sql报错注入 之 floor 函数报错:主键重复
Mysql报错注入之floor报错详解
updatexml extractvalue
floor 是mysql的函数
groupby+rand+floor+count
一、简述
利用 select count(*),(floor(rand(0)*2))x from table group by x,导致数据库报错,通过 concat 函数,连接注入语句与 floor(rand(0)*2)函数,实现将注入结果与报错信息回显的注入方式。
基本的查询 select 不必多说,剩下的几个关键字有 count 、group by 、floor、rand。
二、关键函数说明
1.rand函数
rand() 可以产生一个在0和1之间的随机数。
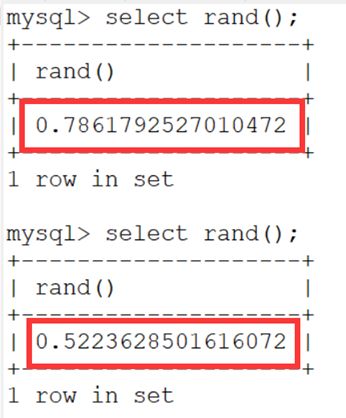
可见,直接使用rand函数每次产生的数都不同,但是当提供了一个固定的随机数的种子0之后:

每次产生的值都是一样的。也可以称之为伪随机(产生的数据都是可预知的)。
查看多个数据看一下。(users是一个有6行数据的表)

这样第一次产生的随机数和第二次完全一样,也就是可以预测的。
利用的时候rand(0)*2为什么要乘以 2 呢?这就要配合 floor 函数来说了。
2.floor(rand(0)*2)函数
floor() 函数的作用就是返回小于等于括号内该值的最大整数。
而rand() 是返回 0 到 1 之间的随机数,那么floor(rand(0))产生的数就只是0,这样就不能实现报错的:

而rand产生的数乘 2 后自然是返回 0 到 2 之间的随机数,再配合 floor() 就可以产生确定的两个数了。也就是 0 和 1:

并且根据固定的随机数种子0,他每次产生的随机数列都是相同的0 1 1 0 1 1。
3.group by 函数
group by 主要用来对数据进行分组(相同的分为一组)。
还是按照下表进行实验

首先我们在查询的时候是可以使用as用其他的名字代替显示的:

但是在实际中可以缺省as直接查询,显示的结果是一样的:

然后就可以用group by函数进行分组,并按照x进行排序
注意:最后x这列中显示的每一类只有一次,前面的a的是第一次出现的id值

4.count(*)函数
count(*)统计结果的记录数。
这里与group by结合使用看一下:

这里就是对重复性的数据进行了整合,然后计数,后面的x就是每一类的数量。
5.综合使用产生报错:
select count(*),floor(rand(0)*2) x from users group by x;
0 1 1 0 1 1
0 2
1 4
![]()
根据前面函数,这句话就是统计后面产生随机数的种类并计算每种数量。
分别产生0 1 1 0 1 1 ,这样0是2个,1是4个,但是最后却产生了报错。
0 2
1 4
三、报错分析
这个整合然后计数的过程中,中间发生了什么我们是必须要明白的。
首先mysql遇到该语句时会建立一个虚拟表。该虚拟表有两个字段,一个是分组的 key ,一个是计数值 count()。也就对应于实验中的 user_name 和 count()。
然后在查询数据的时候,首先查看该虚拟表中是否存在该分组,如果存在那么计数值加1,不存在则新建该分组。
然后mysql官方有给过提示,就是查询的时候如果使用rand()的话,该值会被计算多次,那这个"被计算多次"到底是什么意思,就是在使用group by的时候,floor(rand(0)*2)会被执行一次,如果虚表不存在记录,插入虚表的时候会再被执行一次,我们来看下floor(rand(0)*2)报错的过程就知道了,从上面的函数使用中可以看到在一次多记录的查询过程中floor(rand(0)*2)的值是定性的,为011011 (这个顺序很重要),报错实际上就是floor(rand(0)*2)被计算多次导致的,我们还原一下具体的查询过程:
(1)查询前默认会建立空虚拟表如下图:
(2)取第一条记录,执行floor(rand(0)*2),发现结果为0(第一次计算), 0 1 1 0 1 1

(3)查询虚拟表,发现0的键值不存在,则插入新的键值的时候floor(rand(0)*2)会被再计算一次,结果为1(第二次计算),插入虚表,这时第一条记录查询完毕,如下图: 0 1 1 0 1 1
0 1 1 0 1 1 0
0 1 1

(4)查询第二条记录,再次计算floor(rand(0)*2),发现结果为1(第三次计算)

(5)查询虚表,发现1的键值存在,所以floor(rand(0)2)不会被计算第二次,直接count()加1,第二条记录查询完毕,结果如下:
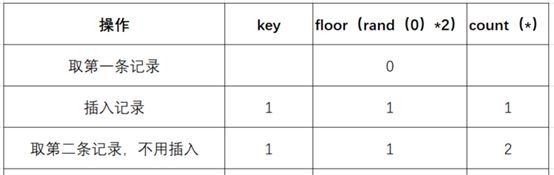
(6)查询第三条记录,再次计算floor(rand(0)*2),发现结果为0(第4次计算)
0 1 1 0

(7)查询虚表,发现键值没有0,则数据库尝试插入一条新的数据,在插入数据时floor(rand(0)*2)被再次计算,1作为虚表的主键,其值为1(第5次计算),插入

然而1这个主键已经存在于虚拟表中,而新计算的值也为1(主键键值必须唯一),所以插入的时候就直接报错了。
0 1 1 0 1
四、总结
select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x
security1
security1
security1
整个查询过程floor(rand(0)*2)被计算了5次,查询原数据表3次,所以这就是为什么数据表中需要最少3条数据,使用该语句才会报错的原因。
另外,要注意加入随机数种子的问题,如果没加入随机数种子或者加入其他的数,那么floor(rand()*2)产生的序列是不可测的,这样可能会出现正常插入的情况。最重要的是前面几条记录查询后不能让虚表存在0,1键值,如果存在了,那无论多少条记录,也都没办法报错,因为floor(rand()*2)不会再被计算做为虚表的键值,这也就是为什么不加随机因子有时候会报错,有时候不会报错的原因。
比如下面用1作为随机数种子,就不会产生报错:

