lodge 学习
一、环境搭建 #数据下载 #lodge github https://github.com/li-ronghui/LODGE?tab=readme-ov-file # 训练数据集 放入 LODGE-main/data/finedance/ https://drive.google.com/file/d/1zQvWG9I0H4U3Zrm8d_QD_ehenZvqfQfS/view https://drive.google.com/drive/folders/1cdj8YymfN1BHgggVfGaLjaa9vaEpjPzZ?usp=sharing #预训练模型 LODGE-main/exp/ https://drive.google.com/file/d/13Yp__EPAw0EjrSS898X5FtSQGmveBykA/view
二、环境搭建 conda env create -f lodge.yaml # 修改 pip numba>=0.51.2 #numba==0.48.0 chumpy #chumpy==0.69 clip #clip==1.0 hydra-optuna-sweeper #hydra-optuna-sweeper==1.1.0.dev2 llvmlite>=0.41.0,<0.42 #llvmlite==0.31.0 删除 #torch-scatter==2.1.1 删除 #jukebox==1.0 删除 # torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 # 安装torch pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116 -i https://pypi.tuna.tsinghua.edu.cn/simple # 安装 jukebox git clone https://github.com/openai/jukebox.git cd jukebox pip install -r requirements.txt #numba==0.48.0 #llvmlite==0.31.0 pip install -e .‘ #torch-scatter==2.1.1 # 服务器cuda版本原因 安装失败 # 卸载当前NumPy版本 pip uninstall numpy # 安装指定版本的NumPy pip install numpy==1.22 -i https://pypi.tuna.tsinghua.edu.cn/simple # 手动下载 pytorch3d 根据torch版本 https://github.com/facebookresearch/pytorch3d/releases pip install pytorch3d.tar.gz #安装 opengl conda install -c conda-forge pyopengl pip install scipy # 推理命令 python infer_lodge.py --cfg exp/Local_Module/FineDance_FineTuneV2_Local/local_train.yaml --cfg_assets configs/data/assets.yaml --soft 1.0s
三、论文学习/原论文/翻译
论文标题:Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives:一个由特征舞蹈原语引导的粗到细的长舞蹈生成扩散网络
一、引言:现有的方法能生成几秒钟的舞蹈,本文采用了两阶段的粗到细扩散架构,并提出了具有显著表现力的特征舞蹈原语作为两个扩散模型之间的中间表示。我们的方法能够在平衡全局编舞模式和局部动作质量及表现力之间,平行生成极长的舞蹈序列。
二、摘要:本文lodge,能用音乐的全局特征生成极长舞蹈,用了2个edge模型,第一个全局模型识别n个动作(只识别音乐开头结尾及中间平均位置n个动作),第二个edge增加音乐风格信息并行识别,1-2、2-3、3-n的动作最后拼接,提出了一个优化足部与地面接触的模块。
三、介绍:任务目标:自动高效生成长、高保真、多样化的3d舞蹈动作,但是现有方法。不行(只能生成几秒,计算量太大,滑窗。缺点:没有全局舞蹈信息,速度慢,没有舞蹈类别信息),而本文模型用两阶段模型克服了这些问题,还提出了一种足部细化块
四、相关工作:人体运动合成:生成舞蹈动作很难、音乐驱动舞蹈:LSTM、Transformer、FACT用自回归方法误差累积和运动冻结、Bailando 使用vq-vae训练代码本缺少多样性,GAN 使用生成鉴别器模式崩溃、训练不稳定,EDGE和FineDance使用 扩散方法只关注一部分
五、方法:
1、音乐数据(finedance):(frame,35)

2、舞蹈数据(EDGE):(frame,139),smpl格式舞蹈数据、4=脚与地接触二进制标签、3=smpl根节点平移、132=1个全局旋转*6 + 21个子阶段旋转*6
3、模型使用 EDGE、DDPM
4、任务要求:
(1)音乐和舞蹈的整体体裁应该是一致的,传达相似的情绪和音调。
(2)音乐和舞蹈的节拍要尽可能一致。
(3)舞蹈的编排应与伴奏音乐的结构保持一致。例如,一个乐句中相同的拍子往往对应着对称的动作。
六、实验:使用finedance、aist++ 数据集测试、在FineDance数据集上的实验中,全局音乐特征长度N为1024,局部音乐特征长度n为256,全局扩散输出13个特征舞蹈基元,其中5个为dn,8个为d,编排增强操作后,d镜像产生16个实例,并与音乐的节拍对齐。全局扩散和局部扩散的优化器是Adan[51],我们使用指数移动平均(EMA)[20]策略,使损失收敛过程更加稳定。学习率为le-4。在推理阶段,我们有两种扩散采样策略DDPM[11]和DDIM[42],可以用来生成舞蹈。在AIST++数据集上,我们将舞蹈的采样降至30 fps用于训练。然后我们生成了30fps的舞蹈。最后,我们将输出的dance插值到60 fps,并按照Bai-lando[40]的实验设置进行测试。来自AIST++的音乐舞蹈数据被分割成许多短片段。因此,我们将全局音乐特征长度N更改为256,全局音乐特征长度N更改为128。
七、模型理解: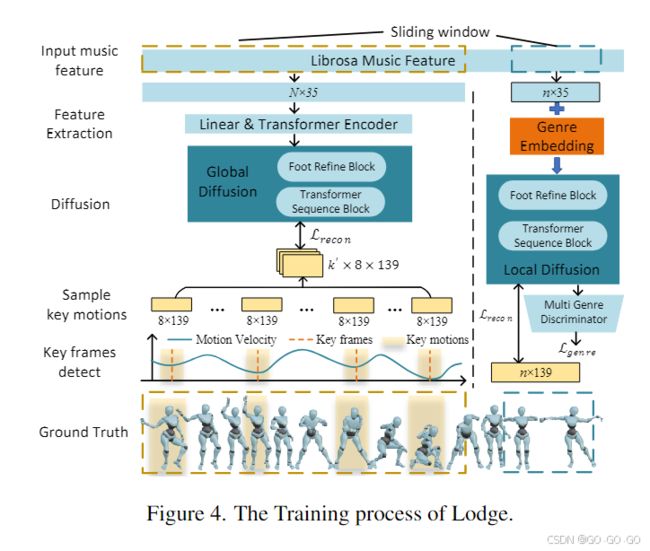
1、训练(上图)
1) Local Diffusion: 训练一个增加风格类型条件及足部接触模块的EDGE
(1)生成音乐特征(N,35) 动作特征(N,139)
实际数据维度:(batch,256(超参数),35)(batch,256(超参数),139)
(2)修改 EDGE 在输入条件中加入 音乐风格类型信息编码
(3)预测结果A + 预测结果A的足部接触模块预测结果B,A+B相加后最为最终输出结果
(4)训练完成后:改变输入 noise 的前后的4帧为真实动作,进行微调训练
2)Global Diffusion:训练一个 EDGE,只识别整段动作中部分动作
(1)生成音乐特征(N,35) 动作特征(N,139)
实际数据维度:(batch,1024(超参数),35)(batch,1024(超参数),139)
(2)修改动作特征:提取原动作特征的运动节拍,选取n(软) 个运动节拍前后各4帧动作特征和1024平均距离的m(硬)个前后个4帧动作及最前后8各帧作为标签,(batch,n+m+2*8,139)
(3)使用 EDGE 训练该数据
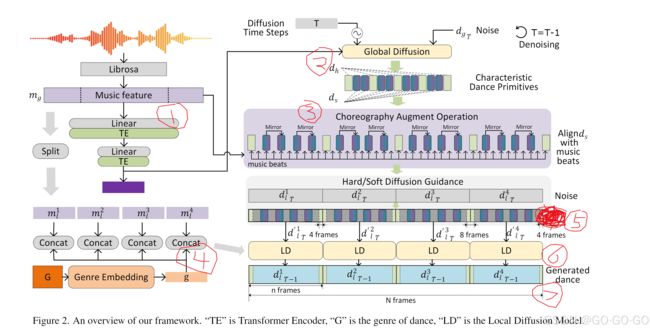
2、推理:(下图)
(1)生成音乐特征(N,35) -> (batch,1024,35)
(2)经过 Global Diffusion -> 生成舞蹈原语 (batch,n+2*8,139)稀疏动作数据
(3)镜像增强:对 ds 舞蹈动作进行左右镜像操作并加入对应节拍位置(手动固定的)、dh直接加入对应位置
(4)音乐特征(batch,1024,35) -> (batch*4,256,35)添加 T 及音乐风格类型信息编码
(5)把 dh 直接加入 noise 分别前后4帧里、把 ds 机器镜像操作加入对应位置
(6)经过 Local Diffusion -> 生成(batch*4,256,139)
(7)最后拼接 所有 batch*4 * 256 = 最终长度与音乐长度相同
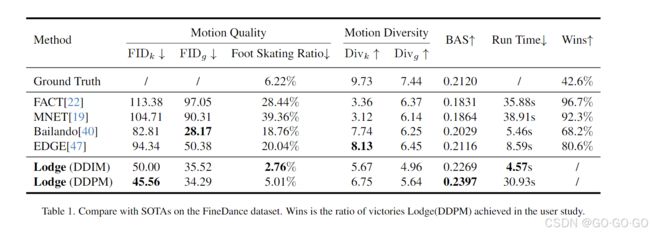
八、比较:
九、结论:本文lodge