带持久化功能,但宕机或重启时可以用于恢复数据,主要有rdb与aof 两种方式。
如果开启 RDB 持久化,由于最近一次快照时间和最新一条 HINCRBY 命令的时间有可能存在时间差,宕机后通过 RDB 快照恢复数据集会发生取号重复的情况
如果使用 AOF 持久化,通过追加写命令到 AOF 文件的方式记录所有 Redis 服务器的写命令,不会发生取号重复的情况。但 AOF 持久化会损耗性能并且在宕机重启后可能由于文件过大导致恢复数据时间过长,并且通过 AOF 重写来压缩文件,在写 AOF 时发生宕机导致文件出错,则需要较多时间去人为恢复 AOF 文件
3、解决方法
3.1Redis HINCRBY 命令
Redis 的 INCR 命令支持 “INCR AND GET” 原子操作。利用这个特性,我们可以在 Redis 中存序列号,让分布式环境中多个取号服务在 Redis 中通过 INCR 命令来实现取号;同时 Redis 是单进程单线程架构,不会因为多个取号方的 INCR 命令导致取号重复。因此,基于 Redis 的 INCR 命令实现序列号的生成基本能满足全局唯一与单调递增的特性,并且性能还不错。
实际上,为了存储序列号的更多相关信息,我们使用了 Redis 的 Hash 数据结构,Redis 同样为 Hash 提供 HINCRBY 命令来实现 “INCR AND GET” 原子操作。
3.2解决方案
利用mysql记录最大序列号 max,当 Redis 中当前可取序列号等于 max 时自动更新 max 到一个适当的值,存入数据库和 Redis。在 Redis 宕机的情况下,将从数据库拉取最大值复成 Redis 当前已取序列号,防止 Redis 取号重复。当然,mysql也可能发生宕机,不过由于取号操作在 Redis,可增加最大可取序列号来提供足够时间恢复mysql。
3.3 Redis设计
采用原子性hash,具体设计如下:
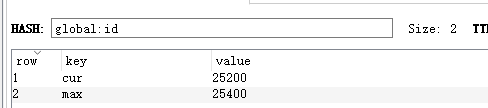
其中:
cur:表示当前游标位置,即最新生成的序列号id
max: 表示当前情况下允许生成的最大序列号
使用lua脚本语言:
情况1:
cur为空
1、刚刚启动服务
2、宕机后重新启动服务
返回-1,从MySQL中查找max,将max相应大小,写入mysql,写入redis,需分布式锁
情况2:
cur >= max
返回nil,需分布式锁,将max从redis取出,后增加增量后写入mysql与redis
local curSeqNumStr = redis.pcall('HGET', KEYS[1], ARGV[2])
if not curSeqNumStr
then
return -1
end
local maxSeqNumStr = redis.pcall('HGET', KEYS[1], ARGV[1])
local maxSeqNum = tonumber(maxSeqNumStr)
local curSeqNum = tonumber(curSeqNumStr)
if curSeqNum < maxSeqNum
then
local seqNum = redis.pcall('HINCRBY', KEYS[1], ARGV[2], ARGV[3])
return seqNum
else
return nil
end
在代码中当前采用Jedis连接。
Long eval = (Long) jedis.eval(script, Collections.singletonList(key), fields);
分布式锁:
设置超时时间,避免死锁
加锁:
String result = jedis.set(lock, requestId, "NX", "PX", 30000);
解锁:
String script2 = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
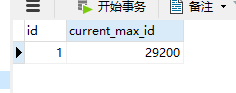
3.4Mysql设计
CREATE TABLE `id_generator` (
`id` int(10) NOT NULL,
`current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
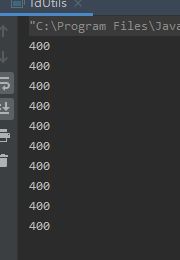
3.5 简单测试
for (int j = 0; j < 10; j++) {
new Thread(() -> {
HashSet<Long> longs = new HashSet<>();
for (int i = 0; i < 400; i++) {
longs.add(getID());
}
System.out.println(longs.size());
}).start();
}
3.6后期优化
可以将max的增长写出一个定时任务,根据实际情况调整max的大小,避免频繁触发分布式锁
二、雪花算法实现全局id
1、概述
SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图:
这个最高位固定是0
● 41位,用来记录时间戳(毫秒)。 41位可以表示2^{41}-1个数字, 如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至 2^{41}-1,减1是因为可表示的数值范围是从0开始算的,而不是1。 也就是说41位可以表示2{41}-1个毫秒的值,转化成单位年则是(2{41}-1) / (1000 * 60 * 60 * 24 * 365) = 69年
