scrapy框架--快速了解
免责声明:本文仅做分享~
目录
介绍:
5大核心组件:
安装scrapy:
创建到启动:
修改日志配置:settings.py
修改君子协议配置:
伪装浏览器头:
让代码去终端执行:
数据保存:
1-基于命令
2-基于管道
文档:
介绍:
5大核心组件:
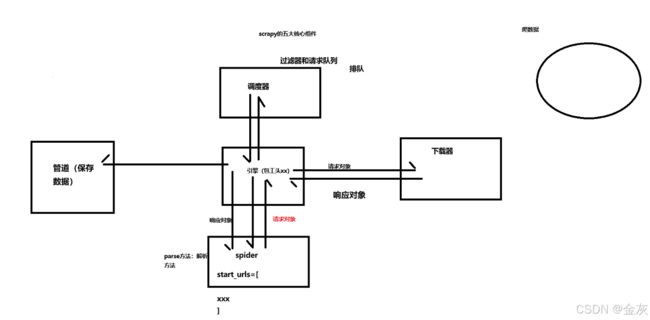
Scrapy是一个开源的Python框架,用于抓取网站数据并进行数据处理。Scrapy是一个快速、高效的框架,可以用来构建快速、可扩展的爬虫。Scrapy框架的主要组件包括:
1-引擎:Scrapy引擎负责处理数据流,包括调度、下载、解析、存储等。(包工头,大心脏)
2-调度器:Scrapy调度器负责管理URL请求,并将请求发送给下载器。
--过滤器和请求队列
3-spider:Spider是爬虫的主要组件,负责解析网页并提取数据。
parse()方法:用于解析网页并提取数据。
4-下载器:下载器负责下载网页并返回响应。
5-管道:管道是Scrapy框架的核心组件之一,负责处理爬取到的数据。(保存数据,数据清洗,数据分析)
引擎--spider--调度器--下载器--引擎--管道
安装scrapy:
pip install scrapy
因为scrapy是异步框架,为什么是异步框架,是因为用了Twisted
pip install scrapy #默认安装最新版本的Scrapy
Twisted是一个Python网络框架,Scrapy使用Twisted来实现网络通信。异步IO的实现。
注意兼容问题.
Twisted 22.10.0
如果使用scrapy2.9.0 Twisted-23.8.0 会有兼容问题
需要手动降版本
先卸载 pip uninstall Twisted
再安装 pip install Twisted==22.10.0
创建到启动:
1-创建scrapy项目:
scrapy startproject 项目名称
scrapy startproject scrapy_demo1
2-进入项目目录:
cd scrapy_demo1
3-scrapy genspider 爬虫名称 域名
scrapy genspider baidu baidu.com
4-启动项目:
scrapy crawl 爬虫名
scrapy crawl baidu修改日志配置:settings.py
#启动--发现打印了一些信息,调用,响应看
--设置日志输出的级别.
# 设置日志输出的级别:出现错误才输出.
LOG_LEVEL = "ERROR"

修改君子协议配置:
当pa百度的时候,发现返回不了数据,---因为百度有robots.txt 协议 -- 默认是遵守.
# 君子协议
ROBOTSTXT_OBEY = False
--我们不遵守.

伪装浏览器头:
伪装一下下,要不然明牌打.
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"

让代码去终端执行:
# xxx.py 放在项目的spider文件夹下
from scrapy.cmdline import execute
execute(["scrapy","crawl", "爬虫名"])数据保存:
1-基于命令
简单 -- 把所有数据return给parse()方法,然后执行命令.
缺点:有固定的格式:'json', 'jsonlines', 'jsonl', 'jl', 'csv', 'xml', 'marshal', 'pickle'
需要把parse()方法返回的数据保存到文件中: [{},{},{}]
scrapy crawl blibli -o blibli.txt # 不行,会报错.
scrapy crawl blibli -o blibli.csv
--本地打开乱码就另存为.(编码问题)2-基于管道
复杂
1-在爬虫文件中进行数据解析
2-在items.py定义相关属性(你要保存什么数据,就定于什么属性.)
3-在 爬虫文件中 把 解析的数据存储封装到item类型对象中
4-把item类型对象提交给管道
5-在管道文件中,接收爬虫文件提交过来的item类型对象
6-配置文件中开启管道
(默认的类只针对保存到txt里面.) Excel / 数据库文档:
