四(难题:95,173) . LeetCode标签刷题——树(二)(二叉搜索树 BST) 算法部分
95. 不同的二叉搜索树 II
给定一个整数
n,生成所有由1 ... n为节点所组成的 二叉搜索树 。
示例:
输入:3
输出:
[
[1,null,3,2],
[3,2,null,1],
[3,1,null,null,2],
[2,1,3],
[1,null,2,null,3]
]
解释:
以上的输出对应以下 5 种不同结构的二叉搜索树:
1 3 3 2 1
\ / / / \ \
3 2 1 1 3 2
/ / \ \
2 1 2 3
提示:
0 <= n <= 8
算法思路:
一般关于二叉树的问题都可以用递归来解决, 同时二叉搜索树又是一种根据递归定义的树,所以此题可由递归来求解。
对于一棵二叉搜索树来说,一个重要的性质就是它的中序遍历为升序,中序遍历的过程为左 -> 根 -> 右,如果给每个结点标记上编号,意思就是说所有左子树节点的编号一定小于根节点,所有右子树的结点编号大于根节点。在此题中给定了一个中序遍历顺序1 ~ n,
于是我们的思路如下:
- 先枚举根节点的位置,将问题划分为分别递归求解左边子树和右边子树
- 递归返回的是所有合法方案的集合,所以枚举每种合法的左右儿子
- 枚举左右儿子和根节点作为一种合法方案记录下来

算法分析
1、在给定的区间[l,r]中,枚举区间中的数i作为当前二叉搜索树的根结点,并在[l,i - 1]中构造出属于左子树的二叉搜索树的集合,在[i + 1,r]中构造出属于右子树的二叉搜索树的集合
2、左子树的集合中的任意二叉搜索树 和 右子树集合中的任意二叉搜索树 都能与 当前根结点i进行拼接形成新的二叉搜索树,枚举左子树的集合元素a以及右子树的集合元素b,用root.left = a和root.right = b进行二叉搜索树的拼接,记录在答案中

- 中序遍历的序列都是递增的,所以根节点左右两边的子树也都是二叉搜索树
- dfs的返回值设置为[l,r]序列中能组合出的二叉搜索树
- 先确定根节点的位置,然后分别对左右序列进行dfs搜索,获取左右子树的组合集合,并进行树的连接。
- 如果序列中没有元素,则添加一个null元素,作为递归基。
95,96的思路是一致的
**- 思路就是把l、r看成是二叉搜索树中序遍历的左右边界

-
然后枚举每个点为root,递归两边。返回的集合中都是合法的左子树或者右子树
-
然后root和集合中的左右子树分别拼接一下即可(注意,root一定要在循环内new,否则会覆盖)**
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<TreeNode*> generateTrees(int n) {
if(n==0) return {}; //如果n等于0,返回空即可。
//从1作为root开始,到n作为root结束
vector<TreeNode*> f = dfs(1,n); //n不为0,我们从1到n开始递归。//深搜所有情况
//注意这个题目没有申请数组vector来接收答案,而是直接将1到n作为参数传递,最后返回的就是答案,因为看dfs函数最后返回的就是节点数组
return f; //最后返回的答案就是答案数组
}
//返回在区间[l, r]中所有合法方案
vector<TreeNode*> dfs(int l,int r){ //编写递归函数(l,r是递归的左右边界)
//结点为空,是一种子树的方案,需要加入方案集中
// 递归终止条件,注意下面的递归过程中,有i-1和i+1的存在,就有可能触发此句执行。
if(l>r) return {NULL}; //如果l>r,则意味着当前区间里面一个点都没有,返回空(NULL)即可。(注意这里返回的表示{},而是{NULL},代表是叶节点。不能等于,因为等于就意味着是叶子节点。
vector<TreeNode*> res; //否则的话定义一下当前的子树。这样定义就相当于在dfs函数中传递的数组参数
//枚举根节点位置 // 乘法原理
for(int i=l;i<=r;i++){ //我们从l到r枚举根节点的位置
//返回左子树所有合法方案和返回右子树所有合法方案
//左子树是[l,i-1], 根节点root是i,右子树是[i+1,r],因为我们要构造树,所以我们要先递归求出左子树和右子树
auto left=dfs(l,i-1),right=dfs(i+1,r); //对左右子树进行递归建树。
for(auto l:left){ //从左边任取一颗子树
for(auto r:right){ //再从右边任取一颗子树。
//这里每次都要新new出一个根节点。因为每次添加的都是根节点,根节点不能相同
auto root=new TreeNode(i); //创建根节点,节点值就是i。//必须新建新头结点
root->left=l,root->right=r; //根节点的左孩子就是l,根节点的右孩子就是r。
//加入以该结点为根的合法方案
res.push_back(root); //将根节点加入到数组中。
}
}
}
return res; //最后记得返回答案数组。
}
};
-
这种要给出**
所有方案**(不是方案数、最大、最小之类的)的题大多是爆搜出来的。 -
在中序遍历里,二叉搜索树的某一棵子树一定对应排好序的数组里连续的一段。所以只需要对区间
[L,R]枚举每个点K作为根结点,那么左子树就对应区间[L,K−1],右子树就对应区间[K+1,R],从而变成递归问题。 -
那么当前以
K位置作为根结点,方案数就是左子树方案数乘以右子树方案数。要给出方案,那就是左子树取一个方案,右子树取一个方案,然后把它们拼起来。

