数据结构学习笔记 2-1 二叉树(Binary Tree)与 LeetCode真题(Java)
喜欢该类型文章可以给博主点个关注,博主会持续输出此类型的文章,知识点很全面,再加上LeetCode的真题练习,每一个LeetCode题解我都写了详细注释,比较适合新手入门数据结构与算法,后续也会更新进阶的文章。
课件参考—开课吧《门徒计划》
2-1 二叉树(Binary Tree)与经典问题
二叉树基础知识
树形结构

树的结构就像是一个链表,但节点的指向由一个变为了多个:

二叉树

度是图中的概念,我们可以理解为边,就是每一个节点最多连接两个节点,一个叫左孩子lchild,一个叫右孩子rchild。
如果一棵树满足这两个条件的约束,那么它就是一棵二叉树。
二叉树的遍历方式

三种二叉树

数组存储二叉树
我们数据结构所有最基础的结构都是在线性结构基础之上的,我们用数组表示一棵二叉树:

这里就体现完全二叉树的重要性了,因它是连续的,中间没有断层,完全二叉树隐含的向我们表示了它的存储是连续的,所以所有的节点都是连续的;
-
链表:记录式 n e x t → n e x t next→next next→next
-
数组:计算式(如上图)
学习二叉树的作用

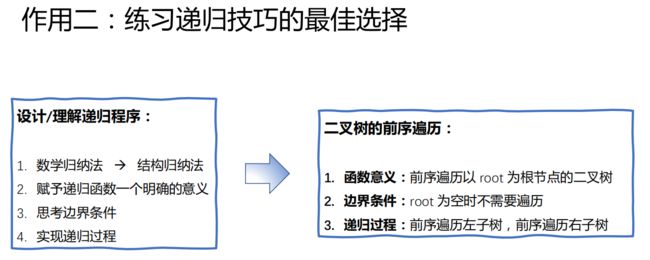

LeetCode真题
经典面试题—二叉树的基本操作
LeetCode144. 二叉树的前序遍历
难度:easy
利用递归实现二叉树的前序遍历:根左右
LeetCode题解:代码实现
LeetCode589. N 叉树的前序遍历
难度:easy
二叉树是递归两次,那么 N N N 叉树我们有几个叉就递归几次。
在 N o d e Node Node 类中有一个 c h i l d r e n children children 集合,它存储着一个根节点所有的子节点。
LeetCode题解:代码实现
LeetCode226. 翻转二叉树
难度:easy
这道题为什么可以用递归来做呢?站在 4 4 4 节点的角度,我们只是把 2 2 2 和 7 7 7 进行了翻转,再站在 2 2 2 和 7 7 7 节点的角度我们只是把 1 1 1 和 3 3 3、 6 6 6 和 9 9 9 进行了翻转。
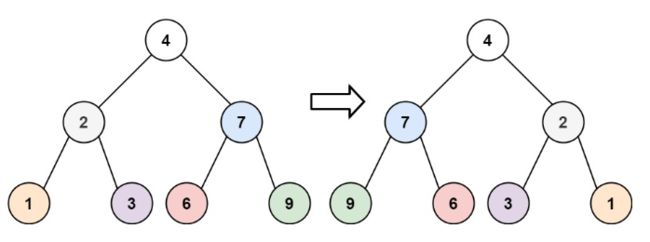
那么这个递归程序应该怎么设计呢?我们要先想清楚要怎么遍历这棵二叉树,其实就是前序遍历,因为我们在上面思考的时候,也是先思考根节点,然后再思考左右节点。
如果我们确定了这道题是前序遍历→根左右,那么左右节点的遍历不需要我们去想,我们只需要仔细思考如何处理根节点。
我们要先把当前根节点左右两边的值翻转,然后再递归的去调换左边、右边的值。
后序遍历也可以,自顶向下或者自底向上,要保证先处理根节点,或者最后处理根节点。
LeetCode题解:代码实现
LeetCode剑指 Offer 32 - II. 从上到下打印二叉树 II
难度:easy
递归方法(dfs:栈)
其实这道题有点像层序遍历,用广搜非常简单,但我们试一下递归能否实现。
我们在递归的时候记录一下层数,哪个节点在第几层我们就把它放到哪层集合中。
最后是从左到右输出,所以我们先遍历这一层的左边,再遍历这一层的右边。
其实这个时候前中后序遍历都可以,我们只需要正确的遍历这棵二叉树即可。
层序遍历方法(bfs:队列)
一层一层的从上到下遍历,也是按照从左到右遍历。
LeetCode题解:两种方法代码实现
对比下来dfs的方法会快一些。
LeetCode107. 二叉树的层序遍历 II
难度:mid
这道题跟上一道题很像,只不过需要我们逆置输出。
可以直接用Collections.reverse()逆置集合。
LeetCode题解:代码实现
LeetCode103. 二叉树的锯齿形层序遍历
难度:mid
锯齿形遍历,奇数行从左到右输出,偶数行从右到左输出,我们可以只对偶数行的集合进行逆置即可。
LeetCode题解:代码实现
经典面试题—二叉树的进阶操作
LeetCode110. 平衡二叉树
难度:easy
什么是一棵平衡二叉树呢?
本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
像这个就是平衡二叉树,因为左子树和右子树的高度差为 1 1 1 , 2 − 1 = 1 2 - 1 = 1 2−1=1。

但这个就是一棵失衡二叉树了,因为左子树和右子树的高度差为 2 2 2 了, 3 − 1 = 2 3 - 1 = 2 3−1=2。

其实这道题是后序遍历的思想,判断一棵二叉树是否是二叉平衡树,要先判断它的左边是否失衡,再判断右边是否失衡,最后判断根节点是否失衡。
递归步骤:
- 看左子树的高度 l l l
- 看右子树的高度 r r r
- ∣ l − r ∣ ⩽ 1 |l - r|\leqslant1 ∣l−r∣⩽1
LeetCode题解:代码实现
LeetCode112. 路径总和
难度:easy
叶子节点就是没有儿子的节点。
对于这道题,我刚开始的思想就是存储一个 a n s ans ans,遍历到一个节点 a n s + = r o o t . v a l ans += root.val ans+=root.val,最后判断 a n s = = t a r g e t S u m ans == targetSum ans==targetSum;
但是我们可以每遍历一个节点就使 t a r g e t S u m targetSum targetSum 减去当前节点的值, t a r g e t S u m − = r o o t . v a l targetSum\ -\!= root.val targetSum −=root.val;
最后判断 t a r g e t S u m = = r o o t . v a l targetSum== root.val targetSum==root.val,如果相等则返回 t r u e true true。
LeetCode题解:代码实现
LeetCode105. 从前序与中序遍历序列构造二叉树
难度:mid
从这道题开始后面的题就都比较绕了。
给我们一颗树的前序遍历以及中序遍历,让我们把这棵二叉树构造出来。
我们分析示例1,前序遍历 → → → 根左右,中序遍历 → → → 左根右,我们可以分析出 3 3 3 就是根节点, 9 9 9 是左子树的节点, 15 20 7 15\ 20\ 7 15 20 7 是右子树的节点。

接下来我们再判断剩下的值,那么 20 20 20 就是根节点, 15 15 15 和 7 7 7 就分别是左右节点。

我们把大问题分解成了子问题,所以这道题依旧是递归的思想。
因为我们既要参照前序遍历,也要参照中序遍历,所以本题我们可以借助桶排序来存储前序遍历根节点在中序遍历的下标,便于快速找到左右子树。
这里我们用Map实现桶排序/哈希表。
具体请参考题解中的注释。
LeetCode题解:代码实现
LeetCode222. 完全二叉树的节点个数
难度:mid
求一棵完全二叉树的节点个数,其实就是递归遍历求左子树和右子树的个数,它们两个相加再加上根节点的个数 1 1 1,就是完全二叉树的节点数。
两行代码搞定,一行特判,一行递归左右子树。
这样的递归固然是能求出来所有二叉树节点的个数,但题中问我们的是完全二叉树,他想要的肯定不是这种简单通用的解法,注意题中有一段话:
**进阶:**遍历树来统计节点是一种时间复杂度为
O(n)的简单解决方案。你可以设计一个更快的算法吗?
我们的完全二叉树无非就是这四种情况:

不妨假设左子树的高度为 l l l ,右子树的高度为 r r r,利用完全二叉树的性质:
- 当 l = = r l ==r l==r 时,也就是③④这种情况,左树必定是满的,所以求左树节点数就是 2 l − 1 2^l-1 2l−1,右树节点数依旧用递归的方法去求。
- 当 l ! = r l\ \ !\!=r l !=r 时, 也就是①②这种情况,右树必然是满的,所以求右树节点数就是 2 r − 1 2^r-1 2r−1,左树节点数同上。
LeetCode题解:两种方法代码实现
第二种解法才是出题人想要的解法。
LeetCode剑指 Offer 54. 二叉搜索树的第k大节点
难度:easy
二叉搜索树就是左子树比根节点小,右子树比根节点大的树,如图:
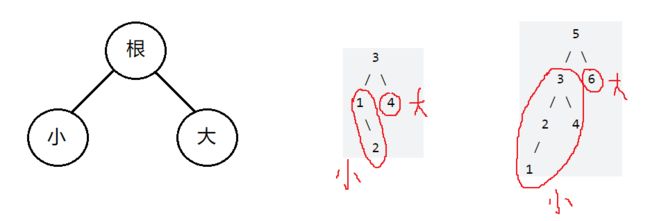
其实二叉搜索树很像二分,因为我们二分找到一个端点,左边的值都比端点小,右边的值都比端点大,整个二分展开之后就是二叉搜索树的状态。
二叉搜索树的效率非常高,单次查找可以达到 l o g n logn logn 的级别。
左 子 树 < 根 < 右 子 树 左子树 < 根 < 右子树 左子树<根<右子树,我们可以先求右子树节点的个数 n n n,如果此时 n ⩾ k n \geqslant k n⩾k,那就说明第 k k k 个大的数一定在右子树,如果不满足,则说明在左子树。
LeetCode题解:代码实现
LeetCode剑指 Offer 26. 树的子结构
难度:mid
A A A 中是否有一棵子树长的跟 B B B 一模一样,其实也是遍历这两棵树,我们先拿 B B B 树的根节点与 A A A 树的根节点进行匹配,如果不匹配则往 A A A 树的左右子树遍历,如果匹配则再用 B B B 树的左节点对比该 A A A 树的左节点,右节点依次对比该 A A A 树的右节点,以此类推。
LeetCode题解:代码实现
LeetCode662. 二叉树最大宽度
难度:mid
这道题也是层序遍历,用广搜很好做,但我们依旧先用深搜递归来做。
DFS
最大宽度所在的层,不一定是在最后一层,也有可能是在中间。
我们试着用前序遍历来做,先处理根节点再处理左右节点,
我们在遍历每一层的时候,给每个节点一个编号,把所有节点都标记完后 用编号最大的节点减去编号最小的节点再+1,就是该层的宽度,最后取一个最大宽度。
我们可以用Map来存储每一层的节点。
给每一个节点一个 i n d e x index index 值,如果走向左子树: i n d e x → i n d e x × 2 index → index × 2 index→index×2,走向右子树: i n d e x → i n d e x × 2 + 1 index → index ×2+1 index→index×2+1
该层的宽度就是 i n d e x − m a p . g e t ( l e v e l ) + 1 index - map.get(level) + 1 index−map.get(level)+1
BFS
原理跟深搜差不多,只不过借助队列来做。
LeetCode题解:两种方法代码实现
LeetCode968. 监控二叉树
难度:hard
把这道最难的题放在压轴。
一个监控,放在树的一个节点上,该监控可以监视到它的父节点、子节点以及它自己,给我们一棵树,问我们需要几个监控,可以监视到所有节点。
我们采用最保守的后序遍历,先把根节点的左右节点都遍历一下,看看是否被监视,如果都没被监视,那么回到根节点,根节点也没有被监视,则在根节点放置一个监控。
每一个节点有三种状态,并对这三种状态设置一个权重(可以理解为这个节点代表的值):
- 看不到;权重: 0 0 0
- 看得到,该节点无监控;权重: 1 1 1
- 看得到,该节点有监控;权重: 2 2 2
这道题有点像是模拟题,我们要把每一个节点的状态都想清楚,具体参考代码中的注释。
LeetCode题解:代码实现
总结
树的结构很重要,因为很多高级数据结构都是在树的结构的基础上进行延展(上面有图片)
经过这么多题的训练,我们发现树的遍历方式大多都是递归;
如果在上一章 栈 还是没能好好理解递归,相信学完二叉树这一章你对递归的理解一定上升了很多。
二叉树查找的时间复杂度大部分都是比较快的,因为我们每次查找都会把数据缩小到原来的一半,几乎所有二叉树的算法都会带一个 l o g log log。
本文中提到了深搜dfs和广搜bfs,其实深搜就是用递归实现的,后续也会对这两个算法进行讲解。