gin源码实战 day1
gin框架源码实战day1
Radix树
这个路由信息:
r := gin.Default()
r.GET("/", func1)
r.GET("/search/", func2)
r.GET("/support/", func3)
r.GET("/blog/", func4)
r.GET("/blog/:post/", func5)
r.GET("/about-us/", func6)
r.GET("/about-us/team/", func7)
r.GET("/contact/", func8)
得到的路由树解析:
Priority Path Handle
9 \ *<1>
3 ├s nil
2 |├earch\ *<2>
1 |└upport\ *<3>
2 ├blog\ *<4>
1 | └:post nil
1 | └\ *<5>
2 ├about-us\ *<6>
1 | └team\ *<7>
1 └contact\ *<8>
解读:
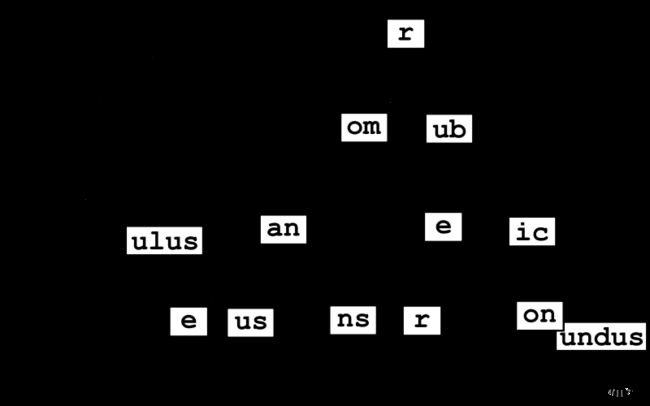
这个图只是把结点的值写在了变上,不要误会,其实值是在点中。
节点:每个节点代表路由路径的一部分。例如,s、earch\ 和 support\ 节点分别代表 /search/ 和 /support/ 路径的组成部分。
分支:节点之间的连接线表示路径的分支。例如,├ 和 └ 符号表示从父节点分出的不同子路径。
叶节点:代表完整的路由路径,通常在叶节点处关联具体的处理函数(如 <1>、<2> 等)。这些处理函数用于响应对应路径的 HTTP 请求。
nil 节点:表示该路径节点是参数路径(如 :post)的一部分,或者是路径的中间部分,而不直接关联处理函数。
路由树详细解读
根节点:\ 代表根节点,即路由的起点。它关联了处理根路径 / 请求的函数 *<1>。
s 分支:表示以 s 开头的路径。它进一步分为两个子路径:earch\(对应 /search/,处理函数 *<2>)和 upport\(对应 /support/,处理函数 *<3>)。
blog\ 分支:代表 /blog/ 路径,关联处理函数 *<4>。它有一个参数子路径 :post\,用于匹配如 /blog/:post/ 形式的路径,最终关联的处理函数是 *<5>。
about-us\ 分支:代表 /about-us/ 路径,关联处理函数 *<6>。它有一个静态子路径 team\,对应 /about-us/team/ 路径,处理函数为 *<7>。
contact\ 分支:代表 /contact/ 路径,关联处理函数 *<8>。
符号说明
├ 和 └:分支符号,├ 用于表示除最后一个分支外的节点,└ 用于表示最后一个分支节点。
nil:表示该节点不直接关联处理函数,可能是因为它是一个参数化的路径部分,或者是未到达叶节点的中间节点。
*<数字>:代表与节点关联的处理函数。数字仅为示例,实际上会是指向处理函数的指针。
源码解读:
从这个最简单的例子,来逐步分析源码
package main
import (
"github.com/gin-gonic/gin"
"log"
"net/http"
)
func main() {
r := gin.Default()
r.GET("/", func(c *gin.Context) {
c.String(http.StatusOK, "ok")
})
err := r.Run(":8080")
if err != nil {
log.Fatalln(err)
}
}
先看启动的过程,也就是run函数
err := r.Run(“:8080”)这个我们只知道是用来启动的,来看看内部是如何启动的。
run函数的源码:
看源码的时候养成一个习惯,关注主要流程,忽略一些不必要的因素。
func (engine *Engine) Run(addr ...string) (err error) {
defer func() { debugPrintError(err) }()
if engine.isUnsafeTrustedProxies() {
debugPrint("[WARNING] You trusted all proxies, this is NOT safe. We recommend you to set a value.\n" +
"Please check https://pkg.go.dev/github.com/gin-gonic/gin#readme-don-t-trust-all-proxies for details.")
}
address := resolveAddress(addr)
debugPrint("Listening and serving HTTP on %s\n", address)
err = http.ListenAndServe(address, engine.Handler())
return
}
该方法是用来启动 Gin 应用并监听 HTTP 请求的。
具体分析:
方法签名 :
func (engine *Engine) Run(addr ...string) (err error) {
engine *Engine:Engine 是 Gin 框架的核心结构体,代表整个 Gin 应用。这里的 engine 是一个指向 Engine 实例的指针,表示 Run 方法是 Engine 的一个方法。
addr …string:这是一个可变参数,表示 Run 方法可以接受一个或多个字符串参数,这些字符串代表监听地址(包括端口号)。如果没有提供参数,默认监听地址是 :8080。
(err error):这是方法的返回值,表示方法执行结束后可能返回的错误。
Engine结构体解读:
type Engine struct {
RouterGroup
// RedirectTrailingSlash enables automatic redirection if the current route can't be matched but a
// handler for the path with (without) the trailing slash exists.
// For example if /foo/ is requested but a route only exists for /foo, the
// client is redirected to /foo with http status code 301 for GET requests
// and 307 for all other request methods.
RedirectTrailingSlash bool
// RedirectFixedPath if enabled, the router tries to fix the current request path, if no
// handle is registered for it.
// First superfluous path elements like ../ or // are removed.
// Afterwards the router does a case-insensitive lookup of the cleaned path.
// If a handle can be found for this route, the router makes a redirection
// to the corrected path with status code 301 for GET requests and 307 for
// all other request methods.
// For example /FOO and /..//Foo could be redirected to /foo.
// RedirectTrailingSlash is independent of this option.
RedirectFixedPath bool
// HandleMethodNotAllowed if enabled, the router checks if another method is allowed for the
// current route, if the current request can not be routed.
