使用 openssl 进行 base64 编解码
使用 openssl 进行 base64 编解码。文章末尾的示例代码在 openssl1.1.1k 版本上验证通过。
BASE64 编码介绍
BASE64编码是一种常用的将十六进制数据转换为可见字符的编码。与ASCII码相比,它占用的空间较小。
BASE64 编解码原理
将数据编码成BASE64编码时,以3字节数据为一组,转换为24bit的二进制数,将24bit的二进制数分成四组,每组6bit。对于每一组,得到一个数字:0-63。然后根据这个数字查表即得到结果。表如下:
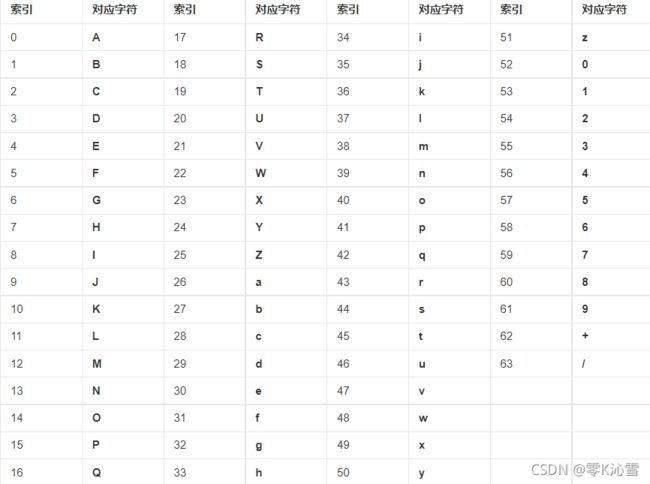
比如有数据:0x30 0x82 0x02
编码过程如下:
1)得到16进制数据: 30 82 02
2)得到二进制数据: 00110000 10000010 00000010
3)每6bit分组: 001100 001000 001000 000010
4)得到数字: 12 8 8 2
5)根据查表得到结果 : M I I C
BASE64填充:在不够的情况下在右边加0。
有三种情况:
1) 输入数据比特数是24的整数倍(输入字节为3字节整数倍),则无填充;
2) 输入数据最后编码的是1个字节(输入数据字节数除3余1),即8比特,则需要填充2个"==",因为要补齐6比特,需要加2个00;
3)输入数据最后编码是2个字节(输入数据字节数除3余2),则需要填充1个"=",因为补齐6比特,需要加一个00。
举例如下:
对0x30编码:
1) 0x30的二进制为:00110000
2) 分组为:001100 00
3) 填充2个00:001100 000000
4) 得到数字:12 0
5) 查表得到的编码为MA,另外加上两个==
所以最终编码为:MA==
base64解码是其编码过程的逆过程。解码时,将base64编码根据表展开,根据有几个等号去掉结尾的几个00,然后每8比特恢复即可。
主要函数
Openssl中用于base64编解码的函数主要有:
数据结构
EVP_ENCODE_CTX 编解码都需要用该结构。
定义方式:
EVP_ENCODE_CTX *EVP_ENCODE_CTX_new(void);编码函数
/*
初始化数据结构
*/
void EVP_EncodeInit(EVP_ENCODE_CTX *ctx);/*
进行 base64 编码
该函数每次编码 48 字节的源数据,得到 64 字节的加密数据,并在加密数据末尾加上换行符。
out: 加密数据存储区,使用者应该确保该区域有足够的空间存放加密数据
outl: 加密数据的长度,大小不会超过 65.
