informer+TCN+通道注意力机制+SSA时间序列模型预测
1.informer
Informer 是一种用于时间序列预测的深度学习模型,特别适用于长序列的时间序列数据。它是基于 Transformer 结构的一种改进,主要解决了传统 Transformer 在处理长序列时计算复杂度高的问题。
1.1Informer 的关键机制
-
稀疏自注意力机制(ProbSparse Attention):
- 传统的 Transformer 使用全局自注意力机制,即对于输入的每个时间步,它都计算与其他所有时间步的相似性。这种方法的计算复杂度是,当序列很长时,这种计算开销是巨大的。
- Informer 提出了稀疏自注意力机制,选择性地关注最重要的时间步,具体来说,它通过概率稀疏抽样方法,仅计算具有较大贡献的自注意力分数,减少了无用计算。
-
因子分解编码器(Distilling Operation):
- Informer 在编码器中引入了多层的因子分解模块,通过每层编码器对序列信息的稀疏化处理,逐步提取关键特征。这一机制能够显著减少冗余信息,进一步降低计算复杂度。
-
多头自回归生成(Autoformer-like Output Layer):
- 在解码器部分,Informer 借鉴了 Autoformer 的思想,通过多头自回归生成的方式,逐步预测未来的时间步。它在解码过程中利用先前预测的值来预测下一个时间步,从而逐步生成整个序列。
-
长尾预测能力:
- Informer 针对长尾分布的时间序列数据进行了优化,使得模型在处理分布不均衡的数据时表现更加稳定。通过稀疏机制和因子分解编码器,Informer 能够更好地捕捉到长尾分布中的关键特征。
1.2优势
Informer 的这些创新使得它在处理长序列时间序列数据时具有更高的效率和准确性。它适用于各种实际应用场景,如风电、光伏发电预测、股票市场分析、交通流量预测等。
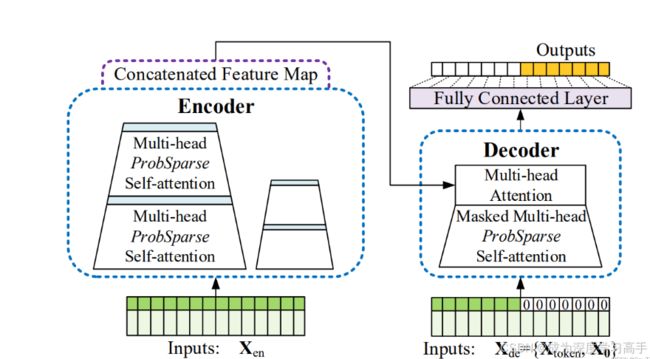
图1 informer结构图
2.TCN
TCN(Temporal Convolutional Network,时序卷积网络)是一种用于处理时间序列数据的深度学习模型。它主要基于卷积神经网络(CNN),但在结构上进行了调整,以适应时间序列的特性。TCN 的设计目标是替代循环神经网络(RNN)在时间序列建模中的作用,特别是长依赖关系的建模。
2.1TCN 的关键机制
-
一维卷积(1D Convolutions)
- TCN 使用一维卷积来处理时间序列数据。与传统 CNN 不同,TCN 的卷积核在时间维度上滑动,从而在不改变输入长度的情况下提取特征。
-
因果卷积(Causal Convolutions)
- 为了确保模型只利用当前及之前的时间步信息,而不会泄露未来的信息,TCN 使用因果卷积。具体来说,因果卷积保证输出序列中时间步 ttt 仅依赖于输入序列中时间步 ttt 及之前的值,避免了信息“穿越”。
-
膨胀卷积(Dilated Convolutions):
- TCN 采用膨胀卷积(也称为扩张卷积),使得卷积核可以在更长的时间范围内捕捉依赖关系,而不需要增加计算量。膨胀卷积通过在卷积核之间插入间隔,从而扩展感受野。例如,当膨胀因子为 2 时,卷积核在时间步 1、3、5 等位置上采样,而不是连续的 1、2、3。
-
残差连接(Residual Connections):
- 为了构建更深的网络并减轻梯度消失的问题,TCN 引入了残差连接。残差连接允许跳过某些层,将输入直接传递到更深的层次,保留信息的同时促进梯度传播。
-
完全卷积网络(Fully Convolutional Network):
- TCN 是一个完全卷积网络,即没有使用池化层。它通过卷积层的堆叠和膨胀因子的变化,逐渐增加感受野,最终覆盖整个输入序列。因此,TCN 的输出序列长度与输入序列长度相同,这非常适合时间序列任务中的需求。
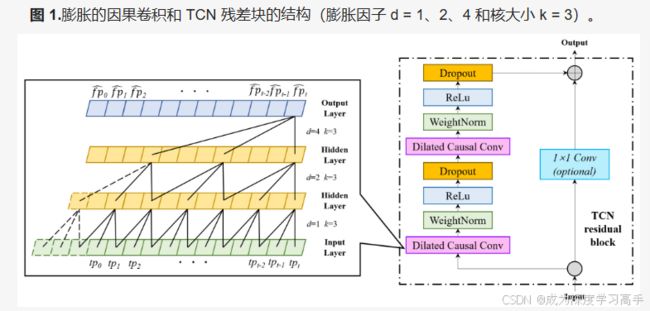
图2 TCN结构图
3.SSA麻雀优化算法
SSA麻雀优化算法(Sparrow Search Algorithm,简称 SSA)是一种新兴的群体智能优化算法,它模仿麻雀群体觅食行为来解决优化问题。SSA 在寻找全局最优解时展现出良好的性能和稳定性,适用于各种复杂的优化问题。SSA 麻雀优化算法的核心思想是通过模拟麻雀的觅食策略、反捕猎行为等特性,达到全局搜索和局部搜索的平衡。
3.1SSA 机制详解
-
种群初始化:
- 在 SSA 中,初始种群由一组随机生成的麻雀个体组成,每个个体代表一个可能的解。个体的位置对应问题的解空间中的一个点。通常,种群大小固定,并根据问题的维度进行初始化。