// If this is the case, the request is answered with 'Method Not Allowed'
// and HTTP status code 405.
// If no other Method is allowed, the request is delegated to the NotFound
// handler.
HandleMethodNotAllowed bool
// ForwardedByClientIP if enabled, client IP will be parsed from the request's headers that
// match those stored at `(*gin.Engine).RemoteIPHeaders`. If no IP was
// fetched, it falls back to the IP obtained from
// `(*gin.Context).Request.RemoteAddr`.
ForwardedByClientIP bool
// AppEngine was deprecated.
// Deprecated: USE `TrustedPlatform` WITH VALUE `gin.PlatformGoogleAppEngine` INSTEAD
// #726 #755 If enabled, it will trust some headers starting with
// 'X-AppEngine...' for better integration with that PaaS.
AppEngine bool
// UseRawPath if enabled, the url.RawPath will be used to find parameters.
UseRawPath bool
// UnescapePathValues if true, the path value will be unescaped.
// If UseRawPath is false (by default), the UnescapePathValues effectively is true,
// as url.Path gonna be used, which is already unescaped.
UnescapePathValues bool
// RemoveExtraSlash a parameter can be parsed from the URL even with extra slashes.
// See the PR #1817 and issue #1644
RemoveExtraSlash bool
// RemoteIPHeaders list of headers used to obtain the client IP when
// `(*gin.Engine).ForwardedByClientIP` is `true` and
// `(*gin.Context).Request.RemoteAddr` is matched by at least one of the
// network origins of list defined by `(*gin.Engine).SetTrustedProxies()`.
RemoteIPHeaders []string
// TrustedPlatform if set to a constant of value gin.Platform*, trusts the headers set by
// that platform, for example to determine the client IP
TrustedPlatform string
// MaxMultipartMemory value of 'maxMemory' param that is given to http.Request's ParseMultipartForm
// method call.
MaxMultipartMemory int64
// UseH2C enable h2c support.
UseH2C bool
// ContextWithFallback enable fallback Context.Deadline(), Context.Done(), Context.Err() and Context.Value() when Context.Request.Context() is not nil.
ContextWithFallback bool
delims render.Delims
secureJSONPrefix string
HTMLRender render.HTMLRender
FuncMap template.FuncMap
allNoRoute HandlersChain
allNoMethod HandlersChain
noRoute HandlersChain
noMethod HandlersChain
pool sync.Pool
trees methodTrees
maxParams uint16
maxSections uint16
trustedProxies []string
trustedCIDRs []*net.IPNet
}
Engine 结构体是 Gin Web 框架的核心,它继承了 RouterGroup,提供了路由和中间件的管理,同时也包含了很多与 HTTP 服务运行相关的配置。
解读:
1.RouterGroup:
type RouterGroup struct {
Handlers HandlersChain
basePath string
engine *Engine
root bool
}
RouterGroup 是 Gin 框架中用于组织路由和中间件的结构体,它允许开发者将具有共同前缀的路由组织在一起,并且可以共享中间件。这样做有助于代码的组织和复用,使得路由和中间件的管理更加方便和高效。下面是对 RouterGroup 结构体字段的解读:
Handlers HandlersChain: HandlersChain 类型,代表一系列的中间件处理函数。这些处理函数会按照添加的顺序被执行,并且会被绑定到 RouterGroup 下的所有路由上。这意味着,所有在此 RouterGroup 中注册的路由都会先通过这些中间件的处理。
这个地方我当初看我还是没懂,这里我做进一步解读:
HandlersChain 解释
HandlersChain 是一个中间件处理函数的切片(slice),在 Gin 中用于存储一组中间件。中间件是在处理 HTTP 请求之前或之后运行的函数,通常用于执行一些预处理操作(如日志记录、身份验证、数据验证等)或后处理操作(如设置响应头等)。在 RouterGroup 中注册的中间件会自动应用到该组下的所有路由上。
中间件执行流程
当一个请求到达 Gin 服务器时,Gin 会根据请求的 URL 和方法匹配路由。如果匹配成功,Gin 会按照 HandlersChain 中的顺序执行相应的中间件,最后执行路由的主处理函数。每个中间件可以选择:
1.直接返回响应,不再调用后续的中间件或主处理函数。
2.修改请求或响应的内容,然后调用下一个中间件或主处理函数。
3.执行一些不依赖请求内容的操作,如日志记录。
例子:
假设我们有一个 Web 应用,我们想为 /api 路径下的所有路由添加日志和身份验证两个中间件。
package main
import (
"github.com/gin-gonic/gin"
"net/http"
)
// 日志中间件
func LoggerMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
// 记录请求开始的日志
// 注意:这里只是示例,实际使用时可能需要记录更多详细信息
println("Starting request:", c.Request.URL.Path)
c.Next() // 调用下一个中间件或主处理函数
// 请求处理完毕后,记录日志
println("Request finished")
}
}
// 身份验证中间件
func AuthMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
// 检查用户是否已认证
// 这里只是简单示例,实际应用中应该是更复杂的逻辑
token := c.GetHeader("Authorization")
if token != "valid-token" {
// 如果用户未认证,返回 401 状态码并终止请求
c.AbortWithStatus(http.StatusUnauthorized)
return
}
c.Next() // 用户已认证,继续处理请求
}
}
func main() {
r := gin.Default()
apiGroup := r.Group("/api")
// 为/api路由组添加日志和身份验证中间件
apiGroup.Use(LoggerMiddleware(), AuthMiddleware())
// 注册一个路由
apiGroup.GET("/users", func(c *gin.Context) {
// 假设这是获取用户列表的处理函数
c.JSON(http.StatusOK, gin.H{"message": "获取用户列表"})
})
r.Run(":8080")
}
在解读之前先补充gin.Context
type Context struct {
writermem responseWriter
Request *http.Request
Writer ResponseWriter
Params Params
handlers HandlersChain
index int8
fullPath string
engine *Engine
params *Params
skippedNodes *[]skippedNode
// This mutex protects Keys map.
mu sync.RWMutex
// Keys is a key/value pair exclusively for the context of each request.
Keys map[string]any
// Errors is a list of errors attached to all the handlers/middlewares who used this context.
Errors errorMsgs
// Accepted defines a list of manually accepted formats for content negotiation.
Accepted []string
// queryCache caches the query result from c.Request.URL.Query().
queryCache url.Values
// formCache caches c.Request.PostForm, which contains the parsed form data from POST, PATCH,
// or PUT body parameters.
formCache url.Values
// SameSite allows a server to define a cookie attribute making it impossible for
// the browser to send this cookie along with cross-site requests.
sameSite http.SameSite
}
gin.Context 是 Gin 框架中一个非常核心的结构体,它在 Gin 处理 HTTP 请求的过程中被广泛使用。gin.Context 封装了 Go 原生的 http.Request 和 http.ResponseWriter,提供了丰富的方法和属性,方便开发者对请求和响应进行操作。通过 gin.Context,开发者可以访问请求的数据、设置响应的数据、管理中间件、执行特定的路由函数等。
字段解读:
HTTP 请求和响应
writermem: 内部使用的 responseWriter,用于缓存响应写入器的状态。
Request: 指向原始的 http.Request 对象,包含了 HTTP 请求的所有信息,如头部、URL、请求体等。
Writer: ResponseWriter 接口的实例,用于构造 HTTP 响应。它封装了底层的 http.ResponseWriter,提供了更多的功能,如状态码的设置、写入响应头和体。
路由和处理
Params: 路由参数集合,每个参数包含键和值。例如,对于路由 /user/:name,Params 会包含一个键为 “name” 的参数。
handlers: HandlersChain 类型,存储了当前路由匹配到的所有中间件和处理函数。
index: 当前执行到的中间件或处理函数在 handlers 中的索引。
fullPath: 匹配到的完整路由路径。
应用和路由上下文
engine: 指向 Engine 的指针,即当前 Context 所属的 Gin 应用实例。
params: 一个指向路由参数 Params 的指针,用于内部处理。
skippedNodes: 内部使用,用于优化路由匹配过程。
并发控制和请求数据
mu: sync.RWMutex,保护 Keys 字段的读写操作。
Keys: 为每个请求独有的键值对存储空间,可以在中间件和处理函数间共享数据。
Errors: 存储在处理请求过程中产生的错误信息列表。
内容协商和缓存
Accepted: 手动指定的用于内容协商的格式列表。
queryCache: 缓存了从 Request.URL.Query() 解析出的查询字符串参数。
formCache: 缓存了从 POST、PATCH 或 PUT 请求体解析出的表单数据。
Cookie 和安全
sameSite: http.SameSite 类型,用于设置 SameSite Cookie 属性,这有助于防止 CSRF 攻击。
gin.Context 的主要功能和用法包括:
请求数据处理:gin.Context 提供了多种方法来获取请求的参数,包括 URL 路径参数(:param 和 *param),查询字符串参数(Query),表单值(PostForm),以及 JSON、XML 等格式的请求体数据(BindJSON、BindXML 等)。
响应设置:开发者可以通过 gin.Context 设置 HTTP 响应的状态码、头部(Headers)、以及响应体。gin.Context 支持直接返回 JSON、XML、HTML 等格式的响应体,通过方法如 JSON、XML、HTML 等实现。
中间件管理:gin.Context 允许在处理函数中动态地添加或跳过后续的中间件执行,通过 Next、Abort 或 AbortWithStatus 等方法控制请求的处理流程。
错误处理:gin.Context 提供了 Error 方法,允许在请求处理过程中记录错误信息。这些错误信息可以在后续的中间件或请求处理函数中被检索和处理。
请求/响应上下文:gin.Context 在整个请求处理流程中被传递,作为请求上下文存在。它允许在中间件和处理函数之间共享数据,通过 Set、Get 方法存取上下文中的值。
HandlersChain例子解读:
在这个例子中,我们为 /api 路由组添加了两个中间件:LoggerMiddleware 和 AuthMiddleware。这意味着,对于 /api/users 的所有请求,首先会执行日志中间件记录请求开始,然后执行身份验证中间件检查用户是否已认证。如果用户未认证,请求将被终止,并返回 401 Unauthorized。如果用户已认证,请求最终会到达主处理函数,返回用户列表。
basePath string: 字符串类型,表示该 RouterGroup 的基础路径(Base Path)。所有在该组中注册的路由都会以这个路径为前缀。例如,如果 basePath 是 /api,那么在此组中注册的一个 /users 路径实际上会被解析为 /api/users。
*engine Engine: 指向 Engine 的指针,Engine 是 Gin 应用的核心结构体。这个字段表明了 RouterGroup 与一个 Engine 实例是关联的,通过这种方式,RouterGroup 可以访问 Engine 提供的功能和配置,如注册新的路由、添加中间件等。
root bool: 布尔类型,标识该 RouterGroup 是否是根路由组。在 Gin 中,根路由组是直接与 Engine 实例关联的路由组,而非根路由组则是通过调用根路由组的 Group 方法创建的子路由组。这个字段通常被内部使用,以区分根路由组和其他子路由组。
到这里就是engine第一个字段的解读
继续解读engine的字段
基本HTTP服务配置
RedirectTrailingSlash: 如果为 true,当路径匹配不成功但是去掉或添加尾部斜线后能匹配到时,会自动重定向到正确的路径。
RedirectFixedPath: 如果为 true,当请求的路径没有直接的处理函数时,Gin 会尝试修正路径(比如去掉多余的斜线、进行大小写不敏感的匹配)并重定向到修正后的路径。
HandleMethodNotAllowed: 如果为 true,当请求的方法(GET、POST等)不被允许时,会返回 405 Method Not Allowed 错误。
ForwardedByClientIP: 如果为 true,会尝试从请求头中解析出客户端的真实 IP 地址。
与请求路径和参数解析相关
UseRawPath: 如果为 true,Gin 会使用 url.RawPath 来查找参数。
UnescapePathValues: 如果为 true,路径中的参数值将被解码。
RemoveExtraSlash: 如果为 true,即使 URL 中包含额外的斜线也可以解析参数。
关于请求体的配置
MaxMultipartMemory: 设置解析 multipart/form-data 类型的请求体时允许的最大内存占用量。
高级配置
UseH2C: 如果为 true,启用 h2c 支持。
ContextWithFallback: 如果为 true,在某些情况下允许 Context 使用备用的方法来处理 Deadline、Done、Err 和 Value。
其他重要字段
RemoteIPHeaders: 定义了一组头部字段,用于在启用 ForwardedByClientIP 时解析客户端 IP 地址。
TrustedPlatform: 设置信任的平台,用于处理特定平台下的头部字段。
delims, secureJSONPrefix, HTMLRender, FuncMap: 分别用于模板渲染的定界符、安全 JSON 前缀、HTML 渲染器以及模板函数映射。
allNoRoute, allNoMethod, noRoute, noMethod: 分别用于处理未找到路由和不被允许的方法的处理函数链。
pool: 用于存储 Context 对象的池,优化内存使用。
trees: 存储所有路由的前缀树,用于快速匹配路由。
maxParams, maxSections: 分别用于限制路由参数和路径段的最大数量,提高路由匹配的效率。
trustedProxies, trustedCIDRs: 分别用于存储信任的代理服务器列表和 CIDR,用于解析客户端真实 IP 地址。
现在终于可以看刚开始的例子了:
方法体
defer func() { debugPrintError(err) }()
这行代码使用了 defer 关键字来确保在 Run 方法结束前执行 debugPrintError(err)。这是一个错误处理的模式,用于在方法退出时打印出现的任何错误。
if engine.isUnsafeTrustedProxies() {
...
}
这段代码检查是否信任了所有代理,如果是,将打印一个安全警告。这是因为过度信任代理可能导致安全问题,尤其是在解析客户端 IP 地址时.
address := resolveAddress(addr)
调用 resolveAddress 函数解析提供的地址参数 addr。如果 addr 为空,则函数返回默认的监听地址(例如 :8080)。
这个函数也可以做一个解读:
这个函数实际上是gin框架里面的函数,一开始我还以为是net/http里的。
这个函数只是一个辅助函数,用于处理启动服务器时提供的地址参数。如果没有提供参数,这个函数会返回一个默认值比如(:8080),这意味着服务器将监听网络接口上的8080端口。
func resolveAddress(addr []string) string {
switch len(addr) {
case 0:
if port := os.Getenv("PORT"); port != "" {
debugPrint("Environment variable PORT=\"%s\"", port)
return ":" + port
}
debugPrint("Environment variable PORT is undefined. Using port :8080 by default")
return ":8080"
case 1:
return addr[0]
default:
panic("too many parameters")
}
}
它的作用是根据提供的参数来解析服务器应当监听的地址。这个函数处理了几种不同的情况,以决定最终的监听地址。以下是对这个函数行为的逐条解读:
我这里一开始有一个疑问的,哪里来的切片,问题出现在这里:
Run(addr …string),看看里面的参数处理
addr …string 在 Go 语言中使用的是一种称为“变参函数”(Variadic Function)的特性,它允许你传递零个或多个 string 类型的参数给函数。这种参数在函数内部被处理为一个 string 类型的切片(slice)。
解释
… 符号:这个符号放在类型之前,表示该函数接受任意数量的该类型的参数。在这个例子中,addr …string 表示 Run 函数可以接受任意数量的 string 参数。
在函数内部
在 Run 函数的内部,addr 会被当作一个 []string 切片来处理。这意味着你可以对它执行所有切片操作,如 len(addr) 来获取传入参数的数量,或通过索引访问各个参数等。
直接举个例子:
不传递任何参数:Run(),这时 addr 作为一个空的 string 切片。
传递一个参数:Run(“:8080”),这时 addr 包含一个元素 “:8080”。
传递多个参数:Run(“:8080”, “:8081”),这时 addr 包含两个元素 “:8080” 和 “:8081”。
总的来说就是会把字符串转切片。它并不是像我之前理解的那样一个一个的加,而是针对的传递多个参数这种情况。
参数
addr []string: 一个字符串切片,包含了可能被用来指定监听地址的参数。
函数逻辑
1.没有提供参数 (len(addr) == 0):
首先,函数会检查环境变量 PORT 是否被设置。如果设置了,函数将使用这个环境变量的值作为端口号,并返回一个地址字符串,格式为 “:” + port,意味着监听所有网络接口上的这个端口。
如果环境变量 PORT 没有被设置,函数会通过打印一条调试信息来通知使用默认的 :8080 端口,并返回 “:8080” 作为监听地址。
提供了一个参数 (len(addr) == 1):
如果 addr 切片中只有一个元素,函数直接返回这个元素作为监听地址。这允许直接通过参数来指定完整的监听地址,例如 “127.0.0.1:8080” 或 “:8080”。
提供了多于一个参数 (len(addr) > 1):
如果 addr 切片中包含多于一个元素,函数将通过 panic 抛出一个错误,提示“too many parameters”。这是为了避免在启动服务器时出现参数上的混淆,确保启动行为的明确性。
debugPrint("Listening and serving HTTP on %s\n", address)
打印一条消息,告知正在监听的 HTTP 地址。
err = http.ListenAndServe(address, engine.Handler())
这个函数的内部实现:
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
使用标准库 net/http 的 ListenAndServe 函数来监听解析出的地址并启动 HTTP 服务器。engine.Handler() 返回一个处理 HTTP 请求的处理器,它将被用于处理所有到达监听地址的 HTTP 请求。
继续解读:
addr: 一个字符串,指定服务器监听的地址和端口。例如,“:8080” 表示监听本机的 8080 端口。
handler: 实现了 http.Handler 接口的对象。http.Handler 是一个接口,要求实现一个方法 ServeHTTP(ResponseWriter, *Request)。这个方法用于处理所有的 HTTP 请求。
*ServeHTTP(ResponseWriter, Request)
是 Go 语言 net/http 包中定义的 http.Handler 接口的唯一方法。任何想要处理 HTTP 请求的对象都需要实现这个接口。这个方法提供了处理 HTTP 请求并生成响应的基础设施。
w http.ResponseWriter: http.ResponseWriter 是一个接口,提供了向客户端发送响应的方法。通过这个接口,你可以写入响应体(Write 方法),设置响应状态码(WriteHeader 方法),以及添加或修改响应头部(Header 方法返回一个可以修改的 http.Header 对象)。
*r http.Request: *http.Request 是一个指向 http.Request 结构体的指针,它包含了这个 HTTP 请求的所有信息,比如 URL、头部、查询参数、表单数据、请求体等。通过这个参数,你可以读取和分析客户端发送的请求。
这个方法的工作流程:
当 HTTP 服务器接收到一个请求时,它会构造一个 http.Request 对象,并找到合适的处理器来处理这个请求。然后,它调用这个处理器的 ServeHTTP 方法,传入一个 http.ResponseWriter 和 *http.Request 作为参数:
读取请求: *使用 r http.Request 来获取请求的详细信息,比如请求的路径、方法、头部、请求体等。
处理请求: 根据请求的内容,执行相应的逻辑,可能会涉及读取数据库、执行计算、调用其他服务等操作。
发送响应: 使用 w http.ResponseWriter 向客户端发送响应。这包括设置响应状态码、响应头部以及写入响应体。
http.ListenAndServe内部实现:
内部首先会创建一个 http.Server 结构体实例,然后调用这个实例的 ListenAndServe 方法来启动服务器。
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
创建 http.Server 实例: 创建一个 http.Server 结构体实例,其中 Addr 字段设置为函数参数提供的地址,Handler 字段设置为处理请求的处理器。
调用 ListenAndServe: 接下来,调用这个 http.Server 实例的 ListenAndServe 方法。这个方法会让服务器开始监听指定的地址,当有 HTTP 请求到达时,使用提供的处理器来处理这些请求。
再次深挖这个函数
func (srv *Server) ListenAndServe() error {
if srv.shuttingDown() {
return ErrServerClosed
}
addr := srv.Addr
if addr == "" {
addr = ":http"
}