in: 源数据
inl: 源数据长度
该函数可以多次调用
*/
int EVP_EncodeUpdate(EVP_ENCODE_CTX *ctx, unsigned char *out, int *outl,
const unsigned char *in, int inl);/*
调用该函数之前必须先调用 EVP_EncodeUpdate 函数。
EVP_EncodeUpdate 处理后剩余的数据才由该函数处理
out: 加密数据缓冲区。应该传入调用 EVP_EncodeUpdate 后缓冲区剩余的部分的起始地址
outl: 会返回剩余源数据加密后的长度
*/
void EVP_EncodeFinal(EVP_ENCODE_CTX *ctx, unsigned char *out, int *outl);/*
base64 编码函数
该函数可以直接对源数据编码,得到未格式化的解码数据。
PS:经过 EVP_EncodeUpdate 和 EVP_EncodeFinal 编码的数据是有格式的(每 64 字节会有一个换行符)。
经过 EVP_EncodeBlock 编码的数据没有换行符,便于日常使用。
一般使用该函数进行 base64 编码
*/
int EVP_EncodeBlock(unsigned char *t, const unsigned char *f, int n);解码函数
/*
初始化数据结构
*/
void EVP_DecodeInit(EVP_ENCODE_CTX *ctx);/*
解码函数。与 EVP_EncodeUpdate 类似。
解码带格式的源数据
*/
int EVP_DecodeUpdate(EVP_ENCODE_CTX *ctx, unsigned char *out, int *outl,
const unsigned char *in, int inl);/*
解码函数。与 EVP_EncodeFinal 类似。必须在 EVP_DecodeUpdate 后调用。
解码带格式的源数据
*/
int EVP_DecodeFinal(EVP_ENCODE_CTX *ctx, unsigned char *out, int *outl);/*
解码函数
可以解码带格式的源数据,也可以解码不带格式的源数据。
*/
int EVP_DecodeBlock(unsigned char *t, const unsigned char *f, int n);示例代码
编码示例
/**
* @brief base64 编码,输出格式化的数据
*
* @param inData 源数据
*
* @return 编码后的数据
*/
char *base64_encode(char *inData)
{
if (NULL == inData)
{
return NULL;
}
int inl, outl, total, blocksize;
// 计算输入数据的长度
inl = strlen(inData);
/*
* 计算输出缓冲区大小
* Base64要求把每三个8Bit的字节转换为四个6Bit的字节(3*8 = 4*6 = 24)
* 然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
* */
blocksize = inl * 8 / 6 + 3;
char buffer[blocksize];
memset(buffer, 0, blocksize);
// 创建数据结构
EVP_ENCODE_CTX *e_ctx = EVP_ENCODE_CTX_new();
// 初始化数据结构
EVP_EncodeInit(e_ctx);
// 编码
outl = 0;
total = 0;
if (0 == EVP_EncodeUpdate(e_ctx, buffer, &outl, inData, inl))
{
goto err;
}
total += outl;
// 必须在编码操作结束时调用。它将处理ctx对象中剩余的任何部分数据块。
EVP_EncodeFinal(e_ctx, buffer + total, &outl);
total += outl;
EVP_ENCODE_CTX_free(e_ctx);
return strdup(buffer);
err:
EVP_ENCODE_CTX_free(e_ctx);
return NULL;
}
/**
* @brief base64 编码,输出非格式化的数据
*
* @param inData 源数据
*
* @return 编码后的数据
*/
char *base64_encode_block(char *inData)
{
if (NULL == inData)
{
return NULL;
}
int len, inl, blocksize;
inl = strlen(inData);
blocksize = inl * 8 / 6 + 3;
char buffer[blocksize];
memset(buffer, 0, blocksize);
len = EVP_EncodeBlock(buffer, inData, inl);
return strdup(buffer);
}
解码示例
/**
* @brief base64 解码。源数据是带格式的(每 64 字节有个换行符)
*
* @param inData 源数据
*
* @return 解码后的数据
*/
char *base64_decode(char *inData)
{
if (NULL == inData)
{
return NULL;
}
int inl, outl, total, blocksize;
// 计算输入数据的长度
inl = strlen(inData);
// base64 密文至少 4 字节
if (inl < 4)
{
return NULL;
}
outl = 0;
total = 0;
blocksize = inl * 6 / 8;
char buffer[blocksize];
memset(buffer, 0, blocksize);
// 创建数据结构
EVP_ENCODE_CTX *d_ctx = EVP_ENCODE_CTX_new();
// 初始化数据结构
EVP_DecodeInit(d_ctx);
// 出错时返回 -1,成功时返回 0 或 1。如果返回 0,则不需要更多的非填充 base 64 字符
if (-1 == EVP_DecodeUpdate(d_ctx, buffer, &outl, inData, inl))
{
goto err;
}
total += outl;
if (-1 == EVP_DecodeFinal(d_ctx, buffer, &outl))
{
goto err;
}
EVP_ENCODE_CTX_free(d_ctx);
return strdup(buffer);
err:
EVP_ENCODE_CTX_free(d_ctx);
return NULL;
}
/**
* @brief base64 解码。带不带格式都可以解码。建议使用这个解码,简单。
*
* @param inData 源数据
*
* @return 解码后的数据
*/
char *base64_decode_block(char *inData)
{
if (NULL == inData)
{
return NULL;
}
int inl, outl, blocksize;
inl = strlen(inData);
blocksize = inl * 6 / 8;
char buffer[blocksize];
memset(buffer, 0, blocksize);
outl = EVP_DecodeBlock(buffer, inData, inl);
return strdup(buffer);
}