-
麻雀的角色划分:
- SSA 中的麻雀被分为发现者(Producers)和追随者(Scroungers),这两类角色通过不同的策略进行搜索。
- 发现者:负责寻找食物的最佳区域(全局搜索),并引导群体。发现者一般占据种群中的一部分。
- 追随者:跟随发现者进行食物搜索(局部搜索),通常是通过模仿发现者的行为来进行位置更新。
- SSA 中的麻雀被分为发现者(Producers)和追随者(Scroungers),这两类角色通过不同的策略进行搜索。
-
发现者更新策略
-
追随者更新策略
-
反捕猎机制:
- 麻雀在觅食时会保持警觉,SSA 通过引入反捕猎机制,模拟麻雀在受到威胁时的逃逸行为,增强算法的跳出局部最优的能力。具体来说,当麻雀感受到危险(即解陷入局部最优时),个体位置会进行大范围的跳跃更新。
-
适应度评估:
- 每一代中,SSA 都会对种群中的每个麻雀个体进行适应度评估,以确定哪个个体处在当前代的最优位置。适应度值用于指导个体的后续行为。
4.TCN+SSA+informer时间序列模型
1.模型
- TCN:利用膨胀卷积和残差连接,TCN 在捕捉长时间依赖关系方面表现出色。它能有效处理长序列数据,同时保持计算效率。
- Informer:Informer 专门针对长序列的稀疏性进行了优化,通过稀疏自注意力机制(ProbSparse Attention)和因子分解编码器,Informer 能在处理高维度、长序列数据时保持高效。
- SSA:SSA 是一种强大的全局优化算法,可以帮助优化模型的超参数或初始化,从而提高整体预测精度。SSA 的反捕猎机制还能帮助模型跳出局部最优陷阱。
通过将 TCN、Informer 和 SSA 结合,可以充分发挥每种方法的优势,实现全局和局部的优化和预测,从而提高时间序列预测的精度和稳定性。
2. 提升预测精度
- 全局优化能力:SSA 的全局搜索能力可以在模型的超参数调整过程中,帮助找到更优的参数设置,进而提高 TCN 和 Informer 的预测性能。
- 长序列处理能力:TCN 和 Informer 都擅长处理长序列数据,TCN 通过卷积操作处理局部依赖性,而 Informer 通过稀疏注意力机制捕捉全局依赖性,二者结合能够在风电和光伏等复杂时间序列中捕捉到更细腻的时序特征。
3. 模型训练效率
- 高效的时间复杂度:Informer 在处理长时间序列数据时,采用稀疏自注意力机制降低了计算复杂度,提升了模型的训练效率。SSA 可以通过减少不必要的计算(如跳过次优解),优化训练过程。
- 并行化处理:TCN 的卷积结构和 SSA 的种群搜索机制都可以很好地支持并行化处理,减少模型训练和预测所需的时间。
4. 适应性强
- 多样化特征处理:风电和光伏领域的时间序列数据往往具有多样化的特征(如温度、湿度、日照强度等),TCN 和 Informer 可以结合处理这些多维度特征,并通过 SSA 的优化进一步提高处理效果。
- 长尾数据的稳健性:在风电和光伏时间序列数据中,可能会出现一些异常或长尾分布的数据。Informer 对于处理长尾数据有独特的优势,能够提高预测模型的鲁棒性。
5.实验结果
5.1代码主模块
class Model(nn.Module):
def __init__(self, configs):
super(Model, self).__init__()
self.task_name = configs.task_name
self.pred_len = configs.pred_len
self.label_len = configs.label_len
self.lstm =TCN(input_size=configs.enc_in, hidden_size=configs.d_model, num_layers=3,
batch_size=configs.batch_size)
#self.icb = ICB(configs.num_features, configs.d_model)
#self.abs = Adaptive_Spectral_Block(configs.num_features)
# Embedding
self.enc_embedding = DataEmbedding(configs.enc_in, configs.d_model, configs.embed, configs.freq,
configs.dropout)