ln, err := net.Listen("tcp", addr)
if err != nil {
return err
}
return srv.Serve(ln)
}
这个函数用于启动一个 HTTP 服务器并监听指定的地址。
func (srv *Server) ListenAndServe() error {
关于函数:
*srv Server: *Server 表示这是 Server 结构体的一个方法,其中 srv 是对当前 Server 实例的引用。
返回类型是 error,如果服务器启动成功并运行,则正常情况下不会返回(因为它会一直运行直到被关闭)。如果启动过程中遇到错误,将返回相应的错误。
函数体
if srv.shuttingDown() {
return ErrServerClosed
}
这段代码检查服务器是否已经在关闭过程中。如果是,则返回 ErrServerClosed 错误。这是为了防止在服务器关闭后再次尝试启动它。
addr := srv.Addr
if addr == "" {
addr = ":http"
}
这里设置要监听的地址。如果 Server 实例的 Addr 字段为空,将默认使用 “:http”。“:http” 是一个特殊的地址,表示使用 HTTP 默认的端口号(80)监听所有网络接口。
ln, err := net.Listen("tcp", addr)
if err != nil {
return err
}
使用 net.Listen 函数尝试监听上面确定的地址。这个函数第一个参数是网络类型 “tcp”,第二个参数是地址。如果监听成功,net.Listen 返回一个 net.Listener 接口的实例 ln,用于接受来自客户端的连接。如果监听失败(例如,地址已被占用),将返回错误。
return srv.Serve(ln)
调用 Server 实例的 Serve 方法,并将之前创建的监听器 ln 作为参数。Serve 方法会启动一个循环,接受客户端的连接请求,并为每个请求启动一个 goroutine 来处理。这个方法通常会一直运行,直到服务器被关闭。如果 Serve 方法因为某些原因返回(通常是监听器遇到错误),那么 ListenAndServe 也会返回相应的错误。
func (srv *Server) Serve(l net.Listener) error {
if fn := testHookServerServe; fn != nil {
fn(srv, l) // call hook with unwrapped listener
}
origListener := l
l = &onceCloseListener{Listener: l}
defer l.Close()
if err := srv.setupHTTP2_Serve(); err != nil {
return err
}
if !srv.trackListener(&l, true) {
return ErrServerClosed
}
defer srv.trackListener(&l, false)
baseCtx := context.Background()
if srv.BaseContext != nil {
baseCtx = srv.BaseContext(origListener)
if baseCtx == nil {
panic("BaseContext returned a nil context")
}
}
var tempDelay time.Duration // how long to sleep on accept failure
ctx := context.WithValue(baseCtx, ServerContextKey, srv)
for {
rw, err := l.Accept()
if err != nil {
if srv.shuttingDown() {
return ErrServerClosed
}
if ne, ok := err.(net.Error); ok && ne.Temporary() {
if tempDelay == 0 {
tempDelay = 5 * time.Millisecond
} else {
tempDelay *= 2
}
if max := 1 * time.Second; tempDelay > max {
tempDelay = max
}
srv.logf("http: Accept error: %v; retrying in %v", err, tempDelay)
time.Sleep(tempDelay)
continue
}
return err
}
connCtx := ctx
if cc := srv.ConnContext; cc != nil {
connCtx = cc(connCtx, rw)
if connCtx == nil {
panic("ConnContext returned nil")
}
}
tempDelay = 0
c := srv.newConn(rw)
c.setState(c.rwc, StateNew, runHooks) // before Serve can return
go c.serve(connCtx)
}
}
我直接解读:
初始化部分:
if fn := testHookServerServe; fn != nil {
fn(srv, l) // call hook with unwrapped listener
}
这部分代码检查是否存在一个名为 testHookServerServe 的测试钩子(一个可能在测试中使用的全局变量)。如果这个钩子被设置了(不为 nil),则会使用当前的服务器实例 (srv) 和监听器 (l) 调用它。这主要用于内部测试,允许在实际处理连接之前拦截和修改服务器的行为。
origListener := l
l = &onceCloseListener{Listener: l}
defer l.Close()
这段代码首先保存原始监听器的引用,然后用一个 onceCloseListener 包装原始监听器,确保它只能被关闭一次。通过 defer 语句确保在 Serve 方法结束时关闭监听器,释放相关资源。
if err := srv.setupHTTP2_Serve(); err != nil {
return err
}
这里尝试为服务器设置 HTTP/2 支持。如果设置失败,例如因为环境不支持 HTTP/2,方法会返回错误
if !srv.trackListener(&l, true) {
return ErrServerClosed
}
defer srv.trackListener(&l, false)
这段代码在服务器的内部跟踪结构中注册当前的监听器。如果服务器已经关闭,trackListener 会返回 false,并且方法会返回 ErrServerClosed 错误。使用 defer 确保在方法退出时取消对监听器的跟踪。
上下文准备
baseCtx := context.Background()
if srv.BaseContext != nil {
baseCtx = srv.BaseContext(origListener)
if baseCtx == nil {
panic("BaseContext returned a nil context")
}
}
这段代码创建了一个基础上下文 baseCtx。如果服务器的 BaseContext 函数被设置了,它会被调用来生成一个针对当前监听器的自定义上下文。如果 BaseContext 返回 nil,则触发 panic,因为预期 BaseContext 应总是返回有效的上下文。
接受连接的循环
var tempDelay time.Duration // how long to sleep on accept failure
ctx := context.WithValue(baseCtx, ServerContextKey, srv)
for {
rw, err := l.Accept()
if err != nil {
...
continue
}
connCtx := ctx
if cc := srv.ConnContext; cc != nil {
connCtx = cc(connCtx, rw)
if connCtx == nil {
panic("ConnContext returned nil")
}
}
tempDelay = 0
c := srv.newConn(rw)
c.setState(c.rwc, StateNew, runHooks)
go c.serve(connCtx)
}
这是主要的循环,服务器在这里不断接受新的连接。每次尝试接受连接时可能遇到错误,比如因为网络问题导致的临时错误。如果发生了临时错误,服务器会等待一个延迟后再次尝试接受连接。这个延迟会在每次失败后增加,直到达到最大值。
如果接受连接成功,将创建一个新的连接上下文 connCtx,可能通过调用 ConnContext 函数进行定制。然后为每个接受的连接创建一个新的连接对象 (srv.newConn) 并调用其 serve 方法在新的 goroutine 中处理连接。
这个循环是无限的,直到服务器关闭或遇到非临时错误为止。。
返回值是 error 类型,如果服务器正常启动,则返回 nil。如果启动过程中出现错误,如端口被占用,将返回一个错误对象。
最后,方法返回。如果在监听过程中发生错误(例如,地址已被占用),err 将被赋值,并且通过之前 defer 的调用打印出来。
关于处理函数
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
这个Handler是接口,这个接口实现了一个唯一方法:
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
c := engine.pool.Get().(*Context)
c.writermem.reset(w)
c.Request = req
c.reset()
engine.handleHTTPRequest(c)
engine.pool.Put(c)
}
首先解释engine.pool,这个是sync.Pool类型的字段,用于高效的重用对象。以减少垃圾回收(GC)的压力。sync.Pool 是 Go 语言标准库中提供的一种用于存储和重用临时对象的机制,它可以显著减少内存分配和回收的开销,特别是在高并发环境下。
它主要提供两个方法:Get() 和 Put(obj interface{})。sync.Pool 的使用不需要关心内部如何存储对象,只需要知道这两个方法的用途:
Get() interface{}: 从 Pool 中获取一个对象。如果 Pool 中没有可用对象,则会调用 Pool 在初始化时指定的 New 函数来创建一个新对象。
Put(obj interface{}): 将一个对象放回 Pool 中,使其可以被后续的 Get() 调用重用。放入 Pool 的对象应该是可以安全重用的。
Gin 中的用途
在 Gin 框架中,engine.pool 通常用于重用 Context 对象。每个 HTTP 请求都会创建一个 Context 对象,该对象包含了处理该请求所需的所有信息和方法。由于 HTTP 请求非常频繁,不断地创建和销毁 Context 对象会给垃圾回收带来压力,影响性能。
通过使用 sync.Pool 来重用 Context 对象,Gin 可以显著减少内存分配的次数,提高性能。具体做法是:
当 Gin 处理一个新的 HTTP 请求时,会通过 engine.pool.Get() 获取一个 Context 对象。如果 pool 中没有可用的对象,则会创建一个新的 Context 对象。
请求处理完成后,Gin 会在发送响应之前调用 engine.pool.Put(context) 将这个 Context 对象放回 pool 中,使其可以被后续的请求重用。
这种模式是高性能 HTTP 服务器常用的优化技巧之一。
小提示,在gin框架中,上下文Context结构体就是爹。它封装了每个 HTTP 请求的所有相关信息(字段)和处理过程所需的方法。通过 Context 对象,你可以访问请求数据(如参数、头部、体)、控制响应(设置状态码、发送数据)以及调用中间件或路由处理函数。
Request: 指向 http.Request 的指针,包含了原始的 HTTP 请求信息,如 URL、头部、查询参数、表单数据等。
Writer: ResponseWriter 类型,用于构造和发送 HTTP 响应。它提供了设置响应状态码、写入响应头部和正文的方法。
Params: 路由参数的集合,允许你通过名称获取动态路由参数的值。
handlers: 处理当前请求的 HandlersChain,即一系列的处理函数。Gin 通过它来实现中间件和最终的路由处理函数。
index: 当前正在执行的处理函数在 handlers 中的索引,控制着处理函数链的执行过程。
Keys: 一个 map[string]interface{} 类型,用于在中间件和处理函数之间传递数据。
Errors: 存储在处理请求过程中发生的错误。
请求数据处理
Context 提供了多种方法来获取请求的数据:
Query: 获取 URL 的查询参数。
DefaultQuery: 获取查询参数,如果指定的参数不存在,则返回默认值。
PostForm: 获取表单数据。
Param: 获取动态路由参数。
BindJSON: 将请求体中的 JSON 数据绑定到一个 Go struct。
响应设置
通过 Context,你可以轻松地设置响应数据和状态:
JSON: 发送 JSON 格式的响应。
HTML: 发送 HTML 格式的响应。
Status: 设置响应的 HTTP 状态码。
Header: 设置响应头部。
中间件和路由处理
Next: 调用此方法会继续执行下一个处理函数。
Abort: 停止调用链中剩余的处理函数,通常用于中间件中条件不满足时提前终止请求处理。
现在看这个源码就是砍瓜切菜。
然后继续往下走,最重要的就是下面这个请求处理函数,用于处理每个HTTP请求:
engine.handleHTTPRequest©
追一下源码:
func (engine *Engine) handleHTTPRequest(c *Context) {
httpMethod := c.Request.Method
rPath := c.Request.URL.Path
unescape := false
if engine.UseRawPath && len(c.Request.URL.RawPath) > 0 {
rPath = c.Request.URL.RawPath
unescape = engine.UnescapePathValues
}
if engine.RemoveExtraSlash {
rPath = cleanPath(rPath)
}
// Find root of the tree for the given HTTP method
t := engine.trees
for i, tl := 0, len(t); i < tl; i++ {
if t[i].method != httpMethod {
continue
}
root := t[i].root
// Find route in tree
value := root.getValue(rPath, c.params, c.skippedNodes, unescape)