算法代码方面yls已经讲解的非常清晰了,这里作为新手第一次接触类似的题型,我想分析一下这道题的思路。
首先:思路上总体是基于递归和分治的一个思想
1.为什么我们每次选择了根节点之后形成的树一定是二叉搜索树?
因为本身给的数的序列就是有序的
在递归树的每一层保证了左子树一定小于根节点,右子树一定大于根节点,那么我们就递推的得到了整棵树都是符合二叉搜索树定义的预期的。
其次用来存储答案的vector
**疑惑点:
**1.感觉输出数组样例不是完整的层遍历,例如 [1,null,2,null,3](3,3)后面应该还接了个NULL…真没看懂,大佬求解
答:对滴,leetcode的层序遍历会把最后连续的 null 忽略掉。
*2.TreeNode root = new TreeNode(i);//这一句我写在了第一个循环的下面时,出错了,请问一下大佬这是为啥,
答:这里要对每种不同组合建立一个新的根节点,否则这些根节点的地址是一样的,那么它们的左右儿子在内层循环时会被不断覆盖掉。
3.请问这个题目样例处的输出数组表示和树的对应关系应该怎么看?谢谢!
答:
输出数组是整棵树的层序遍历。
从树根开始往下,一层一层遍历。对于每层,从左往右遍历父节点非空的节点,如果当前节点不存在,则输出null,否则输出节点的值。
4.y总,请教一下,为什么每次递归的函数都要新开辟一个res,而全局开辟一个res传进去,会超时
答:
搜索出的每一棵二叉树的节点是不能共用的,因为每个内部节点的左右儿子是不同的。如果共用会导致二叉树的结构错乱。
2021年9月11日15:56:51:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//二叉搜索树中序遍历有序,所以如果n=3,则这棵二叉搜索树的中序遍历一定有序,这个题目很难,好好理解
class Solution {
public List<TreeNode> generateTrees(int n) {
if(n == 0) return new ArrayList<TreeNode>(); //n为0,返回新构建的空数组
return dfs(1,n); //我们从1到n开始递归,最后将递归完之后的答案返回(return), dfs函数有返回值,即是题目要求我们返回的List2021年10月14日16:28:49:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
//二叉搜索树就意味着中序遍历(LNR)是有序的,并且二叉搜索树是递归定义的,这也就意味着每一棵子树在中序遍历里面都是连续的一部分,因为我们在遍历完一棵子树之后才会遍历另一棵子树
//所以每一棵子树都是连续的一段,即这个题目中的子树必然是连续的一段,我们假设当前子树是从l到r的话,我们枚举[l,r]区间这棵子树的根节点,我们枚举根节点是中间的某一个点k,
//当[l,r]区间子树的根节点k确定之后,其左子树一定是[l,k-1],右子树必然是[k+1,r](我们最开始从[1,n]开始递归),
//之后接着往[l,k-1]递归,看左边可以形成多少不同的二叉搜索树,往右边[k+1,r]递归,看右边可以形成多少不同的二叉搜索树,
//我们此时任取左边一棵树,任取右边一棵树,加上根节点k都是一棵不同的二叉搜索树,即是乘法原理的关系,
public List<TreeNode> generateTrees(int n) {
return dfs(1,n); //最开始的时候从[1,n]开始递归,并且dfs的返回值就是不同的二叉搜索树的集合数组
}
public List<TreeNode> dfs(int l,int r){
List<TreeNode> res=new ArrayList<>(); //先定义当前的子树集合
if(l>r) { //递归结束条件,即如果区间左端点大于右端点的值,就意味着区间中是没有结点了
res.add(null); //没有结点说明当前节点是空节点,我们就往res中添加一个null,注意是添加null,不是返回null
return res; //这里的return res,可以写可以不写,如果写肯定是对的,如果不写满足了if条件下面的循环是不会执行的,最后也会执行最下面的return res语句,
}
for(int k=l;k<=r;k++){ //枚举根节点的位置
//下面完成中序遍历,即左->根->右的顺序
List<TreeNode> lef=dfs(l,k-1); //因为是中序遍历,所以我们要先递归建立好左子树,并且左子树的区间是[l,k-1]
//因为左右两边递归的时候是互不影响的,所以我们这里也一并递归右边的区间,建立好右子树,而且我们建立根节点的时候左右子树都需要用到
List<TreeNode> rig=dfs(k+1,r); //递归建立好右子树,因为左右区间是互不影响的,所以我们这里可以先递归建立好右子树
//左右子树都递归建造好之后,我们就可以开始建立二叉树了,这几步操作类似于归并排序的递归写法,我们先往左右区间递归,递归之后再合并
//我们的根节点就是k,而从左子树集合中任取一棵左子树,从右子树集合中任取一棵右子树,都可以作为根节点的左右子树,即是乘法原理的关系
for(TreeNode x:lef){ //从左子树集合中任取一棵作为左子树
for(TreeNode y:rig){ //从右子树集合中任取一棵作为右子树
TreeNode root=new TreeNode(k); //注意这里每次任取一棵左子树和任取一棵右子树都要重新创建根节点(权值是k),
//否则节点是引用,如果我们就定义一个的话,前面的会被后面的引用所改变.所以这里一定每次任取一棵左右子树之后都要重新建立根节点
root.left=x; //根节点的左右子树分别是x,y
root.right=y;
res.add(root); //每创建好一棵子树之后,都要将根节点加到res中
}
}
}
return res; //最后将res返回
}
}
2021年10月26日12:22:55:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//注意u是根节点了,左子树就是[l,u-1],注意右边界不是u啊,右子树是[u+1,r],一定要注意左子树不是[l,u],而是[l,u-1],
//注意这个题目不是二分求的根节点,而是枚举的[l,r]区间中的每一个点作为根节点,如果使用的二分求根节点的话,则根节点就只有几个了
//首先题目让我们构建的一棵二叉搜索树,而二叉搜索树的中序遍历是有序的,因为要求出所有的具体的方案,即不是方案数量,所以我们考虑使用dfs爆搜解决
//二叉搜索树是递归定义的,其中序遍历是有序的,所以其每一棵子树都是连续的一部分,因为我们在遍历一棵树的时候是一棵子树一棵子树来遍历的
//这个题目关键的一点:每一棵子树都是连续的一段,假设当前这棵子树对应的值的区间是[l,r]的话,现在我们就需要枚举一下这棵子树的根节点是谁了,
//根节点可能是[l,r]区间的任意一个数,所以我们需要枚举[l,r]区间中的每一个数作为根节点,一定要注意这里我们是枚举的[l,r]区间中的每一个节点作为根节点的,不是二分求的啊
//比如我们选取的根节点是[l,r]区间中的k,则根节点的左子树就是[l,k-1],注意k是根节点了,则左子树就是[l,k-1],不是[l,k]啊,右子树区间就是[k+1,r]
//接下来我们需要构造这棵子树,我们需要先递归求出来这个子树的左右子树,才可以构造这棵子树,所以我们先递归得到根节点k的左右子树,再构造这棵子树
//即我们先递归分别得到左右子树可以形成多少种不同的二叉搜索树,最后左子树,右子树,根节点之间可以形成的不同的二叉搜索树是乘法原理的关系
//即是说我们任取左边一种形态,任取右边一种形态,再拼接上根节点,都可以作为一种[l,r]区间的子树的结果,即如果左边有x种方案,右边有y方案,则当前子树的方案总数是x*y种
//即这个题目本质上就是一个爆搜dfs,爆搜搜索的时候每一层我们枚举一下根节点的位置,根节点的位置确定之后,我们先递归搜索一下左右两边有多少种不同的子树,
//之后我们再任意从左右两边各取一个左右子树,和根节点一拼就可以得到当前子树,这个题目的方案数是卡特兰数,即这个题目的时间复杂度是指数级别的,
class Solution {
public List<TreeNode> generateTrees(int n) {
return dfs(1,n); //最一开始的时候,我们需要构造的二次搜索树的左右区间分别是1,n, dfs函数的返回值就是[l,r]值区间形成的不同的二叉搜索树的集合
}
public List<TreeNode> dfs(int l,int r){ //l,r是当前递归层的左右边界
List<TreeNode> res=new ArrayList<>(); //先定义出本层递归的结果集合数组,即当前子树的集合答案数组
if(l>r) { //l>r就意味着当前区间中一个点都没有,一个点都没有就意味着当前这棵子树是空的,即是空节点,我们就往res中添加一个空节点
res.add(null);
return res; //最后要记得返回res,因为我们已经递归到了空节点了
}
//否则我们就需要枚举[l,r]区间的每一个数作为根节点,注意这里我们是枚举的[l,r]区间中的每一个数作为根节点的,不是二分求出来的啊
// int mid=(l+r)/2;
// List lef=dfs(l,mid-1),rig=dfs(mid+1,r);
//注意根节点不是二分求出来的,而是使用for循环从l枚举到r枚举出来的
for(int k=l;k<=r;k++){ //使用for循环枚举一下根节点的位置,从l枚举到r,即k此时就是根节点的位置,一定要for循环枚举根节点的位置
//先递归求出来左右子树,因为我们在构造二叉树的时候,需要知道根节点的左右子树
List<TreeNode> lefts=dfs(l,k-1),rights=dfs(k+1,r); //先递归求出左右子树的集合,左子树的区间是[l,k-1],右子树的区间是[k+1,r]
//然后我们再从两个集合中任取一棵子树分别作为左右子树,再和根节点组合起来就是一棵当前的子树
for(TreeNode le:lefts){ //从左右子树的集合中分别任取一棵作为根节点的左右子树
for(TreeNode ri:rights){
TreeNode root=new TreeNode(k); //注意每次分别选取完左右子树之后,每次的根节点都需要新建,
//否则如果我们都共用的一个根节点的话,之前的子树会被后面的子树所改变(因为是引用),并且根节点的值就是k
root.left=le; //根节点的左右子树分别是le,ri
root.right=ri;
//构造完左右子树之后,我们将根节点加到res中
res.add(root);
}
}
}
return res; //当前层的子树全部构造完之后就全部加到res中了,我们要记得返回res
}
}
96. 不同的二叉搜索树
给定一个整数
n,求以1 ... n为节点组成的二叉搜索树有多少种?
示例:
输入: 3
输出: 5
解释:
给定 n = 3, 一共有 5 种不同结构的二叉搜索树:
1 3 3 2 1
\ / / / \ \
3 2 1 1 3 2
/ / \ \
2 1 2 3
算法分析:
核心思想:当给定的长度固定时,对应的二叉搜索树的情况数量也一定相同
- f[i]的含义是
i个数所能组成不同的二叉擦搜索树的方案数 - 乘法原理,每个根节点所能包含的组合总数为左右序列的方案数相乘
- 外层遍历一共有
i个数,内层遍历一遍根节点的位置,把方案数相加即可。

时间复杂度 O(n2)
(DP) O(n2)
定义状态:f[i]:表示长度为i的节点可构造出多少种bst
状态转移方程:f(n)=sum(f(i−1)∗f(n−i))i:[1,n] ,也就是分别以不同的节点为根构造出bst,方法数由乘法原理和加法原理即可得到
初始条件:f[0]=1

算法
(动态规划) O(n2)
对于n个节点的BST,除去根节点有n−1个节点,将这n−1个节点分配在根节点的两侧,即可构造出所有的方案。
递推公式即为: f[n]=f[0]∗f[n−1]+f[1]∗f[n−2]+…+f[n−1]∗f[0]
时间复杂度
O(n)个状态,每次状态计算需要O(n)时间,故O(n2)

f[i]的含义是i个数所能组成不同的二叉擦搜索树的方案数- 乘法原理,每个根节点所能包含的组合总数为左右序列的方案数
相乘- 外层遍历一共有
i个数,内层遍历一遍根节点的位置,把方案数相加即可。
初始条件:f[0]=1

