Go语言的切片 slice
什么是切片 slice
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go中提供了一种灵活,功能强悍的内置类型切片(“动态数组”),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大
Go的切片类型为处理同类型数据序列提供一个方便而高效的方式。 切片有些类似于其他语言中的数组,但是有一些不同寻常的特性。 本文将深入切片的本质,并讲解它的用法。
定义切片
// 第一种
var identifier []type
//第二种 使用make
var slice1 []type = make([]type, len)
//简写成
slice1 := make([]type, len)
//使用make来创建slice,map,chanel说明如下
//第三种,通过对数组操作返回
course := [5]string{"django", "tornado", "scrapy", "python", "asyncio"}
subCourse := course[1:2]
fmt.Printf("%T", subCourse)
切片初始化
s :=[] int {1,2,3 }
直接初始化切片,[]表示是切片类型,{1,2,3}初始化值依次是1,2,3.其cap=len=3
s := arr[:]
| 序号 | 方式 | 代码示例 |
|---|---|---|
| 1 | 直接声明 | var slice []int |
| 2 | new | slice := *new([]int) |
| 3 | 字面量 | slice := []int{1,2,3,4,5} |
| 4 | make | slice := make([]int, 5, 10) |
| 5 | 从切片或数组“截取” | slice := array[1:5] 或 slice := sourceSlice[1:5] |
append 追加
slice是动态数组,所以说我们需要动态添加值
package main
import (
"fmt"
)
func main() {
var course = [5]string{"django", "scrapy", "tornado", "flask", "docker"}
slice1 := course[1:4]
// append 可以向切片追加元素
slice1 = append(slice1, "go")
fmt.Println(slice1) //[scrapy tornado flask go]
}
// append 追加多个元素
slice1 = append(slice1, "go","python1", "python2")
fmt.Println(slice1) //[scrapy tornado flask go python1 python2]
切片合并
subCourse2 := course[1:3]
appendedCourse := []string{" imooc"," imooc2" ," imooc3"}
subCourse2 = append(subCourse2, appendedCourse...) //函数的参数传递规则
fmt.Println(subCourse2 )
切片拷贝
package main
import (
"fmt"
)
func main() {
var course = [5]string{"django", "scrapy", "tornado", "flask", "docker"}
slice1 := course[1:4]
slice2 := make([]string, len(slice1))
copy(slice2, slice1)
fmt.Println(slice2) // [scrapy tornado flask go]
// 注意,长度是2的时候,只能拷贝前两个
slice3 := make([]string, 2)
copy(slice3, slice1)
fmt.Println(slice3) //[scrapy tornado]
}
切片删除
deleteCourse := [5]string{"django", "scrapy", "tornado", "flask", "docker"}
courseSlice := deleteCourse[:] // 转成切片
// 删除第二个
courseSlice = append(courseSlice[:1], deleteCourse[2:]...)
fmt.Println(courseSlice) //[django tornado flask docker]
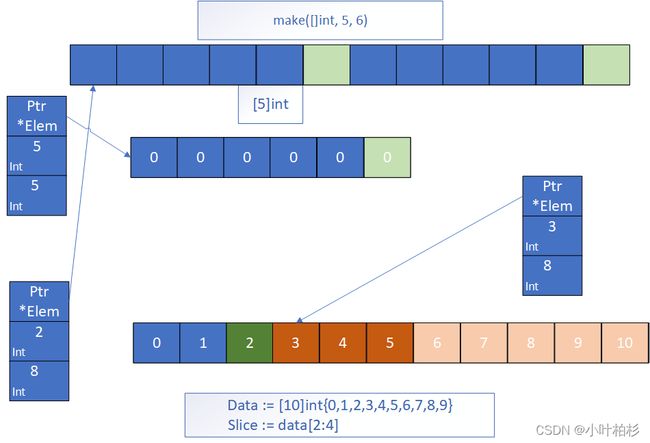
切片原理

- 指针
- 长度
- 容量
type slice struct {
array unsafe.Pointer // 元素指针
len int // 长度
cap int // 容量
}
可以指定容量的大小
data := make([]int, 0, 3) //容量=3
fmt.Printf("len=%d, cap=%d\n", len(data), cap(data)) // len=0, cap=3
扩容策略:
oldSlice := make([]int, 0)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice)) //len=0, cap=0
oldSlice = append(oldSlice, 1)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice)) //len=1, cap=1
oldSlice = append(oldSlice, 2)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice)) //len=2, cap=2
oldSlice = append(oldSlice, 3)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice)) //len=3, cap=4
oldSlice = append(oldSlice, 4)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice)) //len=4, cap=4
oldSlice = append(oldSlice, 5)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice)) //len=5, cap=8
oldSlice = append(oldSlice, 6)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice)) //len=6, cap=8
向切片新增一个元素时,若该切片容量已满,会首先根据切片容量进行判断,小于1024字节扩容为原有容量的2倍,大于1024字节扩容为原有容量的1.25倍
扩容的三种现象:
a := make([]int, 0)
b := []int{1, 2, 3}
//1. 第一个现象
fmt.Println(copy(a, b))
fmt.Println(a) // 0
// 不会扩展a的空间
a := make([]int, 0)
b := []int{1, 2, 3}
//2.第二个现象
c := b[:]
c[0] = 8
fmt.Println(b) //[8 2 3]
fmt.Println(c) //[8 2 3]
//指向一个内存地址,改其中一个都会有影响
a := make([]int, 0)
b := []int{1, 2, 3}
//3.第三个现象
c := b[:]
c = append(c, 9)
fmt.Println(b) //[1 2 3] append函 数没有影响到原来的数组
fmt.Println(c) //[1 2 3 9]
//这就是因为产生了扩容机制,扩容机制一旦产生这个时候切片就会指向新的内存地址
c[0] = 8
fmt.Println(b) //[1 2 3]
fmt.Println(c) //[8 2 3 9] 为什么append函数之 后再调用c[0]=8不会影响到原来的数组
//切片扩容问题,扩容阶段会影响速度,python的list中底层实际也是数组,也会面临动态扩容的问题,但python的list中数据类型可以不一致
- 底层是数组,如果是基于数组产生的,会有一个问题就是会影响原来的数组。
- 切片的扩容机制
- 切片的传递是引用传递
内存分配策略
Go语言内置运行时(就是runtime),抛弃了传统的内存分配方式,改为自主管理。这样可以自主地实现更好的内存使用模式,比如内存池、预分配等等。这样,不会每次内存分配都需要进行系统调用。
Golang运行时的内存分配算法主要源自 Google 为 C 语言开发的TCMalloc算法,全称Thread-Caching Malloc。核心思想就是把内存分为多级管理,从而降低锁的粒度。它将可用的堆内存采用二级分配的方式进行管理:每个线程都会自行维护一个独立的内存池,进行内存分配时优先从该内存池中分配,当内存池不足时才会向全局内存池申请,以避免不同线程对全局内存池的频繁竞争。
Go里mspan的Size Class共有67种,每种mspan分割的object大小是8*2n的倍数,这个是写死在代码里的:
// path: /usr/local/go/src/runtime/sizeclasses.go
const _NumSizeClasses = 67
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536,1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
slice的三种状态
「零切片」、「空切片」和「nil 切片」
package main
import (
"fmt"
)
func main() {
//零切片
var z = make([]int, 10)
fmt.Println(z)
//nil切片和空切片
var s1 []int
var s2 = []int{}
var s3 = make([]int, 0)
// new 函数返回是指针类型,所以需要使用 * 号来解引用
var s4 = *new([]int)
fmt.Println(len(s1), len(s2), len(s3), len(s4)) //0 0 0 0
fmt.Println(cap(s1), cap(s2), cap(s3), cap(s4)) //0 0 0 0
fmt.Println(s1, s2, s3, s4) //[] [] [] []
}
上面这四种形式从输出结果上来看,似乎一摸一样,没区别。但是实际上是有区别的,我们要讲的两种特殊类型「空切片」和「 nil 切片」,就隐藏在上面的四种形式之中。
我们如何来分析三面四种形式的内部结构的区别呢?接下里要使用到 Go 语言的高级内容,通过 unsafe.Pointer 来转换 Go 语言的任意变量类型。
因为切片的内部结构是一个结构体,包含三个机器字大小的整型变量,其中第一个变量是一个指针变量,指针变量里面存储的也是一个整型值,只不过这个值是另一个变量的内存地址。我们可以将这个结构体看成长度为 3 的整型数组 [3]int。然后将切片变量转换成 [3]int。
package main
import (
"fmt"
"unsafe"
)
func main() {
var s1 []int
var s2 = []int{}
var s3 = make([]int, 0)
var s4 = *new([]int)
var a1 = *(*[3]int)(unsafe.Pointer(&s1))
var a2 = *(*[3]int)(unsafe.Pointer(&s2))
var a3 = *(*[3]int)(unsafe.Pointer(&s3))
var a4 = *(*[3]int)(unsafe.Pointer(&s4))
fmt.Println(a1) //[0 0 0]
fmt.Println(a2) //[824634555992 0 0]
fmt.Println(a3) //[824634555992 0 0]
fmt.Println(a4) //[0 0 0]
}
从输出中我们看到了明显的神奇的让人感到意外的难以理解的不一样的结果。
其中输出为 [0 0 0] 的 s1 和 s4 变量就是「 nil 切片」,s2 和 s3 变量就是「空切片」。824634199592 这个值是一个特殊的内存地址,所有类型的「空切片」都共享这一个内存地址。

切片指向的 zerobase 内存地址是一个神奇的地址,从 Go 语言的源代码中可以看到它的定义
runtime/malloc.go
// base address for all 0-byte allocations
var zerobase uintptr
// 分配对象内存
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
if size == 0 {
return unsafe.Pointer(&zerobase)
}
...
