设计一个简单的,低耗的能够区分红酒和白酒的感知器(sensor)
学习using weka in your javacode
主要学习两个部分的代码:1、过滤数据集 2 使用J48决策树进行分类。下面的例子没有对数据集进行分割,完全使用训练集作为测试集,所以不符合数据挖掘的常识,但是下面这段代码的作用只是为了学习using weka in java
学习部分来自:http://weka.wikispaces.com/Use+WEKA+in+your+Java+code
part1
Filter
A filter has two different properties:
- supervised or unsupervised
either takes the class attribute into account or not - attribute- or instance-based
e.g., removing a certain attribute or removing instances that meet a certain condition
Most filters implement the OptionHandler interface, which means you can set the options via a String array, rather than setting them each manually via set-methods.
For example, if you want to remove the first attribute of a dataset, you need this filter
weka.filters.unsupervised.attribute.Remove
with this option
-R 1
If you have an Instances object, called data, you can create and apply the filter like this:
import weka.core.Instances; import weka.filters.Filter; import weka.filters.unsupervised.attribute.Remove; ... String[] options = new String[2]; options[0] = "-R"; // "range" options[1] = "1"; // first attribute Remove remove = new Remove(); // new instance of filter remove.setOptions(options); // set options remove.setInputFormat(data); // inform filter about dataset **AFTER** setting options Instances newData = Filter.useFilter(data, remove); // apply filter
part2
Train/test set
In case you have a dedicated test set, you can train the classifier and then evaluate it on this test set. In the following example, a J48 is instantiated, trained and then evaluated. Some statistics are printed to stdout:
import weka.core.Instances; import weka.classifiers.Evaluation; import weka.classifiers.trees.J48; ... Instances train = ... // from somewhere Instances test = ... // from somewhere // train classifier Classifier cls = new J48(); cls.buildClassifier(train); // evaluate classifier and print some statistics Evaluation eval = new Evaluation(train); eval.evaluateModel(cls, test); System.out.println(eval.toSummaryString("\nResults\n======\n", false));
下面是一个使用weka进行分类的小例子,后面附上实现这段过程的java代码。
设计一个简单的,低耗的能够区分红酒和白酒的感知器(sensor)
要求:
设计的感知器必须能够至少正确的区分95%的红酒和白酒的样本数据,样本数据集大小为:6497。
数据集Download from:www.technologyforge.net/Datasets
实验步骤:
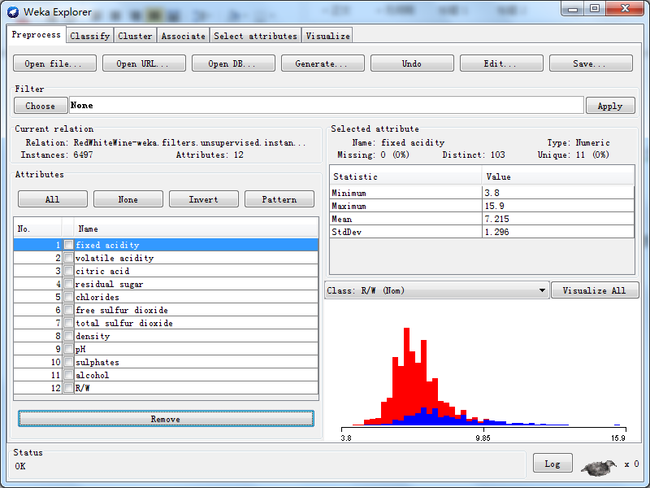
1、 数据预处理:移除属性quality。在这个试验中不需要用到酒的质量,只关注对白酒和红酒分类的准确率
选中:quality->点击remove
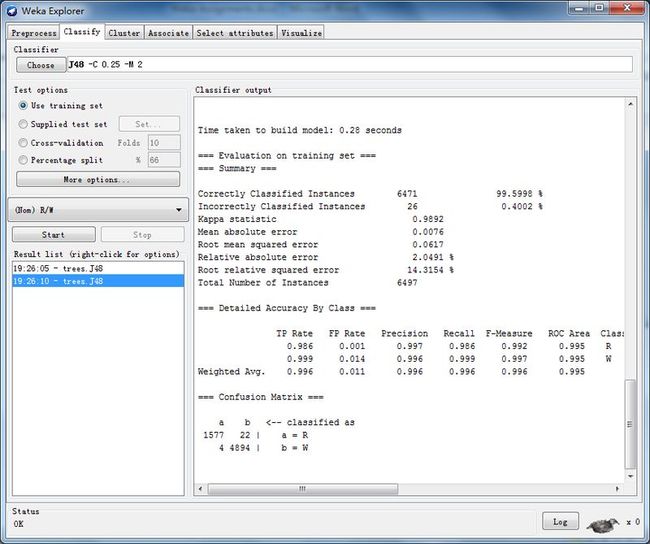
1、 运行默认设置的J48分类器得到一个使用所有属性值得分类结果。
从下图我们可以看到分类准确率达到99.5998%,准确率相当高
3.为了满足低耗的要求,所以我们要尽量使用最后的属性值也能达到95%的分类结果。这就需要重复试验。可以使用正反两个实验方向的方法试错,过程比较简单。
属性选择过程:可以根据图示观察不同属性对于分类结果的影响,经过比较观察可以看到下面两个属性是最能区分白酒和红酒的代表性属性。

分类性能:

使用java重复以上实验过程。
Javacode 如下
import weka.core.Instances; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.File; import javax.xml.crypto.Data; import weka.classifiers.Classifier; import weka.classifiers.meta.FilteredClassifier; import weka.classifiers.trees.J48; import weka.filters.Filter; import weka.filters.unsupervised.attribute.Remove; import weka.core.converters.ArffLoader; import weka.core.converters.ConverterUtils.DataSource; import weka.classifiers.Evaluation; public class RWClassifier { public static Instances getFileInstances(String filename) throws Exception{ FileReader frData =new FileReader(filename); Instances data = new Instances(frData); int length= data.numAttributes(); String[] options = new String[2]; options[0]="-R"; options[1]=Integer.toString(length); Remove remove =new Remove(); remove.setOptions(options); remove.setInputFormat(data); Instances newData= Filter.useFilter(data, remove); return newData; } public static void main(String[] args) throws Exception { Instances instances = getFileInstances("D://Weka_tutorial//WineQuality//RedWhiteWine.arff");//存储数据的位置 // System.out.println(instances); instances.setClassIndex(instances.numAttributes()-1); J48 j48= new J48(); j48.buildClassifier(instances); Evaluation eval = new Evaluation(instances); eval.evaluateModel(j48, instances); System.out.println(eval.toSummaryString("\nResults\n====\n", false)); } }
使用完整属性的分类结果(可以对比weka的运行结果,完全一致):
Results
====
Correctly Classified Instances 6471 99.5998 %
Incorrectly Classified Instances 26 0.4002 %
Kappa statistic 0.9892
Mean absolute error 0.0076
Root mean squared error 0.0617
Relative absolute error 2.0491 %
Root relative squared error 14.3154 %
Total Number of Instances 6497