self.dec_embedding = DataEmbedding(configs.dec_in, configs.d_model, configs.embed, configs.freq,
configs.dropout)
# Encoder
self.encoder = Encoder(
[
EncoderLayer(
AttentionLayer(
ProbAttention(False, configs.factor, attention_dropout=configs.dropout,
output_attention=configs.output_attention),
configs.d_model, configs.n_heads),
configs.d_model,
configs.d_ff,
dropout=configs.dropout,
activation=configs.activation
) for l in range(configs.e_layers)
],
[
ConvLayer(configs.d_model) for l in range(configs.e_layers - 1)
] if configs.distil and ('forecast' in configs.task_name) else None,
norm_layer=torch.nn.LayerNorm(configs.d_model)
)
# Decoder
self.decoder = Decoder(
[
DecoderLayer(
AttentionLayer(
ProbAttention(True, configs.factor, attention_dropout=configs.dropout, output_attention=False),
configs.d_model, configs.n_heads),
AttentionLayer(
ProbAttention(False, configs.factor, attention_dropout=configs.dropout, output_attention=False),
configs.d_model, configs.n_heads),
configs.d_model,
configs.d_ff,
dropout=configs.dropout,
activation=configs.activation,
) for l in range(configs.d_layers)
],
norm_layer=torch.nn.LayerNorm(configs.d_model),
projection=nn.Linear(configs.d_model, configs.c_out, bias=True)
)
if self.task_name in ['imputation', 'anomaly_detection']:
self.projection = nn.Linear(configs.d_model, configs.c_out, bias=True)
if self.task_name == 'classification':
self.act = F.gelu
self.dropout = nn.Dropout(configs.dropout)
self.projection = nn.Linear(configs.d_model * configs.seq_len, configs.num_class)5.2模型训练
# # 数据归一化
scaler = MinMaxScaler()
data_inverse = scaler.fit_transform(np.array(data))
data_length = len(data_inverse)
train_set = 0.8
data_train = data_inverse[:int(train_set * data_length), :] # 读取目标数据,第一列记为0:1,后面以此类推, 训练集和验证集,如果是多维输入的话最后一列为目标列数据
data_train_mark = data_stamp[:int(train_set * data_length), :]
data_test = data_inverse[int(train_set * data_length):, :] # 这里把训练集和测试集分开了,也可以换成两个csv文件
data_test_mark = data_stamp[int(train_set * data_length):, :]
n_feature = data_dim