DP
[1, 2, 3, …, n]中,枚举每个点为根节点
那么当枚举到
j的时候,不同的左子树的个数为f[j - 1],不同的右子树的个数为f[n - j]之所以有这个结论,是因为,此时的f是与树内容无关的,只与节点个数有关。
因为数列是递增的,即任意截取相同的一段,所构成的二叉搜索树都是一样的,只不过内容不同罢了
再根据上一题的思路发现,左右子树的集合是需要做内积的,所以
f[i] += f[j - 1] * f[n - j]
用卡特兰数可以直接做,如果还是用递归,可以优化一下,可以发现所有长度一样的区间[L,R]的方案数(BST的形态的数目)是一样多的,和里面具体是什么数字没有关系。
所以可以用f[i]表示长度为i时候的方案数,求的时候只要枚举一下根结点j从1到i,然后两边方案数乘起来加过来就行了。
因为空的子树也是一种形态,f[0]取1,如果f[0]取了0,那么和另一侧子树的方案数相乘就还是0,这样就不能算正确了。递推的边界只要保证计算正确就行了。
代码:
//当一个有序序列[l, r], 在这个序列中找到一个点 k, k >= l && k <= r, 作为根节点
//那么以k为根节点的二叉搜索树的左子树[l, k-1], 右子树为[k+1, r];
//在左子树中[l, k-1]任取一个做左子树, 在右子树中取一个做右子树[k+1, r]===》一颗二叉搜索树
//f[k] 表示 k 为根节点的二叉搜索树的数量: f[k] = f[(k-1)-l+1] * f[r-(k+1)+1]
// =======> f[k] = f[k-l] * f[r-k];
class Solution {
public:
int numTrees(int n) {
vector<int> f(n+1); //f数组存放每种方案
f[0]=1; //注意f[0]初始化为1,否则下面的乘法结果将恒为零
//第一重循环是代表总共会有多少个节点
//第二重循环枚举根节点的位置(j),dp[j-1]代表左节点有多少种情况,dp[i-j]代表右节点有多少种情况
//外层枚举n
for(int i=1;i<=n;i++){ //根节点可以从1到n,
//内层枚举根节点
for(int j=1;j<=i;j++){ //j就是具体的根节点位置
//左边是1~j-1(是j-1个数),右边是j+1~i(个数是i-j个)
f[i]+=f[j-1]*f[i-j]; //不同根节点方案数累加,其中左侧j-1个数,右侧i-j个数
}
}
return f[n]; //返回答案。
}
};
java代码(用卡特兰数计算):
或者直接公式算
直接算的话可能会越界,所以用Long存。但是结果保证不会越界,所以可以直接cast
/*
卡特兰数的递推公式
a0 = 1
an+1 = an * 2(2n + 1) / (n + 2)
卡特兰数的通项公式
C(2n, n) / (n + 1)
*/
public int numTrees2(int n) {
long res = 1;
for (long i = 0; i < n; i++) {
res = res * 2 * (2 * i + 1) / (i + 2);
}
return (int) res;
}
2021年10月14日17:03:51:
class Solution {
//这个题目是让我们求二叉搜索树的个数,我们可以直接返回上一个题目的res.size()即可,当然也可以简化写:
//线性dp,对于任意两个区间,只要长度相同的话,则区间中所能形成的二叉搜索树的数目是相同的,即1~10所形成的二叉搜索树的数目和2~11区间所形成的二叉搜索树的数目是相同的
//我们使用乘法原理,在区间[l,r]内枚举根节点k,当根节点是k的前提下,所能形成的不同的二叉搜索树的数目=f[k-1-l+1]*f[r-(k+1)+1],左区间[l,k-1],右区间[k+1,r]
//即我们用f[i]表示[1,i]的区间所可以形成的不同的二叉搜索树的数目,然后枚举根节点,最后就是所有不同的根节点所能组成的二叉搜索树的累加
//最后的答案即是f[n],即[1,n]的区间所可以形成的不同的二叉搜索树的数目,
public int numTrees(int n) {
int[] f=new int[n+10]; //f[i]表示1到i区间所能形成的不同二叉搜索树的数目
f[0]=1; //状态初始化,即空子树是一种形态,注意这个诸天重生很重要,如果没有这个状态初始化后面的状态的更新都将会是错误的
for(int i=1;i<=n;i++){ //从1开始递推f[i],一直递推到n,并且最左边就是1,最右边是i
for(int k=1;k<=i;k++){ 枚举根节点k,注意在这里的区间是[1,i],不是[l,r],所以根节点是从1枚举到i,
f[i]+=f[k-1-1+1]*f[i-(k+1)+1]; //左区间是[1,k-1],右区间是[k+1,i],注意枚举根节点k之后,f[i]要累加
}
}
return f[n]; //最后的答案即是f[n]
}
}
2021年10月26日12:23:25:
class Solution {
//95题使用dfs,96题是dp
//核心就是子树的值的区间是连续的一部分
//这个题目是让我们求所有的种树,而不是具体的方案数了,所以我们考虑使用dp优化,按照上一题的思路,我们在构造[l,r]区间的子树的时候,
//当枚举[l,r]区间中的值k作为根节点之后,其左子树的区间集合就是[l,k-1],右子树是[k+1,r],并且递归完左右子树之后,
//从左右两边各取一个子树都可以构造出一棵二叉搜索树出来,即满足乘法原理的关系,并且一个区间长度固定之后其所能形成的不同的二叉搜索树的数量是确定的,
//即是[1,10]区间所能形成的二叉搜索树的数量和区间[2,11]所能形成的二叉搜索树的数量是相同的,即长度相同的话,方案数就是相同的,我们可以一一映射过去
//即1对应2,2对应3,...,10对应11,对应2~11这个区间的任意一个方案我们都可以使用1~10区间的数映射过去,即一个区间的二叉搜索树的数目取决于区间的长度
//所以当[l,r]区间确定之后,我们任取的根节点为k的话,其形成的二叉搜索树的数目就等于f[(k-1)-l+1]*f[r-(k+1)+1],f[i]表示区间[1,i]即区间长度为i所形成的不同的二叉搜索树的数目
//上面的f[(k-1)-l+1]*f[r-(k+1)+1]就是当根节点取k之后的构成的二叉搜索树的数目,
//所以现在如果我们想求1~i区间的二叉搜索树的数目的话,我们先枚举根节点的位置k,当根节点的位置k确定之后,f[i]就是全部的f[(k-1)-1+1]*f[r-(k+1)+1]的累加,并且k的取值是从1到i
//所以我们需要使用dp递推求出来所有的i,i从1递推到n,最后的答案就是f[n],
//我们现在希望快速求出来的是左右两边
public int numTrees(int n) {
int[] f=new int[n+10]; //f[i]表示区间[1~i]中的二叉搜索树的数目
//状态初始化:f[0]=1,即表示空子树是一种方案,这个状态初始化很重要,不能不写,凭借直觉,因为是乘法,所以一般也要初始化为1
f[0]=1; //这个状态初始化很重要
//下面就要递归更新所有的f[i]了,i的取值是从1到n
for(int i=1;i<=n;i++){ //从1到n递推更新所有的f[i]
枚举根节点k,注意在这里的区间是[1,i],不是[l,r],所以根节点是从1枚举到i,
for(int k=1;k<=i;k++){ //枚举区间[1,i]中的所有的点作为根节点,使用f[i]+=f[(k-1)-l+1]*f[r-(k+1)+1]更新f[i],注意是f[i]+=,因为是枚举所有的点作为根节点的方案数之和
f[i]+=f[k-1-l+1]*f[r-(k+1)+1];
}
}
return f[n]; //最后的答案就是f[n]
}
}
95. 不同的二叉搜索树 II
给定一个整数
n,生成所有由1 ... n为节点所组成的 二叉搜索树 。
示例:
输入:3
输出:
[
[1,null,3,2],
[3,2,null,1],
[3,1,null,null,2],
[2,1,3],
[1,null,2,null,3]
]
解释:
以上的输出对应以下 5 种不同结构的二叉搜索树:
1 3 3 2 1
\ / / / \ \
3 2 1 1 3 2
/ / \ \
2 1 2 3
提示:
0 <= n <= 8
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<TreeNode*> generateTrees(int n) {
if(n==0) return {}; //如果n等于0,返回空即可。
return dfs(1,n); //n不为0,我们从1到n开始递归。
}
vector<TreeNode*> dfs(int l,int r){ //编写递归函数(l,r是递归的左右边界)
if(l>r) return {NULL}; //如果l>r,则意味着当前区间里面一个点都没有,返回空即可。
vector<TreeNode*> res; //否则的话定义一下当前的子树。
for(int i=l;i<=r;i++){ //我们从l到r枚举根节点的位置
auto left=dfs(l,i-1),right=dfs(i+1,r); //对左右子树进行递归建树。
for(auto l:left){ //从左边任取一颗子树
for(auto r:right){ //再从右边任取一颗子树。
auto root=new TreeNode(i); //创建根节点,节点值就是i。
root->left=l,root->right=r; //根节点的左孩子就是l,根节点的右孩子就是r。
res.push_back(root); //将根节点加入到数组中。
}
}
}
return res; //最后记得返回答案数组。
}
};
2021年8月27日11:51:04:


/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//二叉搜索树中序遍历有序,所以如果n=3,则这棵二叉搜索树的中序遍历一定有序,这个题目很难,好好理解
class Solution {
public List<TreeNode> generateTrees(int n) {
if(n == 0) return new ArrayList<TreeNode>(); //n为0,返回新构建的空数组
return dfs(1,n); //我们从1到n开始递归,最后将递归完之后的答案返回(即加上return), dfs函数有返回值,即是题目要求我们返回的List
96. 不同的二叉搜索树
给定一个整数
n,求以1 ... n为节点组成的二叉搜索树有多少种?
示例:
输入: 3
输出: 5
解释:
给定 n = 3, 一共有 5 种不同结构的二叉搜索树:
1 3 3 2 1
\ / / / \ \
3 2 1 1 3 2
/ / \ \
2 1 2 3

核心思想:当给定的长度固定时,对应的二叉搜索树的情况数量也一定

时间复杂度O(n^2);
代码:
树+动态规划
class Solution {
public:
int numTrees(int n) {
vector<int> f(n+2); //定义答案数组。
f[0]=1; //空子树答案是1。边界情况
for(int i=1;i<=n;i++){ //枚举根节点的情况
for(int j=1;j<=i;j++){ //
f[i]+=(f[j-1]*f[i-j]); //把根节点在从1到i的所有方案数相加。
}
}
return f[n]; //最后将答案返回;
}
};
2021年8月27日15:07:37:

//这个题目只需要我们输出可以建立的二叉搜索树的种类数,这个答案是卡特兰数,这个题目是没有构造树的,所以我们不能使用上面题目的方法,最后返回一个res.size(),
//我们知道对于根节点k来说,其可以构成的不同二叉搜索树的个数是左子树集合的个数x*右子树集合的个数y, 我们用数组f[k]来表示在[l,r]区间内以节点k作为根节点构成的树的个数
//我们如何保证dfs是有序的?我们每次dfs的时候都是将[l,k-1]放到左子树,将[k+1,r]放到右子树
//则f[k]=f[k-1-l+1]*f[r-(k+1)+1],f[k-1-l+1]即是左子树区间[l,k-1]构成的当前节点的左子树的集合的个数,f[r-(k+1)+1]是右子树的个数
//所以当我们想求从1到i这一段的二叉搜索树的数量的时候,我们枚举一下根节点j,根节点j确定了之后,则f[j]=f[(j-1)-1+1]*f[i-(j+1)+1]=f[j-1]*f[i-j]
//我们使用动态规划即可求这个题目,初始化是f[0]=1, 如果初始化为0的话,则之后再乘的时候(更新f数组的时候)将永远都是0,并且这样初始化也可以保证当j取到1的时候,
//即左子树是空,只有右子树,这样也是二叉搜索树,是满足题意的,此时f[j]=f[j-1]*f[i-j]=1*f[i-1],如果初始化为0的话,就意味着这种情况是不存在的,明显是不对的。
class Solution {
public int numTrees(int n) {
int[] f=new int[n+1]; //注意状态数组长度应该是n+1,而不能是n,因为我们要定义f[0],最后的答案是f[n],所以数组的总长度是n+1
//f[i]表示以i为根节点可以构造的二叉搜索树的形态个数
f[0]=1; //dp数组的初始化条件,即表示当长度为0的时候,即左子树或者右子树为空也是一种情况
for(int i=1;i<=n;i++){ //枚举[1,n]的每一个数,这里枚举i从1到n是为了更新f数组,注意这里不能直接单单只枚举for(int i=1;i<=n;i++) f[n]=f[i-1]*f[n-i]
//上面这样写是不对的,因为我们那样在计算的时候,需要用到f[1],f[2],f[3]...的值,而这些值我们现在都不知道,所以我们应该像y总这样,写两层for循环,
//依次先后计算出来f[1],f[2],f[3]...最后我们就可以根据前面已经得到的f[1],f[2],f[3]...的值,计算出来f[n]的值
for(int j=1;j<=i;j++){ //这里枚举j才是以1到i的区间的不同的二叉搜索树的个数
f[i]+=f[j-1]*f[i-j]; //累积更新以不同的j为根节点的构造出来的二叉搜索树的数量,注意要累加f[i],
}
}
return f[n]; //最后的f[n]就是以从1到n所构成的二叉搜索树的种数
}
}
或者直接公式算我们用的是卡特兰数的递推公式,不是通项公式。
直接算的话可能会越界,所以用Long存。但是结果保证不会越界,所以可以直接cast
/*
卡特兰数的递推公式
a0 = 1
an+1 = an * 2(2n + 1) / (n + 2)
卡特兰数的通项公式
C(2n, n) / (n + 1)
*/
public int numTrees2(int n) {
long res = 1;
for (long i = 0; i < n; i++) {
res = res * 2 * (2 * i + 1) / (i + 2);
}
return (int) res;
}
98. 验证二叉搜索树
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
输入:
2
/ \
1 3
输出: true
示例 2:
输入:
5
/ \
1 4
/ \
3 6
输出: false
解释: 输入为: [5,1,4,null,null,3,6]。
根节点的值为 5 ,但是其右子节点值为 4 。
可以判断这棵树的中序遍历序列是否有序,如果有序就一定是一颗二叉搜索树。
也可以递归的判断当前节点的值都是大于左子树的值,都是小于右子树的值,记录左子树的最大值a,记录右子树的最小值b,如果a
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
bool isValidBST(TreeNode* root) {
return dfs(root,INT_MIN,INT_MAX); //从根节点开始递归判断
}
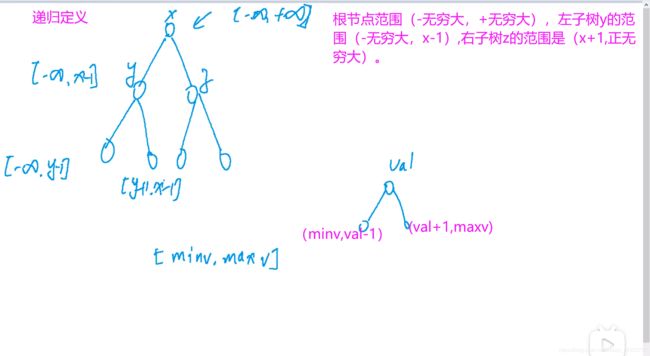
bool dfs(TreeNode* root,long long minv,long long maxv){ //定义递归函数,注意minv和maxv是当前节点的应该在的左右边界
if(!root) return true; //如果当前节点是空的,则说明之前递归的都在范围内。
if(root->val<minv||root->val>maxv) return false; //如果说当前节点值出了边界,则说明不合法。
return dfs(root->left,minv,root->val-1ll)&&dfs(root->right,root->val+1ll,maxv); //当前节点值没有出边界,我们再对左右子树进行递归,看其是否在范围内,如果都在范围内,则说明递归到这里仍是合法的二叉搜索树。
//注意这里如果是最小值减一或者最大值加一则会出边界,所以我们要强制转化为long long
}
};
2021年8月10日20:04:39:
上面的解法是y总的解法,这里是用的二叉搜索树中序遍历有序的性质做的。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//可以直接判断一下二叉树的中序遍历是否有序,也可以使用二叉搜索树的定义来判断:即节点的左子树值都小于当前节点,右子树值都大于当前节点
//这个题目我们递归判断,以root为根的子树,判断子树中所有节点的值是否都在(l,r)的范围内(注意是开区间),如果root节点的值val不在(l,r)的范围内,说明不满足条件直接返回
//否则我们就要继续递归调用检查它的左右子树是否满足,如果都满足才说明这是一棵二叉搜索树,注意要用long记录区间范围 ,时间:O(n)
class Solution {
public boolean isValidBST(TreeNode root) {
return dfs(root,Long.MIN_VALUE,Long.MAX_VALUE); //从根节点开始递归遍历,初始是l,r分别是long型的最小值,最大值
}
public boolean dfs(TreeNode root,long l,long r){
if(root==null) return true; //遍历到了空节点,说明都满足题意,返回true
if(root.val<=l||root.val>=r) return false; //如果根节点值<=l或者是根节点值>=r,说明不满足二叉搜索树的定义,直接返回false,直接结束递归
//否则继续分别往左右子树分别递归,必须左右子树都满足才返回true
return dfs(root.left,l,root.val)&&dfs(root.right,root.val,r); //注意这样写,往左子树递归,右边界变成了root.val,往右子树递归,左边界变成了root.val
}
}
2021年11月11日16:46:12:
//这里我们是在dfs的函数中传递了两个参数,分别是左右边界的值(即节点的值必须要大于左边界,必须要小于右边界,否则有一个不满足都是错误的)
//如果上面两点都满足之后,再递归判断其左右儿子是否满足,而且我们在往下递归的时候要注意更改左右边界,比如说当往左子树低估的时候,左子树的右边界应该是根节点的值
//同理往右子树递归的时候,其左边界应该是根节点的值,这里其实和y总讲的在dfs的过程中传递三个参数:最大最小值和是否满足定义其实是一样的道理
class Solution {
public boolean isValidBST(TreeNode root) {
if(root==null) return true;
return dfs(root,Long.MIN_VALUE,Long.MAX_VALUE); //从根节点开始递归,递归的左右边界一开始是long型的最小最大值(因为节点值可能是int的最大最小值)
}
public boolean dfs(TreeNode root,long l,long r){
if(root==null) return true; //节点为空,表示从上到下到达这里的时候是没有问题的,我们返回true
if(root.val<=l||root.val>=r) return false; //当根节点的值<=l或者根节点的值>=r的时候,说明非法,我们就返回false
return dfs(root.left,l,root.val)&&dfs(root.right,root.val,r); //否则说明当前节点是合法的,我们就继续往下递归其左右子树,
//这里要注意当往左子树递归的时候,右边界就变成了root.val;而往右子树递归的时候,左边界就变成了root.val
}
}
99. 恢复二叉搜索树
给你二叉搜索树的根节点
root,该树中的两个节点被错误地交换。请在不改变其结构的情况下,恢复这棵树。
进阶:使用 O(n) 空间复杂度的解法很容易实现。你能想出一个只使用常数空间的解决方案吗?
示例 1:
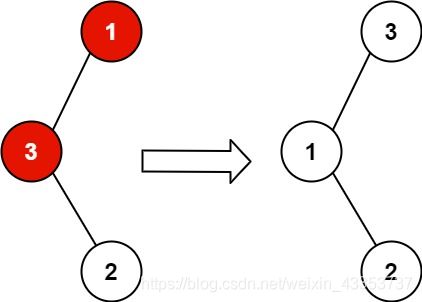
输入:root = [1,3,null,null,2]
输出:[3,1,null,null,2]
解释:3 不能是 1 左孩子,因为 3 > 1 。交换 1 和 3 使二叉搜索树有效。
示例 2:

输入:root = [3,1,4,null,null,2]
输出:[2,1,4,null,null,3]
解释:2 不能在 3 的右子树中,因为 2 < 3 。交换 2 和 3 使二叉搜索树有效。
提示:
树上节点的数目在范围 [2, 1000] 内
-2^31 <= Node.val <= 2^31 - 1
算法分析:
2021年8月10日21:05:35:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//二叉搜索树中序遍历递增,我们首先需要找到被交换的两个数,有两种情况:1.是相邻节点,如中序遍历序列是:1,2,4,3,5,我们找逆序对:4,3,我们显然可以发现是3和4被交换了,
//情况2:不是相邻节点,如中序遍历序列是1,6,3,4,5,2,7,我们找逆序对,发现两对:6,3和5,2,我们发现是第一个逆序对的第一个数和第二个逆序对的第二个数
//只有以上两种情况或者说可能,所以我们可以使用中序遍历求出中序数组,把两个被交换的节点交换一下,之后利用数组转二叉搜索树那个题目就可以
//上面做法很可以,就是空间复杂度是O(n),这个题目只能使用Morris 中序遍历,可以看y总的Morris 中序遍历的题解
//这个题目参考小呆呆的解法:注意两个错误的节点的关键点是可以形成逆序对,通过递归或者迭代的方式将整棵树的中序遍历排列出来,
//并且将两个错误的节点找出来,再将两个节点进行交换,这样就可以了,题目只要求我们把树恢复即可,时空间都是O(n)
//这个题目就是让我们找到两个错误的节点,交换这两个节点的值即可,注意最后交换的是节点的值,因为得到的节点不能返回,所以这个题目我们只能交换节点的值,这一点一定要注意,否则答案是不对的
class Solution {
List<TreeNode> list=new ArrayList<>(); //list数组列表用来记录二叉树的中序遍历的序列,注意存储的节点,而非值,所以这里泛型是TreeNode
public void recoverTree(TreeNode root) {
dfs(root); //从根节点开始递归中序遍历,注意树不空,所以可以不用特判
//dfs函数的作用就是求出二叉树的中序遍历的list数组结果,下面我们就需要遍历列表,找出要交换的两个节点,dfs函数就是这棵二叉树的中序遍历结果,我们遍历结果数组就可以得到两个要交换的节点,
TreeNode a=null,b=null; //定义节点a,b。a,b节点是要交换的错误节点
for(int i=0;i<list.size()-1;i++){ //遍历数组列表list,注意到n-1
if(list.get(i).val>list.get(i+1).val){ //找到了一组逆序对
b=list.get(i+1); //记录下来后一个节点
if(a==null){ //这个if(a==null)写的太牛皮了,这样就可以同时处理有一种逆序对和两个逆序对的情况了
a=list.get(i); //只有一个逆序对,则这里显然a被初始化为第一个节点,如果是两个逆序对,b被变为第二个逆序对的第二个节点,而a还是第一个逆序对的第一个节点
}
}
}
//经过上面的for循环就可以找到两个错误的节点,我们进行交换,注意交换的是节点的值,不是节点
int t=a.val;
a.val=b.val;
b.val=t;
//注意返回为空,这样就可以了,不用返回任何东西
}
public void dfs(TreeNode root){ //dfs函数的作用就是求出树的中序遍历的结果
if(root==null) return; //注意只是中序遍历函数,这里要写递归结束条件
dfs(root.left); //中序遍历先左,再根,最后右
list.add(root); //注意这里不是值,而就是节点,因为我们交换的时候是交换的节点
dfs(root.right);
}
}
2021年11月11日17:43:24:
//这个题目是二叉搜索树,其中序遍历是有序的,我们先求出其中序遍历的结果如1,2,3,4,5,6,7,如果有两个节点被错误的交换了,如:1,6,3,4,5,2,7
//我们可以发现两个错误的节点分别是第一个逆序对(6,3)的第一个节点和第二个逆序对(5,2)的第二个节点,我们遍历找到这两个节点,最后把这两个节点的值交换一下即可
//注意我们的List即遍历二叉树的集合中存储的是节点,不能是值,因为我们既要用点又要用值,所以我们存储节点,最后要记得交换两个节点的值
class Solution {
List<TreeNode> res=new ArrayList<>(); //集合res用于存储二叉树中序遍历的结果
public void recoverTree(TreeNode root) {
dfs(root); //从根节点开始中序遍历
int n=res.size();
TreeNode a=null,b=null; //节点a,b是两个错误的被交换的节点,我们先定义出来,再遍历中序遍历数组找出来这两个节点
for(int i=0;i<n-1;i++){ //遍历中序遍历的数组
if(res.get(i).val>res.get(i+1).val){ //找到一个逆序对
b=res.get(i+1); //这里的处理很巧妙,最后节点b的值就是第二个逆序对的第二个节点
if(a==null) a=res.get(i); //最后a节点就是第一个逆序对的第一个节点
}
}
//最后别忘了交换两个节点的值
int t=a.val;
a.val=b.val;
b.val=t;
}
public void dfs(TreeNode root){ //dfs函数完成二叉树的中序遍历
if(root==null) return;
dfs(root.left);
res.add(root); //res数组中存储的是节点,不是值
dfs(root.right);
}
}
108. 将有序数组转换为二叉搜索树
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
示例 1:

输入:nums = [-10,-3,0,5,9]
输出:[0,-3,9,-10,null,5]
解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:

示例 2:

输入:nums = [1,3]
输出:[3,1]
解释:[1,3] 和 [3,1] 都是高度平衡二叉搜索树。
提示:
1 <= nums.length <= 10^4
-10^4 <= nums[i] <= 10^4
nums 按 严格递增 顺序排列
算法分析
递归建立二叉搜索树,每次以中点为根结点,将左区间继续递归构建左子树,右区间继续递归构建右子树
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
return build(nums,0,nums.size()-1); //递归建树,最开始是从0到nums.size()-1;
}
TreeNode* build(vector<int> nums,int l,int r){
if(l>r) return nullptr; //递归结束条件,如果l大于了r,则返回空。
int mid=(l+r)>>1; //求中点,即根节点的位置。
auto root=new TreeNode(nums[mid]); //定义根节点
root->left=build(nums,l,mid-1); //对左子树递归建树,注意这里,传入的两个参数(这里是递归写法,所以是l和mid-1,而不能是具体的某个值)。
root->right=build(nums,mid+1,r); //对右子树递归建树。这里一样,注意传入的参数分别是mid+1,r
return root; //最后记得将根节点结果返回。
}
};
2021年8月10日15:24:01:
递归建树:y总牛皮,这个思路真的牛逼!!!
证明:

/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//本题要将数组转为平衡的二叉搜索树,即既是平衡二叉树的,又是二次搜索树,注意题目给定的是有序数组,我们递归建立二叉搜索树即可
//递归建立二叉搜索树,每次以中点为根结点,将左区间继续递归构建左子树,右区间继续递归构建右子树,我们可以证明,这样得到的就是平衡二叉搜索树
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return dfs(nums,0,nums.length-1); //最开始,区间的左右边界分别是0和n-1
}
public TreeNode dfs(int[] nums,int l,int r){ //编写dfs函数,每次递归传入的参数包括数组和左右边界
if(l>r) return null; //如果l大于了r,说明已经递归结束,返回null,递归结束条件,千万不要忘了写
int mid=(l+r)/2; //先求出中点的下标
//防止溢出:int mid = l + ((r-l)>>1);
TreeNode root=new TreeNode(nums[mid]); //建立根节点,根节点的值就是数组最中间数
root.left=dfs(nums,l,mid-1); //递归建树,左子树即往左边递归,注意此时的边界是l和mid-1
root.right=dfs(nums,mid+1,r); //递归建立根节点的右子树,往右边递归,这时的边界是mid+1和r
return root; //遍历结束就要返回递归建立好根节点值以及左右子树的根节点root
}
}
时间复杂度:O(n),因为数组中的每一个数字都会被遍历一遍。
109. 有序链表转换二叉搜索树
给定一个
单链表,其中的元素按升序排序,将其转换为高度平衡的二叉搜索树。
本题中,一个高度平衡二叉树是指一个二叉树
每个节点的左右两个子树的高度差的绝对值不超过 1。
示例:
给定的有序链表: [-10, -3, 0, 5, 9],
一个可能的答案是:[0, -3, 9, -10, null, 5], 它可以表示下面这个高度平衡二叉搜索树:
0
/ \
-3 9
/ /
-10 5
2021年8月10日16:00:11:
解法一:
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//这个题目是有序链表,而上个题目是有序数组,不同之处是,链表不能随机取值,即这个题目中的操作nums[mid]在这个题目中就不能使用了,
//但是我们可以开一个数组列表,遍历一下链表把链表节点值存到数组列表中,这样就转化为了和上一题一模一样的题目了,时间:o(n),空间o(n)
//我们也可以不用开额外的数组,即不使用o(n)的空间,空间复杂度是:o(1),时间复杂度:O(nlogn), 我们每次都顺序遍历找到中点
class Solution {
public TreeNode sortedListToBST(ListNode head) {
if(head==null) return null;
//先求出链表的长度
int n=0; //n记录链表的长度
for(ListNode p=head;p!=null;p=p.next) n++; //求出链表长度n
if(n==1) return new TreeNode(head.val); //如果只有一个节点,直接构造出来这个节点返回,这个条件一定要写,防止会空指针异常
//否则就需要找到中点,注意如果节点只有一个儿子节点,我们规定在左子树,并且中点的前一个节点的next要指向null,
//先找到中点的前一个节点,则中点就是这个节点的next
ListNode cur=head;
for(int i=0;i<n/2-1;i++) cur=cur.next; //找到中点的前一个节点
TreeNode root=new TreeNode(cur.next.val); //构造根节点,
root.right=sortedListToBST(cur.next.next); //在改变cur的指向之前先递归构造右子树
cur.next=null; //将前一个节点指向null
root.left=sortedListToBST(head); //递归构造左子树
return root; //将递归构造完值和左右子树的节点root进行返回
}
}
算法二:转化为和上一个题目一样的题目:
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
static TreeNode build(int[] nums, int l, int r)
{
if(l > r) return null;
int k = (l + r) / 2;
TreeNode root = new TreeNode(nums[k]);
root.left = build(nums, l, k - 1);
root.right = build(nums, k + 1, r);
return root;
}
public TreeNode sortedArrayToBST(int[] nums) {
int n = nums.length;
return build(nums,0,n - 1);
}
public TreeNode sortedListToBST(ListNode head) {
int k = 0;
ListNode p = head;
while(p != null)
{
k ++;
p = p.next;
}
int[] nums = new int[k];
p = head;
int t = 0;
while(p != null)
{
nums[t ++] = p.val;
p = p.next;
}
return sortedArrayToBST(nums);
}
}
173. 二叉搜索树迭代器
实现一个二叉搜索树迭代器。你将使用二叉搜索树的根节点初始化迭代器。
调用 next() 将返回二叉搜索树中的下一个最小的数。
示例:

BSTIterator iterator = new BSTIterator(root);
iterator.next(); // 返回 3
iterator.next(); // 返回 7
iterator.hasNext(); // 返回 true
iterator.next(); // 返回 9
iterator.hasNext(); // 返回 true
iterator.next(); // 返回 15
iterator.hasNext(); // 返回 true
iterator.next(); // 返回 20
iterator.hasNext(); // 返回 false
提示:
next() 和 hasNext() 操作的时间复杂度是 O(1),并使用 O(h) 内存,其中 h 是树的高度。
你可以假设 next() 调用总是有效的,也就是说,当调用 next() 时,BST 中至少存在一个下一个最小的数。
算法分析
1、二叉搜索树本身中序遍历后的元素是从小到大排序,因此找下一个最小的数,即在中序遍历中找当前元素的下一个元素
2、中序遍历的过程:将整棵树的最左边一条链压入栈中,每次取出栈顶元素,并记录栈顶元素,如果它有右子树,则将右子树压入栈中。
3、此题是在中序遍历迭代手法的基础上进行拆分,首先先把整个左链键入到栈中,
next()操作:当前pop()出的栈顶元素就是下一个最小的元素,
为了维护中序遍历的序列,因此需要把pop()出的栈顶元素的右儿子的左链的所有元素加入依次到栈中
hasNext()操作:判断栈是否有元素
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
//用94题中序遍历迭代的方法实现这个题目
class BSTIterator {
public:
stack<TreeNode*> stk; //定义中序遍历需要的栈
BSTIterator(TreeNode* root) {
while(root){
stk.push(root); //这两句代码是将根节点的左链插入到栈中。
root=root->left;
}
}
int next() {
auto root=stk.top(); //取栈顶元素
stk.pop(); //将栈顶元素删除
int val=root->val; //取出栈顶元素的值
root=root->right; //开始遍历最左节点的右子树
while(root){ //遍历最左节点的右子树
stk.push(root);
root=root->left;
}
return val; //每调用一次next(),返回一次栈顶元素
}
bool hasNext() {
return stk.size(); //hasNext()判断栈中是否还有元素。
}
};
2021年8月11日13:41:21:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//这个题目要做的其实就是把94题的迭代算法拆分为三部分分别放到三个函数中,其中,执行next函数应该执行遍历那一部分,
//执行hasnext的函数,其实判断的是是否到最后一个点,即判断栈是否为空,
class BSTIterator {
Stack<TreeNode> stk=new Stack<>(); //定义迭代中序遍历的栈
public BSTIterator(TreeNode root) {
//把迭代存放左子树的代码放在初始化函数这里
while(root!=null){
stk.add(root);
root=root.left; //一直往左链走
}
}
public int next() { //执行的其实就是遍历根节点那部分代码
TreeNode root=stk.peek(); //取出栈顶节点
stk.pop(); //弹出栈顶节点
int value=root.val; //先记录下来栈顶节点的值
root=root.right; //因为next函数可能不只是就执行1次,所以我们要完成完整的中序迭代的过程,所以这里要往右子树迭代遍历,并且把while循环也要补充完成
//因为之前的迭代中序遍历自己结束了一次while循环,会继续迭代执行下一次的while循环,而这里需要我们自己手动自己写出来
while(root!=null){
stk.add(root); //注意先把节点加到栈中,但是还没有遍历这个节点,等遍历完左子树之后再遍历当前节点
root=root.left; //先往左子树走
}
return value; //最后再把结点值返回
}
public boolean hasNext() {
return stk.size()!=0; //栈中只要有节点,hasNext函数会返回true
}
}
/**
* Your BSTIterator object will be instantiated and called as such:
* BSTIterator obj = new BSTIterator(root);
* int param_1 = obj.next();
* boolean param_2 = obj.hasNext();
*/
2021年11月12日20:10:46:
//本质上考察的是中序遍历的非递归遍历,我们在这里需要将二叉树的非递归中序遍历的过程拆开到next和hasNext操作中去
//next函数就是不断找中序遍历的下一个数,即后继,而hasNext函数就是判断一个节点是否有后继节点
class BSTIterator {
Stack<TreeNode> stk=new Stack<>(); //定义非递归遍历需要用到的栈
public BSTIterator(TreeNode root) { //放左链的步骤放在了这个函数中(因为next函数就是执行的遍历那部分的代码,而hasNext是判断栈是否为空)
while(root!=null){ //将根节点的左链放到栈中
stk.add(root);
root=root.left;
}
}
public int next() { //next就是执行的遍历那部分的代码
//执行的就是if(stk.size()!=0)的遍历那部分的代码
TreeNode t=stk.pop(); //取出栈顶元素,因为栈顶元素就是我们的后继节点
int val=t.val; //val就是我们要返回的后继节点的值,我们在返回其之前,需要先遍历其右子树,并将其右子树的左链加到栈中,
//因为上面的初始化的过程之后执行一次,而如果右子树再有左链的话,是无法处理的,所以我们将while(root!=null)中的语句这里也要写
t=t.right; //将根节点走到其右子树
while(t!=null){
stk.add(t);
t=t.left;
}
return val; //最后别忘了返回val
}
public boolean hasNext() { //hasNext就是判断其有没有下一个节点,其实就是看栈是否为空,因为栈顶元素存储的就是其后继节点
return stk.size()!=0; //hasNext就是判断栈是否不为空
}
}
230. 二叉搜索树中第K小的元素
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。
示例 1:

示例 2:
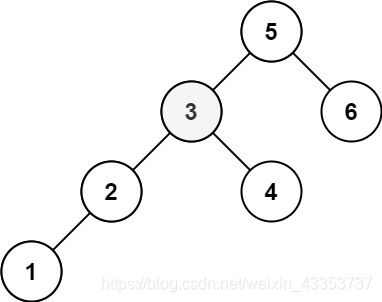
输入:root = [5,3,6,2,4,null,null,1], k = 3
输出:3
提示:
树中的节点数为 n 。
1 <= k <= n <= 10^4
0 <= Node.val <= 10^4
算法分析
先把二叉树的中序遍历的结果用链表存在起来,直接输出第k小即可
时间复杂度 O(k)
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
//因为二叉搜索树的中序遍历是从小到大有序的,所以这个题目等价于查找二叉搜索树中序遍历的第k个数。
//我们写一个中序遍历并用一个全局变量记录当前遍历到了第几个数,当遍历到第k个数就停下来就可以了。时间复杂度是O(K)。
class Solution {
public:
int _k,ans; //ans记录答案(即第K个数的值),k是全局变量
int kthSmallest(TreeNode* root, int k) {
_k=k; //把要找的位置数赋值给全局变量
dfs(root); //从根节点开始中序遍历。
return ans; //递归完将答案返回。
}
bool dfs(TreeNode* root){ //编写中序遍历,并且返回值为true代表已经搜索到了答案,为false则还没有找到答案
if(!root) return false; //空节点可能不是答案
if(dfs(root->left)==true) return true; //如果递归过程中,找到了第k个元素,就可以返回了
_k--; //每次递归将k值减一
if(_k==0) { //如果遍历到当前点k恰好为0了,即这就是第k个元素,
ans=root->val; //这个数就是答案
return true;
}
return dfs(root->right); //左子树和当前点都不是答案,我们继续在右子树递归。
}
};
2021年8月10日10:58:02:
递归:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//二叉搜索树的中序有序,所以求二叉搜索树的第k小元素,等价于求中序遍历的第k个树,所以这个题目我们写一个中序遍历,遍历的时候记一个全局变量记录当前遍历的是第几个数,
//注意别晕了,第k小元素就是中序遍历的第k个元素,而反过来的话其实是第k大元素
//遍历的时候记录一下当前遍历的是第几个数,当遍历到第k个数的时候就停下来,时间复杂度是o(k)。每中序遍历一个节点,让k减一,这样当k减到0的点就是第k小元素
class Solution {
int k,ans; //k用全局变量记录下来,这样写dfs函数的时候就可以用了,ans存储的是题目要求返回的第k个节点的值,
public int kthSmallest(TreeNode root, int _k) {
k=_k; //用k记录下来_k
dfs(root); //从根节点开始递归搜索,题目已经保证了树不空
return ans; //递归结束之后返回ans
}
public boolean dfs(TreeNode root){ //编写dfs函数,为了找到答案提前节点节省一些时间,我们使用boolean作为返回值,当找到第k小元素就返回true结束
if(root==null) return false; //找到了空节点,我们返回false,表示还没有找到第k小元素,
//下面写中序递归遍历,注意不是不变的递归遍历,在遍历的时候注意要做好判断和让k值减一
//先遍历当前节点的左子树,注意遍历的时候要做好标记记录
if(dfs(root.left)==true) return true; //注意中序遍历先遍历左子节点,当遍历到返回了true,就说明找到了答案,我们返回true,结束递归,
//注意,最终答案不是在这里返回的,而是通过全局答案进行返回的
//遍历当前节点
k--; //遍历当前节点,本质就是让k减去一,然后判断一下是否正好减到了0,
if(k==0){ //当正好减到了0,就说明当前节点正好就是第k小元素,
ans=root.val; //正好减到了0,上面当前节点就是答案,我们在全局答案ans上记录下来当前节点的值,注意答案要求返回的不是节点,而是值,所以我们记录的是val,而不是节点
return true; //return true不是找到了第k小元素,我们直接结束递归,返回true, 注意不光要记录下来答案,还要返回返回true,否则函数的返回语句就不完整
}
//否则说明还没有找到第k小元素,我们继续往当前节点的右子树进行递归
return dfs(root.right); //否则就往右子树继续递归查找,注意记得写return 语句,否则dfs函数的return部分就不完整
}
}
迭代:
在栈的帮助下,可以将方法一的递归转换为迭代,这样可以加快速度,因为这样可以不用遍历整个树,可以在找到答案后停止。
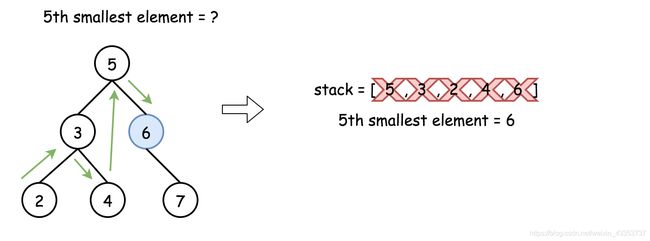
class Solution {
public int kthSmallest(TreeNode root, int k) {
LinkedList<TreeNode> stack = new LinkedList<TreeNode>();
while (true) {
while (root != null) {
stack.add(root);
root = root.left;
}
root = stack.removeLast();
if (--k == 0) return root.val;
root = root.right;
}
}
}
复杂度分析
时间复杂度:O(H+k),其中 H 指的是树的高度,由于我们开始遍历之前,要先向下达到叶,当树是一个平衡树时:复杂度为 O(logN+k)。当树是一个不平衡树时:复杂度为 O(N+k),此时所有的节点都在左子树。
空间复杂度:O(H+k)。当树是一个平衡树时:O(logN+k)。当树是一个非平衡树时:O(N+k)。
进阶要求频繁查找和修改,我们可以使用平衡二叉树,在二叉树的定义中加一个变量,维护一下每一个节点有多少个子节点,如果左子树的个数Lc<=k,则第k小元素在左子树,我们只需要往左子树递归即可,如果Lc+1=k,则我们只需要往右子树递归即可,否则往右子树递归,这样每次只需要往一边递归,时间复杂度就是o(logn)
235. 二叉搜索树的最近公共祖先(LCA)
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中
最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]

