Flink-部署实践
Flink部署
Standalone 模式
安装
解压缩flink-1.10.1-bin-scala_2.12.tgz,进入 conf 目录中。
1 )修改 flink/conf/flink-conf.yaml 文件:
jobmanager.rpc.address: hadoop113
2 )修改 /conf/masters 文件:
hadoop113
3 )修改 /conf/slaves 文件:
hadoop114
hadoop115
4 )分发给另外两台机子
5 )启动集群
./bin/start-cluster.sh
提交任务代码如下:
public class WordCount {
public static void main(String[] args) throws Exception {
// 创建流处理执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
// env.setParallelism(10);
// 用Parameter tool工具从程序启动参数中提取配置项
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
DataStreamSource<String> inputDataStream = env.socketTextStream(host, port);
// 基于数据流记性转换计算
DataStream<Tuple2<String, Integer>> resultStream = inputDataStream.flatMap(new WordCountBatch.MyFlatMapper())
.keyBy(0)
.sum(1).setParallelism(2);
resultStream.print().setParallelism(1);
// 执行任务
env.execute();
}
}
提交任务
并行度优先级:代码中任务后的setParallelism(x) > 代码中的环境的env.setParallelism(x) > 提交任务时配置的并行度 > Flink集群配置文件中的并行度。

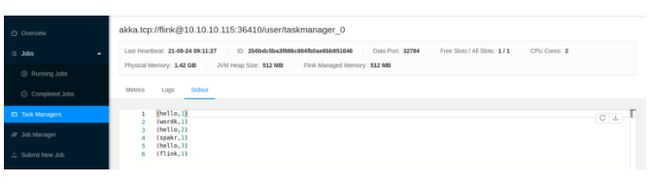
通过submit进行运行,如果最大的并行度大于当前可用的taskslots的话,任务是执行不起来的,会一直卡这等待,因为到那一步的时候资源不够。
任务所占用的slots数就是该任务中最大的并行度任务的并行数。
因此需要修改flink配置文件flink-conf.yaml中的
taskmanager.numberOfTaskSlots: 1
将其改成与当前taskmanager的cpu核数。
命令行提交
## 提交任务
./bin/flink run -c com.starnet.test.WordCount ./data/Flink-1.0-SNAPSHOT.jar --host hadoop113 --port 7777
## 返回以下这个就说明提交成功了
Job has been submitted with JobID f8144b8ef00043dcf633ebad4b4b9800
## 查看正在执行的任务列表
./bin/flink list
Waiting for response...
------------------ Running/Restarting Jobs -------------------
24.08.2021 09:17:08 : f8144b8ef00043dcf633ebad4b4b9800 : Flink Streaming Job (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
## 取消任务
./bin/flink cancel f8144b8ef00043dcf633ebad4b4b9800
## 查看所有的任务
./bin/flink list -a
Waiting for response...
No running jobs.
No scheduled jobs.
---------------------- Terminated Jobs -----------------------
24.08.2021 09:17:08 : f8144b8ef00043dcf633ebad4b4b9800 : Flink Streaming Job (CANCELED)
--------------------------------------------------------------
Yarn 模式
以 Yarn 模式部署 Flink 任务时,要求 Flink 是有 Hadoop 支持的版本,Hadoop环境需要保证版本在 2.2 以上,并且集群中安装有 HDFS 服务。
Flink on Yarn
Flink 提供了两种在 yarn 上运行的模式,分别为 Session-Cluster 和 Per-Job-Cluster模式。
Session-cluster 模 式 :
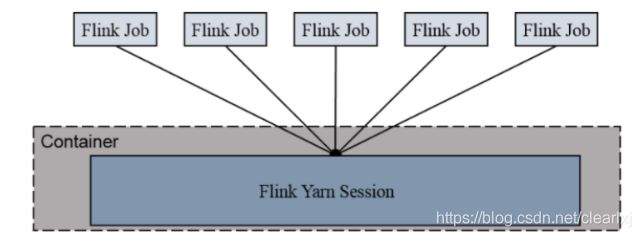
Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远 保 持不变。如果资源满 了 ,下一个作业就无法 提 交,只能等到yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小,执行时间短的作业。
在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn 集群中,除非手工停止。
Per-Job-Cluster 模 式:
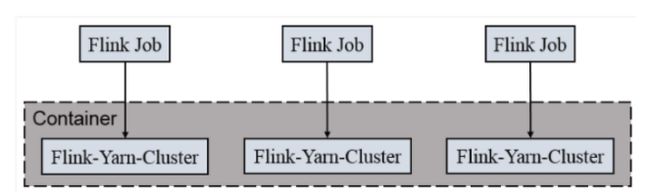
一个 Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn申请资源,直到作业 执 行完成,一个作业的 失 败与否并不会影响下 一 个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大,长时间运行的作业。
每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
Session Cluster
1 ) 启动hadoop集群
2 ) 启动 yarn-session
./bin/yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
其中:
-n(--container):TaskManager的数量,不指定时,集群会根据yarn上面的资源和task的数量动态的去申请,这样是最好的,能够提高集群的动态扩展能力。
-s(--slots): 每个 TaskManager 的 slot 数量,默认一个 slot 一个 core,默认每个
taskmanager 的 slot 的个 数为 1,有时可以多一些 taskmanager,做冗余。
-jm:JobManager 的内存 (单位 MB)。
-tm:每个 taskmanager 的内存(单位 MB)。
-nm:yarn 的 appName(现在 yarn 的 ui 上的名字)。
-d:后台执行。
3 ) 提交作业
./bin/flink run -c com.starnet.test.WordCount ./data/Flink-1.0-SNAPSHOT.jar --host hadoop113 --port 7777
查看任务
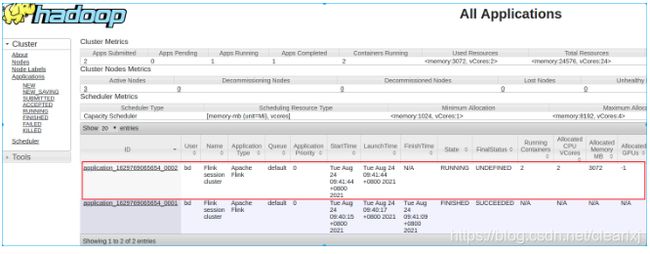
其中002就是session-cluster任务,关闭yarnsession的话,使用以下:
yarn application --kill application_1629769065654_0002
## 或者直接控制台Ctrl+c关闭
关闭任务的话,可以通过命令行进行关闭,也可以通过提交任务时返回的webUI去进行关闭
Found Web Interface hadoop114:43657 of application 'application_1629769065654_0002'.
Per Job Cluster
1 ) 启动hadoop集群
2 ) 不启动yarn-session,直接执行job,直接将任务提交到yarn上执行。
./bin/flink run –m yarn-cluster -c com.starnet.test.WordCount ./data/Flink-1.0-SNAPSHOT.jar --host hadoop113 --port 7777
Kubernetes 部署
容器化部署时目前业界很流行的一项技术,基于 Docker 镜像运行能够让用户更加 方 便 地 对 应 用 进 行 管 理 和 运 维 。 容 器 管 理 工 具 中 最 为 流 行 的 就 是 Kubernetes(k8s),而 Flink 也在最近的版本中支持了 k8s 部署模式。
1 ) 搭建 Kubernetes 集群
2 ) 配置各组件的 yaml 文件
在 k8s 上构建 Flink Session Cluster,需要将 Flink 集群的组件对应的 docker 镜像分别在 k8s 上启动,包括 JobManager、TaskManager、JobManagerService 三个镜像服务。每个镜像服务都可以从中央镜像仓库中获取。
3 )启动 Flink Session Cluster
// 启动 jobmanager-service 服 务
kubectl create -f jobmanager-service.yaml
// 启动 jobmanager-deployment 服 务
kubectl create -f jobmanager-deployment.yaml
// 启动 taskmanager-deployment 服 务
kubectl create -f taskmanager-deployment.yaml
4 )访问 Flink UI 页面
集群启动后,就可以通过 JobManagerServicers 中配置的 WebUI 端口,用浏览器输入以下 url 来访问 Flink UI 页面了:
http://{JobManagerHost:Port}/api/v1/namespaces/default/services/flink-jobmanager:ui/proxy