政安晨:【完全零基础】认知人工智能(四)【超级简单】的【机器学习神经网络】—— 权重矩阵
预备
如果小伙伴们第一次看到这篇文章,同时也对这类知识还是稍感陌生的话,可以先看看我这个系列的前三篇文章:
政安晨:【完全零基础】认知人工智能(一)【超级简单】的【机器学习神经网络】 —— 预测机 https://blog.csdn.net/snowdenkeke/article/details/136139504政安晨:【完全零基础】认知人工智能(二)【超级简单】的【机器学习神经网络】—— 底层算法https://blog.csdn.net/snowdenkeke/article/details/136141888政安晨:【完全零基础】认知人工智能(三)【超级简单】的【机器学习神经网络】—— 三层神经网络示例https://blog.csdn.net/snowdenkeke/article/details/136151970有了一定的知识准备后,小伙伴们,咱们这就开始。
https://blog.csdn.net/snowdenkeke/article/details/136139504政安晨:【完全零基础】认知人工智能(二)【超级简单】的【机器学习神经网络】—— 底层算法https://blog.csdn.net/snowdenkeke/article/details/136141888政安晨:【完全零基础】认知人工智能(三)【超级简单】的【机器学习神经网络】—— 三层神经网络示例https://blog.csdn.net/snowdenkeke/article/details/136151970有了一定的知识准备后,小伙伴们,咱们这就开始。
矩阵乘法反向传播误差
应该有不少小伙伴一看到标题就一头雾水吧,咱们先解释一二:
在人工智能神经网络中,矩阵乘法是神经网络中非常重要的操作之一。
1. 在前向传播过程中,输入与权重矩阵相乘,并经过激活函数,得到神经网络的输出。
2. 在神经网络中,我们也需要通过反向传播算法来调整权重矩阵,使得网络的输出与目标输出尽可能接近。
矩阵乘法反向传播误差就是在反向传播过程中计算误差梯度的一种方法。具体而言,它使用了链式法则和矩阵乘法的运算规则。
假设有一个简单的神经网络,包含一个输入向量x,一个权重矩阵W和一个输出向量y。
在前向传播过程中,通过以下公式计算出输出向量y:
y = W * x
在反向传播过程中,我们需要计算误差关于权重矩阵W的梯度。
梯度表示了误差函数对于权重的变化率,可以告诉我们应该如何调整权重才能使误差最小化。
使用矩阵乘法反向传播误差方法,我们首先计算出误差关于输出向量y的梯度,表示为delta_y,然后,我们可以通过以下公式计算误差关于权重矩阵W的梯度:
delta_W = delta_y * x^T
其中,^T表示矩阵的转置。(这个概念咱们本文接下来会细讲)
通过计算误差关于权重矩阵W的梯度,我们可以根据梯度下降算法更新权重矩阵,使得误差逐渐减小。这样,在训练过程中,神经网络可以不断调整权重,从而获得更好的预测能力。
总结起来,矩阵乘法反向传播误差是一种计算误差关于权重矩阵梯度的方法,可以应用于神经网络的训练过程中,帮助网络调整权重以最小化误差。它利用了矩阵乘法和链式法则的性质,使得计算更加高效并具有可扩展性。
用示例的方式讲解
前文提了一点点概念,现在咱们需要用工程落地的思维能够把这个概念的想法实现。
我们可以使用矩阵乘法来简化所有这些劳心费力的计算吗?此前,当我们执行大量计算以得到前馈输入信号时,矩阵乘法帮助了我们。
要明白误差反向传播是否可用通过使用矩阵乘法变得更加简洁,让我们使用符号写出步骤,这就是尝试所谓的将过程(vectorise the process)矢量化。
我们可以相对简单地以矩阵形式表达大批量的计算,这有利于我们的书写,并且由于这种方法利用了所需计算中的相似性,因此这允许计算机更高效地完成所有计算工作。
计算的起始点是在神经网络最终输出层中出现的误差。
此时,在输出层,神经网络只有两个节点,因此误差只有e1和e2。

接下来,我们需要为隐藏层的误差构建矩阵。
这听起来好像是一件挺辛苦的事情,没关系,咱们一点一点地做这件事。
第一件事与隐藏层中的第一个节点相关。
如果你再次观察上图可以看到,在输出层中,有两条路径对隐藏层第一个节点的误差做出了“贡献”。沿着这些路径,我们发现了误差信号 e1* w1,1/ (w1,1+ w2,1) 和e2* w1,2/ ( w1,2+ w2,2)。
现在,让我们看看隐藏层的第二个节点,同样,我们看到了有两条路径对这个误差做出了“贡献”,我们得到误差信号e1*w2,1/ ( w2,1+ w1,1)和e2* w2,2/( w2,2+ w1,2)。先前,我们就已经明白了这些表达式是如何计算得到的。
(再回顾一下上一篇的三层神经网络):
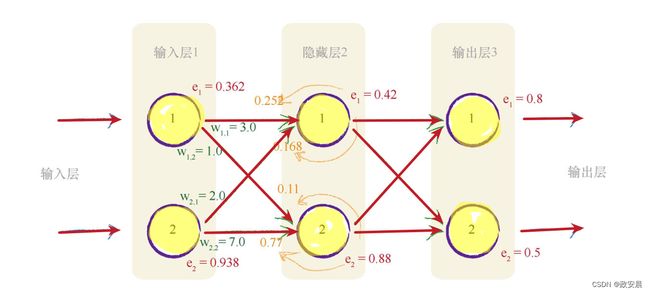
顺着前面的隐藏层说,我们得到了下列的隐藏层矩阵,这比想要的矩阵要复杂一些。

如果这个矩阵能够重写,变成一种我们已知可用、简单的矩阵乘法,那就太好了。
这是权重、前向信号和输出误差矩阵,请记住,如果我们能够重写矩阵,那将是大有裨益的。
遗憾的是,我们不能像先前在处理前馈信号时一样,很容易就将这种矩阵转换为超级简单的矩阵乘法。
在这个超级麻烦的大矩阵中,这些分数难以处理!
如果我们能够将这个麻烦的矩阵整齐地分割成简单可用的矩阵组合,就大有益处了。
我们可以做些什么呢?我们依然非常希望利用矩阵乘法有效完成计算,给我们带来好处。
再次观察上面的表达式,你可以观察到,最重要的事情是输出误差与链接权重wij的乘法,较大的权重就意味着携带较多的输出误差给隐藏层,这是非常重要的一点。这些分数的分母是一种归一化因子,如果我们忽略了这个因子,那么我们仅仅失去后馈误差的大小。也就是说,我们使用简单得多的e1* w1,1来代替e1* w1,1/ (w1,1+ w2,1)。
如果我们采用这种方法,那么矩阵乘法就非常容易辨认:
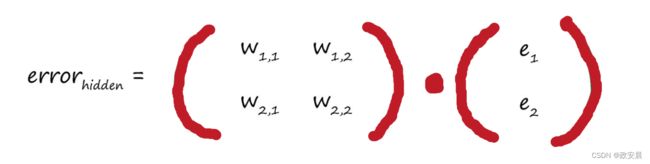
这个权重矩阵与我们先前构建的矩阵很像,但是这个矩阵沿对角线进行了翻转,因此现在右上方的元素变成了左下方的元素,左下方的元素变成了左上方的元素,我们称此为转置矩阵,记为 。
。
以下是两个数字转置矩阵的示例:咱们可以清楚地观察到所发生的事情,即使矩阵的行数和列数不同,也是可以进行转置的。

因此,我们得到所希望的矩阵,使用矩阵的方法来向后传播误差:

虽然这样做看起来不错,但是将归一化因子切除,我们做得正确吗?
实践证明,这种相对简单的误差信号反馈方式,与我们先前相对复杂的方式一样有效,如果这种相对简单的方式行之有效,那么我们就应该坚持这种方法。如果咱们要进一步思考这个问题,那么我们可以观察到,即使反馈的误差过大或过小,在下一轮的学习迭代中,网络也可以自行纠正。重要的是,由于链接权重的强度给出了共享误差的最好指示,因此反馈的误差应该遵循链接权重的强度。
总之,
A . 反向传播误差可以表示为矩阵乘法。
B. 无论网络规模大小,这使我们能够简洁地表达反向传播误差,同时也允许理解矩阵计算的计算机语言更高效、更快速地完成工作。
C. 这意味着前向馈送信号和反向传播误差都可以使用矩阵计算而变得高效。如何更新权重
如何更新权重
到现在咱们还没有解决在神经网络更新链接权重中非常核心的问题。
现在还需要理解一个重要思想:
到目前为止,我们已经理解了让误差反向传播到网络的每一层。
为什么这样做呢?
原因就是,我们使用误差来指导如何调整链接权重,从而改进神经网络输出的总体答案。
这个事本质上是一种试错,也是类似线性分类器所做的事情.
这些节点都不是简单的线性分类器,这些稍微复杂的节点,对加权后的信号进行求和,并应用了S阈值函数,将所得到的结果输出给下一层的节点。
我们如何才能真正地更新连接这些相对复杂节点链接的权重呢?我们为什么不能使用一些微妙的代数来直接计算出权重的正确值呢?
伙计们,对于大部分人来说,数学太复杂了,因此我们不能使用微妙的代数直接计算出的权重。
当我们通过网络前馈信号时,有太多的权重需要组合,太多的函数的函数的函数……需要组合。
想想看,即使是一个只有3层、每层3个神经元的小小的神经网络,就像我们刚才使用的神经网络,也具有太多的权重和函数需要组合。
在此情况下,你如何调整输入层第一个节点和隐藏层第二个节点之间链路的权重,以使得输出层第三个节点的输出增加0.5呢?
即使我们碰运气做到了这一点,这个效果也会由于需要调整另一个权重来改进不同的输出节点而被破坏。你不能将此视为无关紧要的事情。
要意识到这件事情的重要性,请观察下面这个“可爱”的表达式,这是一个简单的3层、每层3个节点的神经网络,其中输入层节点的输出是输入值和链接权重的函数。
在节点i处的输入是xi,连接输入层节点i到隐藏层节点j的链接权重为wi,j,类似地,隐藏层节点j的输出是xj,连接隐藏层节点j和输出层节点k的链接权重是wj,k。那个看似有趣的符号![]() 意味着对在a和b值之间的所有后续表达式求和。
意味着对在a和b值之间的所有后续表达式求和。
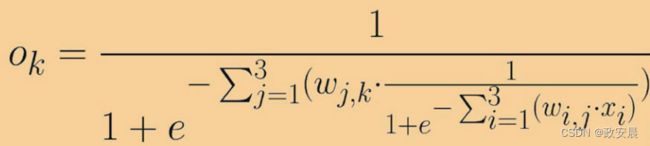
哎呀,妈呀,咱们怎么能去硬碰这种表达式啊!
如果不借助前人的积累,咱们可以只是简单地尝试随机组合权重,直到找到好的权重组合,但这并不是聪明的方式呀,因为这种方法被称为暴力求解方法。
咱们算一笔账:
有些人使用暴力方法试图破解密码,如果密码是一个英文单词并且不算太长,那么由于没有太多的组合,一台快速的家用计算机就可以搞定,因此这种方法是行之有效的。现在,假设每个权重在-1和+1之间有1000种可能的值,如0.501、-0.203和0.999。那么对于3层、每层3个节点的神经网络,我们可以得到18个权重,因此有18000种可能性需要测试。如果有一个相对典型的神经网络,每层有500个节点,那么我们需要测试5亿种权重的可能性。如果每组组合需要花费1秒钟计算,那么对于一个训练样本,我们需要花费16年更新权重!对于1000种训练样本,我们要花费16000年!
现在您发现了吧,这种暴力方法不切实际。事实上,当咱们增加网络层、节点和权重的可能值时,这种方法马上就不可收拾了。
数学家多年来也未解决这个难题,直到20世纪60年代到70年代,这个难题才有了切实可行的求解办法:这个迟来的发现导致了现代神经网络爆炸性的发展,让现在的神经网络可以执行一些令人感到惊奇的任务。
为了解决这个问题,咱们直面现实:
1. 能够表示所有的权重如何生成神经网络输出的数学表达式过于复杂,难以求解,太多的权重组合,难以逐个测试,以找到一种最好的组合。
2. 训练数据可能不足,不能正确地教会网络。
3. 训练数据可能有错误,因此即使我们的假设完全正确,神经网络可以学到一些东西,但却有缺陷。
4. 神经网络本身可能没有足够多的层或节点,不能正确地对问题的解进行建模。
咱们必须承认这些限制,从而采取实际的做法:
如果我们从实际出发可以找到一种办法,虽然这种方法从数学角度而言并不完美,但是由于这种方法没有做出虚假的理想化假设,因此实际上给我们带来了更好的结果。
现在请您想象一下:
一个非常复杂、有波峰波谷的地形以及连绵的群山峻岭,在黑暗中,伸手不见五指,你知道你是在一个山坡上,你需要到坡底。
对于整个地形,你没有精确的地图,只有一把手电筒,你能做什么呢?你可能会使用手电筒,做近距离的观察,你不能使用手电筒看得更远,无论如何,你肯定看不到整个地形。
你可以看到某一块土地看起来是下坡,于是你就小步地往这个方向走,通过这种方式,你不需要完整的地图,也不需要事先制定路线,你一步一个脚印,缓慢地前进,慢慢地下山。