}
runtime/slice.go
// 创建切片
func makeslice(et *_type, len, cap int) slice {
...
p := mallocgc(et.size*uintptr(cap), et, true)
return slice{p, len, cap}
}
最后一个问题是:「 nil 切片」和 「空切片」在使用上有什么区别么?
答案是完全没有任何区别!No!不对,还有一个小小的区别!请看下面的代码
package main
import "fmt"
func main() {
var s1 []int
var s2 = []int{}
fmt.Println(s1 == nil) //true
fmt.Println(s2 == nil) //false
fmt.Printf("%#v\n", s1) //[]int(nil)
fmt.Printf("%#v\n", s2) //[]int{}
}
所以为了避免写代码的时候把脑袋搞昏的最好办法是不要创建「 空切片」,统一使用「 nil 切片」,同时要避免将切片和 nil 进行比较来执行某些逻辑。这是官方的标准建议。
空结构体是没有内存大小的结构体。这句话是没有错的,但是更准确的来说,其实是有一个特殊起点的,那就是 zerobase 变量,这是一个 uintptr 全局变量,占用 8 个字节。当在任何地方定义无数个 struct {} 类型的变量,编译器都只是把这个 zerobase 变量的地址给出去。换句话说,在 golang 里面,涉及到所有内存 size 为 0 的内存分配,那么就是用的同一个地址 &zerobase 。
「空切片」和「 nil 切片」有时候会隐藏在结构体中,这时候它们的区别就被太多的人忽略了,下面我们看个例子:
type Something struct {
values []int
}
var s1 = Something{}
var s2 = Something{[]int{}}
fmt.Println(s1.values == nil) //true
fmt.Println(s2.values == nil) //false
可以发现这两种创建结构体的结果是不一样的!
「空切片」和「 nil 切片」还有一个极为不同的地方在于 JSON 序列化
package main
import (
"encoding/json"
"fmt"
)
type Something struct {
Values []int
}
func main() {
var s1 = Something{}
var s2 = Something{[]int{}}
bs1, _ := json.Marshal(s1)
bs2, _ := json.Marshal(s2)
fmt.Println(string(bs1)) //{"Values":null}
fmt.Println(string(bs2)) //{"Values":[]}
}
总结:
- 切片是对底层数组的一个抽象,描述了它的一个片段。
- 切片实际上是一个结构体,它有三个字段:长度,容量,底层数据的地址。
- 多个切片可能共享同一个底层数组,这种情况下,对其中一个切片或者底层数组的更改,会影响到其他切片。
- append 函数会在切片容量不够的情况下,调用 growslice 函数获取所需要的内存,这称为扩容,扩容会改变元素原来的位置。
- 扩容策略并不是简单的扩为原切片容量的 2 倍或 1.25 倍,还有内存对齐的操作。扩容后的容量 >= 原容量的 2 倍或 1.25 倍。
- 当直接用切片作为函数参数时,可以改变切片的元素,不能改变切片本身;想要改变切片本身,可以将改变后的切片返回,函数调用者接收改变后的切片或者将切片指针作为函数参数。