if value.params != nil {
c.Params = *value.params
}
if value.handlers != nil {
c.handlers = value.handlers
c.fullPath = value.fullPath
c.Next()
c.writermem.WriteHeaderNow()
return
}
if httpMethod != http.MethodConnect && rPath != "/" {
if value.tsr && engine.RedirectTrailingSlash {
redirectTrailingSlash(c)
return
}
if engine.RedirectFixedPath && redirectFixedPath(c, root, engine.RedirectFixedPath) {
return
}
}
break
}
if engine.HandleMethodNotAllowed {
for _, tree := range engine.trees {
if tree.method == httpMethod {
continue
}
if value := tree.root.getValue(rPath, nil, c.skippedNodes, unescape); value.handlers != nil {
c.handlers = engine.allNoMethod
serveError(c, http.StatusMethodNotAllowed, default405Body)
return
}
}
}
c.handlers = engine.allNoRoute
serveError(c, http.StatusNotFound, default404Body)
}
下面逐段解读:
请求路径和解码设置
httpMethod := c.Request.Method
rPath := c.Request.URL.Path
unescape := false
if engine.UseRawPath && len(c.Request.URL.RawPath) > 0 {
rPath = c.Request.URL.RawPath
unescape = engine.UnescapePathValues
}
if engine.RemoveExtraSlash {
rPath = cleanPath(rPath)
}
获取请求方法和路径:首先,代码获取了请求的 HTTP 方法和路径(.Method 和 .Path)。
选择使用 RawPath:如果 engine.UseRawPath 被设置为 true 且 RawPath 不为空,那么将使用 RawPath 作为请求路径,这可能是因为开发者希望处理特定的编码情况。
unescape:作用是指示在路由匹配和参数提取过程中是否需要对 URL 路径进行解码。尽管在提供的代码段中没有直接看到 unescape 的使用,但它在实际的路由匹配和参数处理逻辑中起到了关键作用,特别是在处理那些需要根据配置决定是否解码路径参数的场景中。
路径解码设置:如果选择使用 RawPath,根据 engine.UnescapePathValues 决定是否对路径参数进行解码。
移除多余的斜杠:如果 engine.RemoveExtraSlash 被设置为 true,那么将调用 cleanPath(rPath) 函数来移除路径中的多余斜杠。
如果看的不舒服,说明这些字段要学习一下:
c.Request.Method
c.Request 是一个 *http.Request 对象,它是 Go 标准库中定义的,表示一个 HTTP 请求。
.Method 字段包含了 HTTP 请求的方法(如 “GET”、“POST” 等)。
c.Request.URL.Path
c.Request.URL 是一个 *url.URL 对象,代表解析后的 URL。
.Path 字段包含了 URL 的路径部分,这是经过解码的路径,比如 /user/john。
c**.Request.URL.RawPath**
.RawPath 也是 *url.URL 对象的字段,它包含未经解码的原始路径。这在处理某些特殊字符时很有用,因为解码后的路径可能与原始路径不完全相同。
engine.UseRawPath
UseRawPath 是 Engine 结构体的一个字段,表示是否应该使用 RawPath 而不是 Path 来获取请求的路径。这个字段允许开发者根据需要选择使用原始路径还是解码后的路径。
engine.UnescapePathValues
UnescapePathValues 是 Engine 结构体的另一个字段,当设置为 true 时,表示在路由匹配和参数提取过程中,应该对路径中的百分号编码(URL 编码)的值进行解码。这对于需要在路径参数中使用特殊字符的情况很有用。
engine.RemoveExtraSlash
RemoveExtraSlash 是 Engine 结构体的字段,指示 Gin 在处理请求路径时是否应该移除多余的斜杠。例如,将 //user//john/ 处理为 /user/john。
路由匹配
//通过engine.trees拿到所有的路由树,这个切片装了所有的路由树。
t := engine.trees
//然后开始遍历所有的路由树
for i, tl := 0, len(t); i < tl; i++ {
//先匹配路由树的方法,因为路由树是按不同方法就是不同的路由树
if t[i].method != httpMethod {//不对的话就跳过,因为方法都对不上那就显然不是这颗树。就可以跳过了。
continue
}
//这里就是匹配成功了,然后把这颗路由树的根节点取出来。
root := t[i].root
//这个方法就是实现在当前路由树种查找与请求rpath匹配的路由。这个方法返回了一个结构体。包含与匹配路由相关的参数: (params)、处理函数 (handlers) 和完整路径 (fullPath)。
//关于这个函数的参数:
//第一个就是要进行查找的路由
//c.params 用于存放从路径中解析出的参数。
//c.skippedNodes 是用于内部路由匹配优化的。
//unescape 指示是否需要对路径参数进行解码。
value := root.getValue(rPath, c.params, c.skippedNodes, unescape)
if value.params != nil {
//如果找到路由包含的参数,则将这些参数赋值给当前请求的Context。
c.Params = *value.params
}
//如果找到匹配的路由并且存在对应的处理函数,则更新当前Context的处理函数链,设置当前请求的完整路径,然后再调用c.Next执行处理函数链。再调用c.writermem.WriteHeaderNow() 立即写入响应头部,然后返回以结束处理流程。
if value.handlers != nil {
c.handlers = value.handlers
c.fullPath = value.fullPath
c.Next()
c.writermem.WriteHeaderNow()
return
}
...
