dirsearch 综合指南
简单使用
python dirsearch.py -u https://target python dirsearch.py -e php,html,js -u https://target python dirsearch.py -e php,html,js -u https://target -w /path/to/wordlist
简单演示
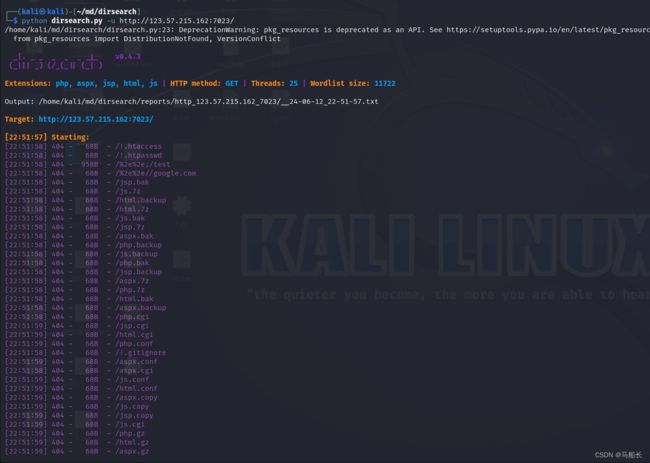
针对敏感文件、目录扫描
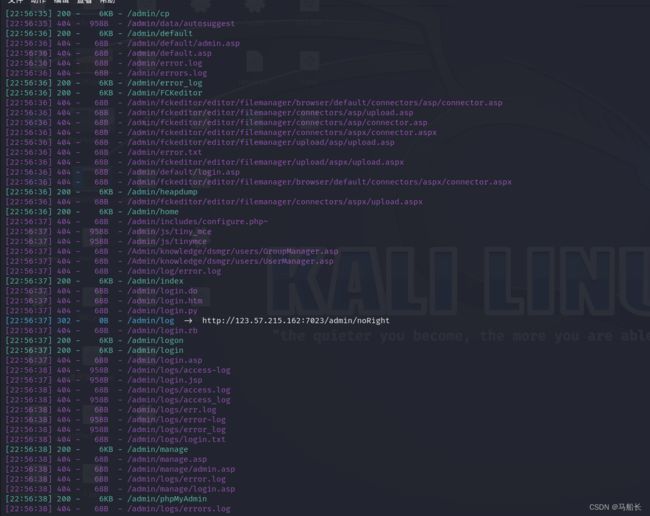
基础使用
-u URL, --url=URL URL目标
-L URLLIST, --url-list=URLLIST URL列表目标
-e EXTENSIONS, --extensions=EXTENSIONS 以逗号分隔的扩展列表(示例:php、asp)
-E, --extensions-list 使用公共扩展的预定义列表
Dictionary Settings:
-w WORDLIST, --wordlist=WORDLIST 自定义单词表(用逗号分隔)
-l, --lowercase
-f, --force-extensions 强制扩展每个单词表条目(如DirBuster)常规设置:
-s DELAY, --delay=DELAY 请求之间的延迟(浮点数)
-r, --recursive 递归暴力
-R RECURSIVE_LEVEL_MAX, --recursive-level-max=RECURSIVE_LEVEL_MAX 最大递归级别(子目录)(默认值:1[仅限根目录+1目录])
--suppress-empty, --suppress-empty
--scan-subdir=SCANSUBDIRS, --scan-subdirs=SCANSUBDIRS 扫描给定-u |--url的子目录(分开逗号)
--exclude-subdir=EXCLUDESUBDIRS, --exclude-subdirs=EXCLUDESUBDIRS 在递归过程中排除下列子目录扫描(用逗号分隔)
-t THREADSCOUNT, --threads=THREADSCOUNT 线程数
-x EXCLUDESTATUSCODES, --exclude-status=EXCLUDESTATUSCODES 排除状态代码,用逗号分隔(例如:301,500个)
--exclude-texts=EXCLUDETEXTS 用逗号分隔的文本排除响应(示例: "Not found", "Error")
--exclude-regexps=EXCLUDEREGEXPS 按regexp排除响应,用逗号分隔(示例:"Not foun[a-z]{1}", "^Error$")
-c COOKIE, --cookie=COOKIE
--ua=USERAGENT, --user-agent=USERAGENT 用户代理
-F, --follow-redirects --遵循重定向
-H HEADERS, --header=HEADERS 页眉,--页眉=页眉
要添加的标题 (example: --header "Referer:example.com" --header "User-Agent: IE")
--random-agents, --random-user-agents 随机代理,--随机用户代理连接设置:
--timeout=TIMEOUT 连接超时
--ip=IP 将名称解析为
2.使用方法
命令总结:python dirsearch.py -e php,txt,zip -u https://target //简单的查看网址目录和文件
python dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt //使用文件拓展名为php,txt,zip的字典扫描目标url
python dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --recursive -R 2python dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --recursive -R 4 --scan-subdirs=/,/wp-content/,/wp-admin/
python dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --exclude-texts=This,AndThat
python dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt -H "User-Agent: IE"
python dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt -t 20
python dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --random-agents
python dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --json-report=reports/target.json
python dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --simple-report=reports/target-paths.txtpython dirsearch.py -e php,txt,zip -u https://target -w db/dicc.txt --plain-text-report=reports/target-paths-and-status.js
个人常用命令:
python dirsearch.py -u http://xxxx //日常使用
python dirsearch.py -u http://xxxx -r //递归扫描,不过容易被检测
python dirsearch.py -u http://xxxx -r -t 30 //线程控制请求速率
python dirsearch.py -u http://xxxx -r -t 30 --proxy 127.0.0.1:8080 //使用代理以不同格式保存输出
dirsearch.py -u http://testphp.vulnweb.com/ --simple-report=report 我们可以清楚地看到,我们的简单格式结果已成功创建。 现在,我们可以轻松地分析我们的结果。以 JSON 格式保存输出
dirsearch.py -u http://testphp.vulnweb.com/ --json-report=report 同样,如上所述,我们使用 nano 命令开始分析我们的结果。以 XML 格式保存输出
dirsearch.py -u http://testphp.vulnweb.com/ --xml-report=report以 Markdown 格式保存输出
dirsearch.py -u http://testphp.vulnweb.com/ --markdown-report=report以 CSV 格式保存输出
dirsearch.py -u http://testphp.vulnweb.com/ --csv-report=report以普通格式保存输出
dirsearch.py -u http://testphp.vulnweb.com/ --plain-text-report=report递归扫描
通过使用 -r | --recursive 参数,dirsearch 将递归地强制所有目录。
python dirsearch.py -e php,html,js -u https://target -r 现在,在完成通常的扫描一段时间后,它将遍历每个子文件夹以进行递归扫描。 正如我们在此屏幕截图中清楚地看到的那样,它针对子文件夹并告诉我们我们的攻击未完成的工作。