Hive深入浅出
1. Hive是什么
1) Hive是什么?
这里引用 Hive wiki 上的介绍:
Hive is a data warehouse infrastructure built on top of Hadoop. It provides tools to enable easy data ETL, a mechanism to put structures on the data, and the capability to querying and analysis of large data sets stored in Hadoop files. Hive defines a simple SQL-like query language, called QL, that enables users familiar with SQL to query the data. At the same time, this language also allows programmers who are familiar with the MapReduce fromwork to be able to plug in their custom mappers and reducers to perform more sophisticated analysis that may not be supported by the built-in capabilities of the language.
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 QL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive does not mandate read or written data be in the “Hive format”—there is no such thing. Hive works equally well on Thrift, control delimited, or your specialized data formats. Please see File Format and SerDe in Developer Guide for details.

Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
2) Hive不是什么?
Hive基于hadoop,hadoop是批处理系统,不能保证低延迟,因此,hive的查询也不能保证低延迟。
Hive的工作模式是提交一个任务,等到任务结束时被通知,而不是实时查询。相对应的是,类似于oracle这样的系统当运行于小数据集的时候,响应非常快,可当处理的数据集非常大的时候,可能需要数小时。需要说明的是,hive即使在很小的数据集上运行,也可能需要数分钟才能完成。
总之,低延迟不是hive追求的首要目标。hive的设计目标是:可伸缩、可扩展、容错及输入格式松耦合。
Hive 资源
Hive 本身提供了较丰富的文档,以下链接提供了 Hive 的一些基础文档:
- FaceBook 镜像(被墙):[[http://mirror.facebook.com/facebook/hive]]
- Wiki 页面:[[http://wiki.apache.org/hadoop/Hive]]
- 入门指南:[[http://wiki.apache.org/hadoop/Hive/GettingStarted]]
- 查询语言指南:[[http://wiki.apache.org/hadoop/Hive/HiveQL]]
- 演示文稿:[[http://wiki.apache.org/hadoop/Hive/Presentations]]
- 蓝图:[[http://wiki.apache.org/hadoop/Hive/Roadmap]]
大多数有关 Hive 的使用和特性的问题可以从以上的链接中寻找到答案。当然,由于 Hive 本身在不断的发展中,文档的更新速度很多时候都赶不上 Hive 本身的更新速度,若希望了解 Hive 的最新动态或者遇到 Bug,可以加入 Hive 的邮件列表:
* User: [email protected]
* Developer: [email protected]
1. 为什么使用Hive
2. Hive体系结构
Hive 的结构如图所示,
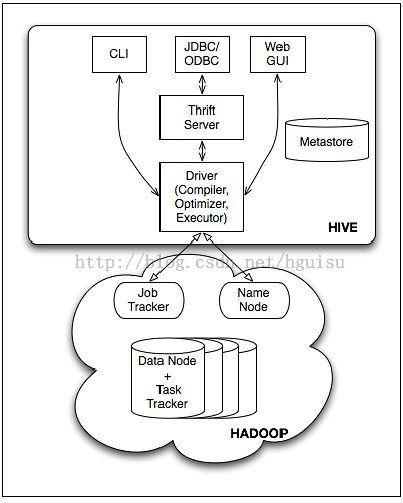
主要分为以下几个部分:
- 用户接口,包括 命令行CLI,Client,Web界面WUI,JDBC/ODBC接口等
- 中间件:包括thrift接口和JDBC/ODBC的服务端,用于整合Hive和其他程序。
- 元数据metadata存储,通常是存储在关系数据库如 mysql, derby 中的系统参数
- 底层驱动:包括HiveQL解释器、编译器、优化器、执行器(引擎)。
- Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算。
- 用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
- Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
- Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from tbl 不会生成 MapRedcue 任务)。
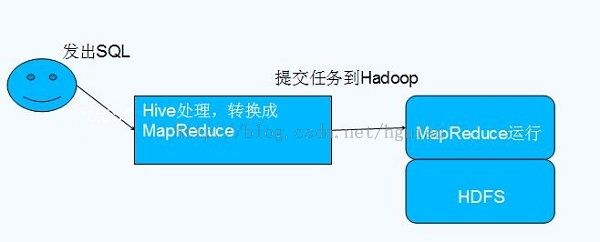
3. Hive元数据存储
MetaStore类似于Hive的目录。它存放了有个表、区、列、类型、规则模型的所有信息。并且它可以通过thrift接口进行修改和查询。它为编译器提供高效的服务,所以,它会存放在一个传统的RDBMS,利用关系模型进行管理。这个信息非常重要,所以需要备份,并且支持查询的可扩展性。
Hive 将元数据存储在 RDBMS 中,有三种模式可以连接到数据库:
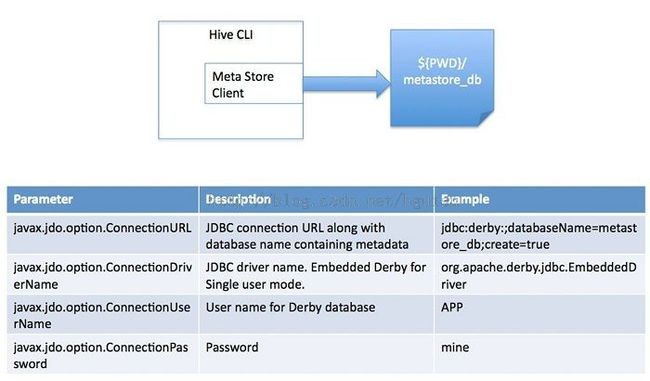
- Single User Mode: 此模式连接到一个 In-memory 的数据库 Derby,一般用于 Unit Test。
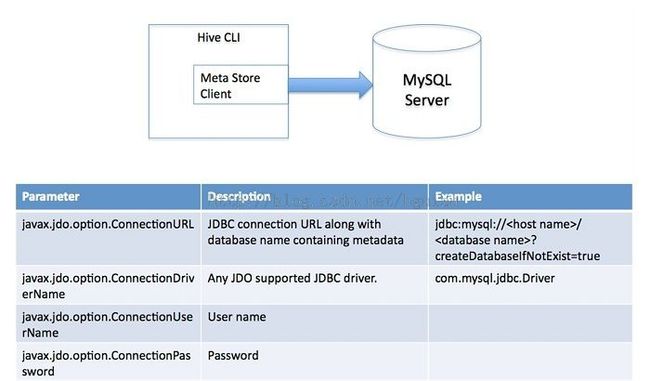
- Multi User Mode:通过网络连接到一个数据库中,是最经常使用到的模式。
 、
、
- Remote Server Mode:用于非 Java 客户端访问元数据库,在服务器端启动一个 MetaStoreServer,客户端利用 Thrift 协议通过 MetaStoreServer 访问元数据库。
- 解析用户提交hive语句,对其进行解析,分解为表、字段、分区等hive对象
- 根据解析到的信息构建对应的表、字段、分区等对象,从SEQUENCE_TABLE中获取构建对象的最新ID,与构建对象信息(名称,类型等)一同通过DAO方法写入到元数据表中去,成功后将SEQUENCE_TABLE中对应的最新ID+5。
4. Hive的数据存储
首先,Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
其次,Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:Table,External Table,Partition,Bucket。
1)表table:一个表就是hdfs中的一个目录
2)区Partition:表内的一个区就是表的目录下的一个子目录
3)桶Bucket:如果有分区,那么桶就是区下的一个单位,如果表内没有区,那么桶直接就是表下的单位,桶一般是文件的形式。
- Hive 中的 Table 和数据库中的 Table 在概念上是类似的,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh 是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
- Partition 对应于数据库中的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。例如:pvs 表中包含 ds 和 city 两个 Partition,则对应于 ds = 20090801, ctry = US 的 HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA。表是否分区,如何添加分区,都可以通过Hive-QL语言完成。通过分区,即目录的存放形式,Hive可以比较容易地完成对分区条件的查询。
- Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件。将 user 列分散至 32 个 bucket,首先对 user 列的值计算 hash,对应 hash 值为 0 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00000;hash 值为 20 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00020 。桶是Hive的最终的存储形式。在创建表时,用户可以对桶和列进行详细地描述。
- External Table 指向已经在 HDFS 中存在的数据,可以创建 Partition。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
- Table 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
- External Table 只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在 LOCATION 后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。当删除一个 External Table 时,仅删除
5. Hive和普通关系型数据库的差异
由于 Hive 采用了 SQL 的查询语言 HQL,因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
和普通关系数据库的异同:
| Hive | RDBMS | |
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 索引 | 无 | 有 |
| 执行 | MapReduce | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
1. 查询语言。由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
2. 数据存储位置。Hive 是建立在Hadoop 之上的,所有 Hive 的数据都是存储在HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
3. 数据格式。Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS
目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
4. 数据更新。由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE… SET 修改数据。
5. 索引。之前已经说过,Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些 Key 建立索引。Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了
Hive 不适合在线数据查询。
6. 执行。Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的(类似 select * from tbl 的查询不需要 MapReduce)。而数据库通常有自己的执行引擎。
7. 执行延迟。之前提到,Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
8. 可扩展性。由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是一致的(世界上最大的 Hadoop 集群在 Yahoo!,2009年的规模在4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
9. 数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
5. Hive的基本概念
参考:https://cwiki.apache.org/confluence/display/Hive/Tutorial
1)数据单元
按照数据的粒度大小,hive数据可以被组织成:
1)databases: 避免不同表产生命名冲突的一种命名空间
2)tables:具有相同scema的同质数据的集合
3)partitions:一个表可以有一个或多个决定数据如何存储的partition key
4)buckets(或clusters):在同一个partition中的数据可以根据某个列的hash值分为多个bucket。partition和bucket并非必要,但是它们能大大加快数据的查询速度。
2)、数据类型
(1)简单类型:
TINYINT - 1 byte integer
SMALLINT - 2 byte integer
INT - 4 byte integer
BIGINT - 8 byte
BOOLEAN - TRUE/ FALSE
FLOAT - 单精度
DOUBLE - 双精度
STRING - 字符串集合
(2)复杂类型:
Structs: structs内部的数据可以通过DOT(.)来存取,例如,表中一列c的类型为STRUCT{a INT; b INT},我们可以通过c.a来访问域a。
Maps(Key-Value对):访问指定域可以通过['element name']进行,例如,一个Map M包含了一个group->gid的k-v对,gid的值可以通过M['group']来获取。
Arrays:array中的数据为相同类型,例如,假如array A中元素['a','b','c'],则A[1]的值为'b'。
3)、内建运算符和函数
包括关系运算符(A=B, A!=B, A<B等等)、
算术运算符(A+B, A*B, A&B, A|B等等)、
逻辑运算符(A&&B, A|B等等)、
复杂类型上的运算符(A[n], M[key], S.x)、
各种内建函数:round,floor,substr
4)、语言能力
hive查询语言提供基本的类sql操作,这些操作基于table和partition,包括:
1. 使用where语句过滤制定行
2. 使用select查找指定列
3. join两张table
4. group by
5. 一个表的查询结果存入另一张表
6. 将一个表的内容存入本地目录
7. 将查询结果存储到hdfs上
8. 管理table和partition(creat、drop、alert)
9. 在查询中嵌入map-reduce程序
Hive query language provides the basic SQL like operations. These operations work on tables or partitions. These operations are:
- Ability to filter rows from a table using a where clause.
- Ability to select certain columns from the table using a select clause.
- Ability to do equi-joins between two tables.
- Ability to evaluate aggregations on multiple "group by" columns for the data stored in a table.
- Ability to store the results of a query into another table.
- Ability to download the contents of a table to a local (e.g., nfs) directory.
- Ability to store the results of a query in a hadoop dfs directory.
- Ability to manage tables and partitions (create, drop and alter).
- Ability to plug in custom scripts in the language of choice for custom map/reduce jobs.
6. Hive实际应用
1、Apache Weblog Data
The format of Apache weblog is customizable, while most webmasters use the default.
For default Apache weblog, we can create a table with the following command.
More about !RegexSerDe can be found here in HIVE-662 and HIVE-1719.