在数学上,这种方法称为梯度下降(gradient descent),你可以明白这是为什么吧:在你迈出一步之后,再次观察周围的地形,看看你下一步往哪个方向走,才能更接近目标,然后,你就往那个方向走出一步。你一直保持这种方式,直到非常欣喜地到达了山底。
梯度是指——地面的坡度。
你走的方向是——最陡的坡度向下的方向。
现在,您再想象一下:这个复杂的地形是一个数学函数。
梯度下降法给我们带来一种能力,即我们不必完全理解复杂的函数,从数学上对函数进行求解,就可以找到最小值,如果函数非常困难,我们不能用代数轻松找到最小值,我们就可以使用这个方法来代替代数方法。
由于我们采用步进的方式接近答案,一点一点地改进所在的位置,因此这可能无法给出精确解,但是,这比得不到答案要好。总之,我们可以使用更小的步子朝着实际的最小值方向迈进,优化答案,直到我们对于所得到的精度感到满意为止。
这种酷炫的梯度下降法与神经网络之间有什么联系呢?
如果我们将复杂困难的函数当作网络误差,那么下山找到最小值就意味着最小化误差,这样我们就可以改进网络输出。这就是我们希望做到的!
为了正确理解梯度下降的思想,让我们再使用一个超级简单的例子来示意一下:
下图显示了一个简单的函数 ![]() , 如果在这个函数中,y表示误差,我们希望找到x,可以最小化y。
, 如果在这个函数中,y表示误差,我们希望找到x,可以最小化y。
现在,我们假装这不是一个简单的函数,而是一个复杂困难的函数。