window = 10 # 模型输入序列长度
length_size = 1 # 预测结果的序列长度
batch_size = 50
train_loader, x_train, y_train, x_train_mark, y_train_mark = tslib_data_loader(window, length_size, batch_size, data_train, data_train_mark)
test_loader, x_test, y_test, x_test_mark, y_test_mark = tslib_data_loader(window, length_size, batch_size, data_test, data_test_mark)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
num_epochs = 50 # 训练迭代次数
learning_rate = 0.001 # 学习率
scheduler_patience = int(0.25 * num_epochs) # 转换为整数 学习率调整的patience
early_patience = 0.2 # 训练迭代的早停比例 即patience=0.25*num_epochs
class Config:
def __init__(self):
# basic
self.seq_len = window # input sequence length
self.label_len = int(window / 2) # start token length
self.pred_len = length_size # 预测序列长度
self.freq = 't' # 时间的频率,
# 模型训练
self.batch_size = batch_size # 批次大小
self.num_epochs = num_epochs # 训练的轮数
self.learning_rate = learning_rate # 学习率
self.stop_ratio = early_patience # 早停的比例
# 模型 define
self.dec_in = data_dim # 解码器输入特征数量, 输入几个变量就是几
self.enc_in = data_dim # 编码器输入特征数量
self.c_out = 1 # 输出维度##########这个很重要
# 模型超参数
self.d_model = 64 # 模型维度
self.n_heads = 8 # 多头注意力头数
self.dropout = 0.1 # 丢弃率
self.e_layers = 2 # 编码器块的数量
self.d_layers = 1 # 解码器块的数量
self.d_ff = 64 # 全连接网络维度
self.factor = 5 # 注意力因子
self.activation = 'gelu' # 激活函数
self.channel_independence = 0 # 频道独立性,0:频道依赖,1:频道独立
self.top_k = 6 # TimesBlock中的参数
self.num_kernels = 6 # Inception中的参数
self.distil = 1 # 是否使用蒸馏,1为True
# 一般不需要动的参数
self.embed = 'timeF' # 时间特征编码方式
self.output_attention = 0 # 是否输出注意力
self.task_name = 'short_term_forecast' # 模型的任务,一般不动但是必须这个参数5.3数据集
数据集类似顶刊ETTH的格式即可。
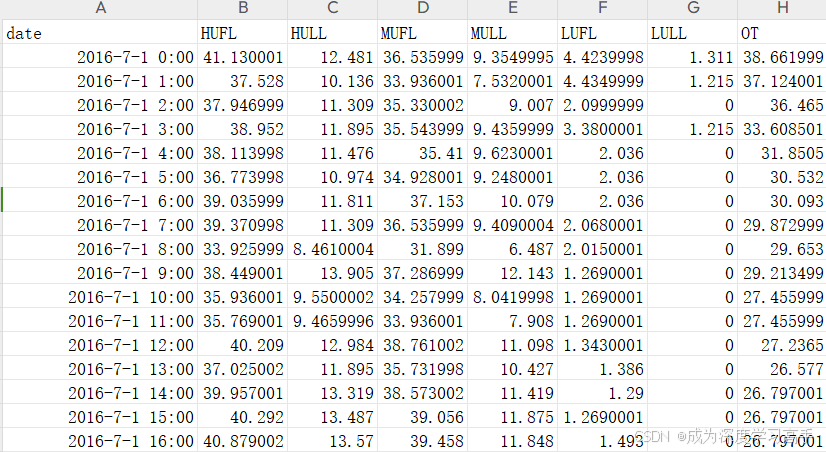
图3 数据集
5.4实验结果
实验结果拟合效果还是不错的。
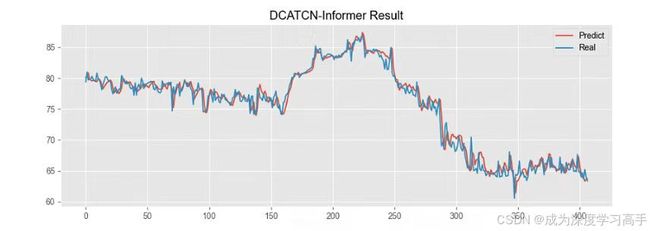
图4 实验结果
6.代码功能
代码适合功率预测,风电光伏预测,负荷预测,流量预测,浓度预测,机械领域预测等等各种时间序直接预测。
1.多变量输入,单变量输出/可改多输出
2.多时间步预测,单时间步预测
3.评价指标:R方 RMSE MAE MAPE
对比图
4.数据从excel/csv文件中读取,直接替换即可。
5.结果保存到文本中,可以后续处理。
代码源码以及具体详细介绍
https://www.bilibili.com/video/BV1r3eMeTEvL/?spm_id_from=333.999.0.0