● 10位,用来记录工作机器id。可以部署在2^{10} = 1024个节点,包括 5位datacenterId 和 5位workerId ,5位(bit)可以表示的最大正整数是2^{5}-1 = 31,即可以用0、1、2、3、…31这32个数字,来表示不同的datecenterId或workerId
● 12位,序列号,用来记录同毫秒内产生的不同id。 12位(bit)可以表示的最大正整数是2^{12}-1 = 4095,即可以用0、1、2、3、…4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
SnowFlake可以保证:
● 所有生成的id按时间趋势递增
● 整个分布式系统内不会产生重复id(因为有datacenterId和workerId来做区分)
2、实现
雪花算法的关键点即是中间10位的工作机器id,因为需要datacenterId和workerId来做区分,每个微服务可能拥有唯一的id可以使用,本次我将使workId用服务器hostName生成,使dataCenterId用IP生成,这样可以最大限度防止10位机器码重复,但是由于两个ID都不能超过32,只能取余数,还是难免产生重复,但是实际使用中,hostName和IP的配置一般连续或相近,只要不是刚好相隔32位,就不会有问题,况且,hostName和IP同时相隔32的情况更加是几乎不可能的事,平时做的分布式部署,一般也不会超过10台容器。
这里需要将hostName与IP转换为十进制unicode码,然后累加模以32等到相应的workId与dataCenterId,然后按位相加。所以这里需要用到StringUtils.toCodePoints(String string)方法,需引入依赖:
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.8version>
dependency>
主要实现方法:
/**
* 获得下一个ID (该方法是线程安全的)
*
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift)
| (dataCenterId << dataCenterIdShift)
| (workerId << workerIdShift)
| sequence;
}
三、Zookeeper实现全局id
1、zookeeper概述
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在$zookeeper_home\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
2、zookeeper的数据结构
zookeeper的数据节点可以视为树状结构(或者目录),树中的各节点被称为znode(即zookeepernode),一个znode可以有多个子节点。zookeeper节点在结构上表现为树状;使用路径path来定位某个znode,比如/ns1/itcast/mysql/schema1/table1,此处ns-1、itcast、mysql、schema1、table1分别是根节点、2级节点、3级节点以及4级节点;其中ns-1是itcast的父节点,itcast是ns-1的子节点,itcast是mysql的父节点,mysql是itcast的子节点,以此类推。
znode,兼具文件和目录两种特点。既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分。
3、解决方法
在过去的单库单表型系统中,通常可以使用数据库字段自带的auto_increment属性来自动为每条记录生成一个唯一的ID。但是分库分表后,就无法在依靠数据库的auto_increment属性来唯一标识一条记录了。此时我们就可以用zookeeper在分布式环境下生成全局唯一ID。根据Zookeeper的特性,有2种解决方式:
方式一:
这里使用到了临时顺序节点(EPHEMERAL_SEQUENTIAL),当session结束后,节点会被清除。
设计思路:
1.连接zookeeper服务器
2.指定路径生成临时有序节点
3.取序列号及为分布式环境下的唯一ID
主要用到的方法:
//创建临时有序节点
path = zooKeeper.create(defaultPath, new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
return path.substring(9);
方式二:
在zookeeper中,每个znode节点的stat中都有version版本号,当znode节点被更新时,版本好就会加一。因此,要生成一个新Id时,创建一个持久顺序节点,创建操作返回的节点序号,即为新Id,然后把比自己节点小的删除即可。
设计思路:
1.连接zookeeper服务器
2.查看路径是否存在该节点,若不存在,则创建节点
3.修改(set方法)该路径下的值
4.获得其返回的stat获得其版本号
主要方法:
Stat stat = zooKeeper.setData(defaultPath, new byte[0], -1);
return stat.getVersion();