}
遍历所有的路由树 (engine.trees),查找与当前请求方法匹配的树。
使用请求路径 rPath 来在找到的路由树中查找匹配的路由节点。
如果找到匹配的路由,更新上下文 c 的参数、处理函数链 (handlers) 和完整路径 (fullPath),然后执行处理函数链,并立即写入响应头部。
看不懂就看这个:
engine.trees :
engine.trees 是一个存储了不同 HTTP 方法(如 GET、POST)对应的路由树的切片。每个路由树负责管理一个特定 HTTP 方法的所有路由规则。这种数据结构使得基于请求方法和路径的路由查找变得非常高效。
在 Gin 中,路由树是一种优化的数据结构,用于快速匹配 URL 路径到相应的处理函数。每个树节点可能代表 URL 路径的一部分,并且树中的路径可能包含参数(如 /user/:name 中的 :name)。
它的源码还有,为什么会是这样:
type methodTree struct {
method string
root *node
}
type methodTrees []methodTree
methodTree 和 methodTrees 是 Gin 框架用于构造和存储路由信息的数据结构。
methodTree
methodTree 结构体代表了一个特定 HTTP 方法(如 GET、POST)的路由树。这个结构体包含两个字段:
method: 字符串类型,表示 HTTP 方法。这告诉 Gin 这棵树包含的所有路由都是为哪种 HTTP 方法定义的,例如 “GET” 或 “POST”。
root: 指向 node 类型的指针。这个 node 是当前方法路由树的根节点。在这棵树中,每个节点可能代表路由路径的一部分,并且树中的路径可能包含参数(如 /user/:name 中的 :name)。
理解总结:由于不同的方法那就对应着不同的路由树,那么这个切片中每一个元素就是代表了一棵路由树,然后从内部结构体来看,里面两个字段,存了这棵路由树的方法名和路由树的根结点
这种结构使得基于请求方法和路径的高效路由匹配成为可能。每当一个新路由被添加到 Gin 应用中时,它会被插入到相应 HTTP 方法的 methodTree 的路由树中。
然后就是工作流程:
当 Gin 收到一个 HTTP 请求时,它首先检查请求的方法。然后,在 methodTrees 中查找与该方法相匹配的 methodTree。找到后,Gin 使用请求的路径在对应的 methodTree 的路由树中进行匹配,以找到最合适的处理函数。
如果请求的路径与路由树中的某个路由模式匹配,对应的处理函数就会被执行。如果没有找到匹配的路由,Gin 将返回 404 Not Found 错误响应(或者如果配置了处理 405 Method Not Allowed 的逻辑,也可能返回 405)。
里面的c.Next()我也要说说怎么实现的:
func (c *Context) Next() {
c.index++
for c.index < int8(len(c.handlers)) {
c.handlers[c.index](c)
c.index++
}
}
这个方法的主要作用是控制中间件和处理函数的执行流程。c.Next() 控制着当前请求的处理函数链 (c.handlers) 的执行。这个链就相当于是以恶个数组,然后数组里面存的是函数,在 Gin 中,每个请求都有一个与之关联的处理函数链,这个链表可能包含多个中间件和一个最终的路由处理函数。
递增 c.index:c.index 是一个 int8 类型的字段,表示当前正在执行的处理函数在 c.handlers 中的索引。在调用 Next() 方法时,首先将 c.index 增加 1,以便从下一个处理函数开始执行。
执行处理函数链:for 循环遍历 c.handlers,只要 c.index 的值小于 c.handlers 的长度,就执行当前索引对应的处理函数 c.handlersc.index。每执行完一个处理函数后,c.index 再次增加 1,移动到下一个处理函数。
执行流程控制
当在某个中间件或处理函数中调用 c.Next() 时,Gin 会继续执行当前请求的处理函数链中的下一个处理函数。
与此同时,还有两个函数非常的常用:
判断是否已经终止处理器调用。
func (c *Context) IsAborted() bool {
return c.index >= abortIndex
}
这个函数用来终止处理器调用。
func (c *Context) Abort() {
c.index = abortIndex
}
可以看到就是检查索引,终止操作时通过把索引直接改成上限。由于到了上限根据c.Next()的代码,到了上限就不会往后执行了。
还有一些相关的方法是终止处理器调用,并设置响应体。
func (c *Context) AbortWithStatus(code int) {
c.Status(code)
c.Writer.WriteHeaderNow()
c.Abort()
}
其实看了内部的终止操作,还是基于C.Abort()来实现终止,这些只不过附加了一些可能用到的功能。
重定向和固定路径
if httpMethod != http.MethodConnect && rPath != "/" {
if value.tsr && engine.RedirectTrailingSlash {
redirectTrailingSlash(c)
return
}
if engine.RedirectFixedPath && redirectFixedPath(c, root, engine.RedirectFixedPath) {
return
}
}
对于非 CONNECT 方法的请求,如果找到的路由节点建议进行尾部斜杠重定向 (value.tsr 为 true) 并且 engine.RedirectTrailingSlash 为 true,则执行重定向。
如果启用了固定路径重定向 (engine.RedirectFixedPath),且存在可以通过修正路径得到的匹配路由,则进行重定向。
处理 405 Method Not Allowed
if engine.HandleMethodNotAllowed {
for _, tree := range engine.trees {
if tree.method == httpMethod {
continue
}
if value := tree.root.getValue(rPath, nil, c.skippedNodes, unescape); value.handlers != nil {
c.handlers = engine.allNoMethod
serveError(c, http.StatusMethodNotAllowed, default405Body)
return
}
}
}
默认处理和 404 Not Found
c.handlers = engine.allNoRoute
serveError(c, http.StatusNotFound, default404Body)
如果没有匹配到任何路由,设置当前上下文的处理函数为全局的未找到路由的处理函数 (engine.allNoRoute),并返回 404 Not Found 错误。
总结,handleHTTPRequest 方法是 Gin 框架用于路由分发和请求处理的核心逻辑。它根据请求的路径和方法查找注册的路由,执行匹配的处理函数,或者根据配置执行重定向、返回 404 Not Found 或 405 Method Not Allowed 错误。
以上就是今天所看的源码,至少了解了这些内容,我个人感觉也没那么难受了。一开始看简直是眼花缭乱。