示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
解释: 节点 2 和节点 8 的最近公共祖先是 6。
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出: 2
解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
说明:
- 所有
节点的值都是唯一的。p、q为不同节点且均存在于给定的二叉搜索树中。
树的题目看一下能不能使用递归完成。
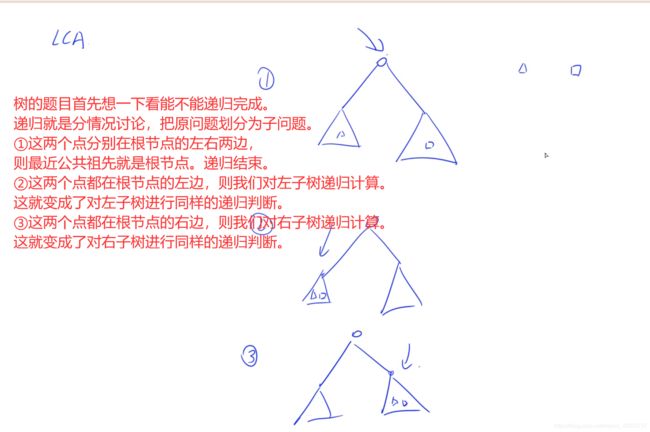
时间复杂度:每次递归我们只会递归一个分支,所以我们递归的最大深度就是树的高度,即时间复杂度是O(h).即O(logn).
判断p,q在哪一边用值判断。
算法分析 二叉搜索树的定义:左子树val小于根节点val,根节点值小于右子树val。
1.对于两个指针p和q,假设小的值是p,大的值是q(反过来也一样)
2.递归过程中只有3种情况 p.val <= root.val <= q.val(结束,返回root值即结果)、 root.val < p.val < q.val(往root.right递归)、 root.val > q.val > p.val(往root.left递归)。
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(p->val>q->val)swap(p,q); //为了方便,我们先让p这个点是值比较小的点,我们假设p的权值小于q,如果不是就交换两个节点(如原先是找8(p)和2(q)的最近公共祖先,现在是找2(p)和8(q))的最近公共祖先。
//现在p的权值就一定小于q了,题设中已经说明p,q是不同点且值一定不同。
if(p->val<=root->val&&q->val>=root->val) return root; //同时处理p,q在根节点左右两边和p或者q有一个就是根节点的情况,这种情况下答案就返回根节点,根节点就是最近公共祖先。
if(q->val<root->val) return lowestCommonAncestor(root->left,p,q); //如果q的权值都小于根节点的权值则说明p,q都在左子树,我们就对左子树进行递归即可。
else return lowestCommonAncestor(root->right,p,q); //否则p,q两个点就一定都在右子树里面,我们就对右子树进行递归。
}
};
2021年8月9日16:47:50:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
//LCA问题:看清楚这个题目是二叉搜索树的LCA,左子树<根<右子树 不是普通二叉树,所以我们就可以利用二叉搜索树是中序遍历有序这个特性来求解LCA
//还是想象“一圈带两个三角形”的模型,1.如果两个节点在当前节点的左右两边,则当前点就是这两个节点的LCA,2.如果两个节点都在当前节点的左边,则递归到左子树
//3.都在右边,则递归到右子树,那么我们如何知道到底是在哪一边呐?我们可以利用二叉搜索树的性质,即中序遍历有序来求解,
//我们规定p节点值
//注意看题目中的条件:所有节点的值都是唯一的;p、q 为不同节点且均存在于给定的二叉搜索树中。根据这两个条件我们可以知道我们的算法是正确的
//由于每次递归都可以去掉一边,或者说每次都往一个方向递归,所以时间复杂度是O(h),
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(p.val>=q.val) { //如果p节点值>=q节点值,我们就交换两个节点,所以p节点值一定是
TreeNode t=p; //不满足p值
p=q;
q=t;
}
if((p.val<=root.val)&&(q.val>=root.val)) return root; //注意这里一定要写=号,因为p,q是给定的点,而不是树上的点,所以有可能就是root节点,所以一定要写=
if(q.val<root.val) return lowestCommonAncestor(root.left,p,q); //往左子树递归,注意这里一定要写return,写了return才能继续往下递归
return lowestCommonAncestor(root.right,p,q); //否则就要往右子树递归,注意也要写return呀
//要写return ,因为这个函数是要求有返回值的
}
}
450. 删除二叉搜索树中的节点

解析:
图一:
图二:

2022年2月23日15:50:18:
//分几种情况:要删除的节点u:1.是叶节点,则我们自己删除这个结点,2.只有左/右节点,则我们只需要把这个左/右节点放到这个节点的位置即可
//这个节点左右节点都存在的话,我们就找到u的后继节点,将后继节点覆盖到u上,然后删除其后继节点即可,
//使用中序遍历(LNR),即删除的是替死鬼节点,注意因为是后继节点,所以一定是没有左孩子节点的(因为后继一定是右子树中最左边的节点),
//这样我们发现再删除这个替死鬼的时候,情况就转变为了第一种情况,或者是第二种情况中的只有右子树的情况了,这种情况就比较好写了
//因为我们每次只有从上往下递归遍历,所以时间复杂度是O(h)的,我们最多只会遍历整棵树的高度,
//这就是平衡树的经典删除操作
//具体我们可以直接使用题目中的deleteNode函数完成操作即可,函数是deleteNode(TreeNode root, int key),根据二叉树的性质,我们可以进行以下三步:
//1.当前节点值比key小,则需要递归到删除当前节点的左子树中key对应的值,返回deleteNode(root.left, key)
//2.当前节点值比key大,则需要递归到删除当前节点的右子树中key对应的值,返回deleteNode(root.right, key)
//3.当前节点等于key,则需要删除当前节点,并保证二叉搜索树的性质不变
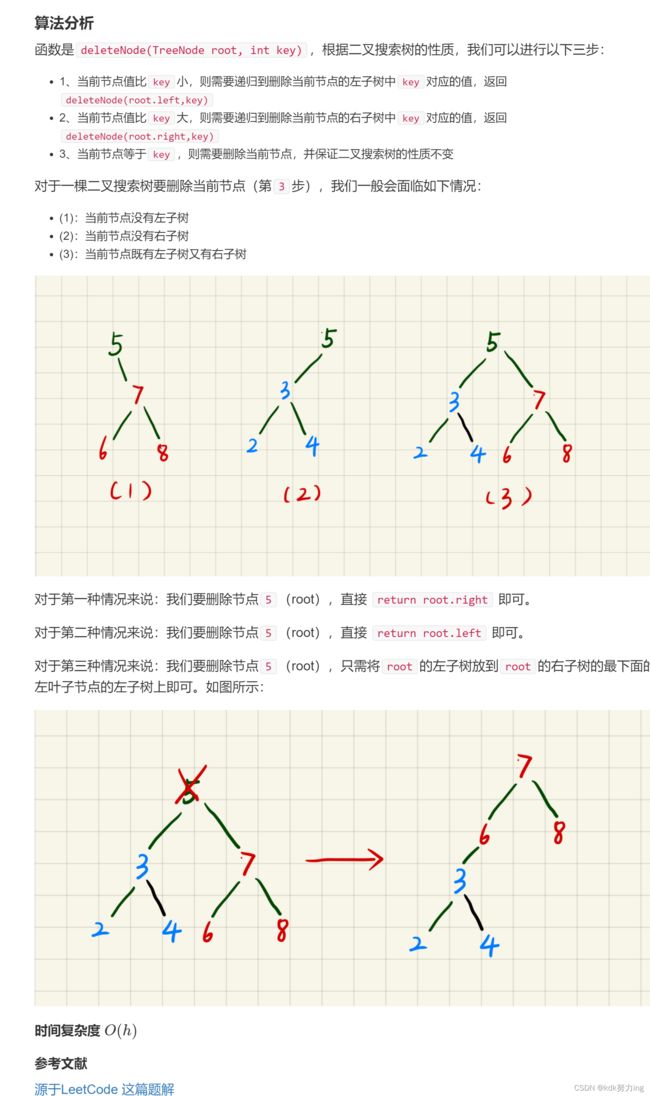
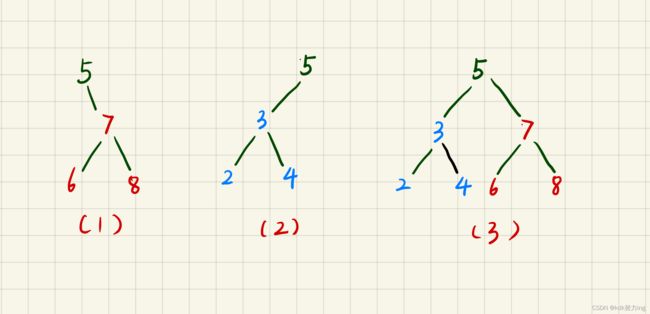
//上面的第三点(即当前节点等于key的时候),我们有以下几种情况:1.当前节点没有左子树,2.当前节点没有右子树,3.当前节点既有左子树又有右子树
//看图:对于第一种情况,当我们只有右子树的时候,我们要删除节点5的话,直接return root.right即可,
//第二种情况:我们要删除节点5,直接return root.left即可; 对于第三种情况,我们要删除节点5,只需将root的左子树放到root的右子树的最下面的左叶子节点的左子树上即可,如图所示
//
class Solution {
public TreeNode deleteNode(TreeNode root, int key) { //deleteNode的两个参数分别是要删除的树的根节点,key是要删除的节点
//deleteNode的作用是在root这棵树中,删除key这个节点,并且deleteNode的返回值是在root这棵树上删除key节点之后的新的根节点
if(root == null) return null; //如果节点为空,则我们就直接结束返回即可,这就是递归的结束条件
if(key < root.val){ //如果key的值是小于根节点的值,我们就递归到左子节点进行删除
root.left = deleteNode(root.left, key); //直接递归到左子树进行删除即可,并且其返回值就是root节点的新的左儿子节点
}else if(key > root.val){
root.right = deleteNode(root.right, key); //否则就递归到右子树进行删除,并且其返回值就是root节点的新的右儿子节点
}else { //再否则根节点就是要删除的节点,我们就要删除节点了
//核心就是删除函数,一共有四种情况
if(root.left == null) return root.right; //否则如果其只有右儿子(即左儿子为空),我们直接返回其右儿子节点即可
else if(root.right == null) return root.left; //否则只有左儿子,我们直接返回其右儿子节点即可
else{ //再否则就是其左右儿子都有的情况
TreeNode p = root.right; //我们要找到节点u的后继节点,即是右子树的最左边的儿子,
while(p.left != null) p = p.left; //只要节点p有左儿子,我们就一直往其左子树上走
//此时节点p就是上图的节点6,我们此时要把节点3放到节点6下,并且要返回节点7
p.left = root.left; //把节点3放到节点6下
return root.right; //返回的值就是节点7,即是root.right
}
}
return root; //最好上面两种情况下都没有返回值,我们要返回root节点,作为最后的返回值
}
}
501. 二叉搜索树中的众数