要应用梯度下降的方法,我们必须找一个起点。
上图显示了随机选择的起点。就像登山者,我们正站在这个地方,环顾四周,观察哪个方向是向下的。在图上标记了当前情况下的斜率,其斜率为负。我们希望沿着向下的方向,因此我们沿着x轴向右,也就是说,我们稍微地增加x的值。这是登山者的第一步,你可以观察到,我们改进了我们的位置,向实际最小值靠近了一些。
咱们又假设在某个地方开始,如下图所示:
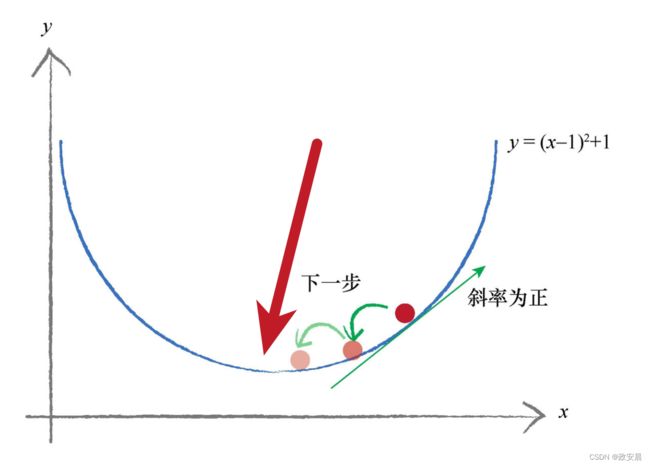
这一次,我们所在之处的斜率为正,因此我们向左移动,也就是说,我们稍微减小x值。同样,你可以观察到我们已经改善了位置,向真实的最小值靠近了一些。我们可以继续这样操作,直到几乎不能改进为止,这样我们就确信已经到达了最小值。
我们要改变步子大小,避免超调,这样就会避免在最小值的地方来回反弹,这是一个必要的优化。
你可以想象,如果我们距离真正的最小值只有0.5米,但是采用2米的步长,那么由于向最小值的方向走的每一步都超过了最小值,我们就会错过最小值。
如果我们调节步长,与梯度的大小成比例,那么在接近最小值时,我们就可以采用小步长。这一假设的基础是,当我们接近最小值时,斜率也变得平缓了,对于大多数光滑的连续函数,这个假设是合适的。但是对于有时突然一跃而起、有时突然急剧下降的锯齿函数而言,也就是说存在数学家所说的间断点,这不是一个合适的假设。
下面我们将详细说明,当函数梯度变得较小时调节步长的这种思想,函数梯度是在何种程度上接近最小值的良好指标:

顺便说一句,你是否注意到,我们往相反的梯度方向增加x值?
正梯度意味着减小x,负梯度意味着增加x。画图可以让这个现象变得很清晰,但是我们很容易忘记这一点,并经常误入歧途。
当使用梯度下降的方法时,我们一般不使用代数计算出最小值,我们假装函数![]() 是一个非常复杂困难的函数,即使不使用数学精确计算出斜率,我们也可以估计出斜率,在我们往一般的正确方向移动时,你可以发现这种方法也非常适用。当函数有很多参数时,这种方法才真正地显现出它的亮点。y也许不单单取决于x, y也可能取决于a、b、c、d、e和f。记得输出函数吧,神经网络的误差函数取决于许多的权重参数,这些参数通常有数百个呢!
是一个非常复杂困难的函数,即使不使用数学精确计算出斜率,我们也可以估计出斜率,在我们往一般的正确方向移动时,你可以发现这种方法也非常适用。当函数有很多参数时,这种方法才真正地显现出它的亮点。y也许不单单取决于x, y也可能取决于a、b、c、d、e和f。记得输出函数吧,神经网络的误差函数取决于许多的权重参数,这些参数通常有数百个呢!
下面我们将使用稍微复杂的、依赖2个参数的函数,详细说明梯度下降法,这可以使用三维空间来表示,同时使用高来表示函数的值:

观察上面这个三维曲面,你可以再次思考,梯度下降是否会终止于右侧的另一个山谷。事实上,在更一般的意义上进行思考,由于复杂的函数有众多的山谷,梯度下降有时会卡在错误的山谷中吗?这个错误的山谷是哪一个呢?答案是肯定的,这种情况可能会发生,也就是我们所到达的山谷可能不是最低的山谷。
为了避免终止于错误的山谷或错误的函数最小值,我们从山上的不同点开始,多次训练神经网络,确保并不总是终止于错误的山谷,不同的起始点意味着选择不同的起始参数,在神经网络的情况下,这意味着选择不同的起始链接权重。
下面详细说明了使用梯度下降方法的三种不同尝试,其中有一次,这种方法终止于错误的山谷中:

现在咱们已经理解了权重矩阵的计算,同时也知道了梯度下降法是形成神经网络的利器。
梯度下降法是求解函数最小值的一种很好的办法,当函数非常复杂困难,并且不能轻易使用数学代数求解函数时,这种方法却发挥了很好的作用。
更重要的是,当函数有很多参数,一些其他方法不切实际,或者会得出错误答案,这种方法依然可以适用。
这种方法也具有弹性,可以容忍不完善的数据,如果我们不能完美地描述函数,或我们偶尔意外地走错了一步,也不会错得离谱。