2021年11月12日11:18:17:
//二叉搜索树的中序遍历是有序的,所以我们对其中序遍历一下得到其中序遍历数组之后,就变成了在一个递增的一维数组中找众数的题目
//为了在O(1)的空间中找众数,由于是递增的,所以相同数都排在了一起,我们需要维护以下信息:1.last:上一段的最后一个数数值(即前一个数)
//2.cnt,当前数的个数,当我们遍历到一个新的数x的时候,如果x==last,则cnt++,否则我们让last=x,cnt=1,即我们新开了一段;
//并且为了判断每一段数是不是众数,我们需要记录一个maxC,即全局最大值,每次统计完一段之后,我们需要判断这一段数的出现个数是不是大于maxC,
//如果>maxC,说明新的众数找出来了,如果=maxC,说明我们的众数又多了一个,而且我们不需要先进行中序遍历,我们可以在中序遍历的过程中做以上判断
class Solution {
List<Integer> res=new ArrayList<>(); //res数组记录所有的众数
int maxC=0,curC=0,last=0; //maxC表示众数的个数,curC记录当前数的个数,last记录上一个数是什么
public int[] findMode(TreeNode root) {
dfs(root); //在中序遍历的过程中,完成众数的找寻
int n=res.size();
int[] f=new int[n];
for(int i=0;i<n;i++) f[i]=res.get(i);
return f;
}
public void dfs(TreeNode root){
if(root==null) return;
dfs(root.left); //中序遍历先遍历左子树
//再遍历根节点,在遍历根节点的时候我们要完成众数的找寻
if(curC==0||root.val==last) {
last=root.val; //先更新当前数(因为当curC=0的时候,我们不这样写就不存在last)
curC++; //如果当前数第一个数或者当前数和上一个相同,我们的当前数个数计数器curC就加一
}else{ //否则当前数就和上一个数不同,我们就要更新curC和last
last=root.val; //更新last为最新的是一个数,即当前数
curC=1; //当前数的个数为1
}
//判断一下是不是个数大于了maxC
if(curC>maxC){ //当前数大于了maxC,就说明当前数才是众数
while(res.size()!=0) res.remove(res.size()-1); //我们先将集合中的众数全部清空
res.add(last); //再将最新的众数加到答案集合中
maxC=curC; //记得要更新maxC为curC
}else if(curC==maxC){ //否则如果当前数的个数和maxC相等,就说明新的众数多了一个,我们就在res中加入当前数
res.add(last);
}
dfs(root.right); //最后递归遍历右子树
}
}
530. 二叉搜索树的最小绝对差

2022年1月2日15:20:18:
//二叉搜索树中序遍历是有序的,最小差可能就是两个相邻数的差值,所以我们在中序遍历的时候每次枚举两个相邻的数,求一个最小的差
//我们使用变量last表示当前节点的前一个节点的值,每次比较当前数和前一个是差,用这个差更新答案
//时间:O(n)
class Solution {
int res=0x3f3f3f3f; //res记录答案值
int last=0x3f3f3f3; //last表示是一个节点的值
boolean is_first=true; //布尔变量is_first表示当前节点是否是中序遍历的第一个节点,因为第一个节点前面是没有节点的
public int getMinimumDifference(TreeNode root) {
dfs(root);
return res;
}
public void dfs(TreeNode root){
if(root==null) return;
dfs(root.left);
if(is_first) is_first=false; //是第一个数,我们就不能更新res,我们将is_first改为false,表示我们已经访问完了第一个数了
else res=Math.min(res,root.val-last); //否则就不是第一个数,我们就用当前节点的值-last来更新res
last=root.val; //每遍历一个数就将当前是存到last里面
dfs(root.right);
}
}
538. 把二叉搜索树转换为累加树(dfs,逆中序遍历)
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
- 节点的左子树仅包含键 小于 节点键的节点。
- 节点的右子树仅包含键 大于 节点键的节点。
- 左右子树也必须是二叉搜索树。
注意:本题和 1038:1038把二叉搜索树转换为累加树 https://leetcode-cn.com/problems/binary-search-tree-to-greater-sum-tree/ 相同
示例 1:

输入:[4,1,6,0,2,5,7,null,null,null,3,null,null,null,8]
输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
示例 2:
输入:root = [0,null,1]
输出:[1,null,1]
示例 3:
输入:root = [1,0,2]
输出:[3,3,2]
示例 4:
输入:root = [3,2,4,1]
输出:[7,9,4,10]
提示:
- 树中的节点数介于 0 和 10^4 之间。
- 每个节点的值介于 -104和 104之间。
- 树中的所有值 互不相同 。
- 给定的树为二叉搜索树。
算法分析:
二叉搜索树的中序遍历是单调递增的。

- 要将原节点值替换为比它大的所有节点值之和
- 因为是二叉搜索树,LNR的顺序是递增的,那么RNL是递减的,N之前遍历到的所有节点都比当前节点大
- 这样我们在递归的时候,先遍历右孩子,再处理当前节点,即更新比他大的权值之和,再遍历左孩子
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int sum=0; //定义后缀和,完成逆中序遍历,即是按照RNL的顺序遍历
TreeNode* convertBST(TreeNode* root) {
dfs(root); //这里不是说从根节点开始递归,而是将root作为参数往下传递,看dfs还是可以知道我们是从右子树开始递归遍历的
return root; //递归结束返回根节点
}
void dfs(TreeNode* root){ //编写dfs函数,返回值类型为void
if(!root) return; //如果节点为空,我们就返回空即可
dfs(root->right); //先递归右子树
int x=root->val; //先记录下来这个节点的值,因为下面我们需要用到root->val,但是之后我们要对root->val做出改变,所以我们要先记录下来root->val的值
root->val +=sum; //将root->val改为其值加sum
sum+=x; //将后缀和sum改为sum+x
dfs(root->left); //继续往左子树递归
}
};
2021年8月27日17:24:01:
sum是共用的一个,所以我们要将sum定义为全局的。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
//先看清题目,这个题目是让我们把>该节点的权值之和都加到这个节点上,二叉树一般都是递归解决,二叉搜索树是中序有序的,
//注意看清题目,这个题目不能让自己本身再加到后缀和上,即只加比自己大的,不能再加一遍自己
//如果是对于一个有序的一维数组来说,完成>x的数累加到x上,我们可以从后往前维护一个后缀和,遍历到某个节点的时候,将后缀和加到这个节点上,并更新后缀和,
//那么我们该如何完成这个题目呐?我们知道二叉搜索树的中序遍历是有序的,即LNR的顺序有序,所以我们为了将>x的数累加到x节点上,我们只需要反向中序遍历,即RNL的顺序
//同样我们在遍历的时候,也需要维护一个后缀和,这样就相当于转化成了一维数组的问题,在实现的时候使用递归的方法完成反向遍历
class Solution {
int sum=0; //sum是后缀和,由于我们需要编写外部dfs函数,所以我们将sum定义为全局的
public TreeNode convertBST(TreeNode root) {
dfs(root); //传入root到dfs函数,完成RNL的递归遍历
return root; //注意题目要求我们返回节点,这个题目我们最后完成递归也要返回root节点
}
public void dfs(TreeNode root){
if(root==null) return; //递归结束条件,当递归到了空节点,直接return;即结束递归
dfs(root.right); //我们是要按照RNL的顺序遍历,所以先递归遍历右子树
//再遍历根节点,再遍历根节点的时候做一下操作:即更新后缀和,将后缀和加到当前节点的权值上
int x=root.val; //注意我们要先存下来当前节点的值,因为后面我们还会用到,而下面的语句会改变节点的值
root.val+=sum; //更新节点的值
sum+=x; //更新后缀和
dfs(root.left); //再递归遍历左子树
}
}
时间复杂度:时间复杂度:O(n),因为每个节点只会被遍历一次
700. 二叉搜索树中的搜索

class Solution {
TreeNode res = null;
public TreeNode searchBST(TreeNode root, int val) {
if(root == null) return null;
dfs(root, val);
return res;
}
public void dfs(TreeNode root, int val){
if(root == null) return;
if(root.val == val){
res = root;
return;
}
if(root.val > val) dfs(root.left, val);
else dfs(root.right, val);
}
}
701. 二叉搜索树中的插入操作

2022年3月5日11:17:51:
//就是简单的二叉搜索树的插入操作,逐个比较,将节点插到叶子结点上,注意每次比较都是要找到叶节点为止,在叶节点的位置上插入
class Solution {
public TreeNode insertIntoBST(TreeNode root, int val) {
if(root == null) return new TreeNode(val); //节点为空(就说明是叶子结点,在叶子结点建一个节点返回)将val作为根节点返回,这也是递归的结束条件
if(root.val > val) root.left = insertIntoBST(root.left, val); //否则如果当前节点的值大于val,就应该将val插入到当前节点的左边
else root.right = insertIntoBST(root.right, val); //否则就应该插入到右子树中,insertIntoBST的返回值是树的根节点
return root; //最后不管是向右子树中插入还是想左子树中中插入,我们都要将根节点返回
}
}