Redis进阶: 锁的使用
Redis进阶: 锁的使用
- 1. 概念
-
- 1. 原子性
- 2. 事务
- 2. 使用Redis构建全局并发锁
- 3. Redlock(redis分布式锁)
-
- 总结
- 相关Blog
1. 概念
1. 原子性
原子性
原子性是数据库的事务中的特性。在数据库事务的情景下,原子性指的是:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。
对于Redis而言,命令的原子性指的是:一个操作的不可以再分,操作要么执行,要么不执行。
Redis操作原子性的原因
Redis的操作之所以是原子性的,是因为Redis是单线程的。
进程与线程
- 进程
计算机中已执行程序的实体。比如,一个启动了的php-fpm,就是一个进程。 - 线程
操作系统能够进行运算调度的最小单元。它被包含在进程之中,是进程的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。比如,mysql运行时,mysql启动后,该mysql服务就是一个进程,而mysql的连接、查询的操作,就是线程。
进程与线程的区别
- 资源(如打开文件):进程间的资源相互独立,同一进程的各线程间共享资源。某进程的线程在其他进程不可见。
- 通信:进程间通信:消息传递、同步、共享内存、远程过程调用、管道。线程间通信:直接读写进程数据段(需要进程同步和互斥手段的辅助,以保证数据的一致性)。
- 调度和切换:线程上下文切换比进程上下文切换要快得多。
线程,是操作系统最小的执行单元,在单线程程序中,任务一个一个地做,必须做完一个任务后,才会去做另一个任务。
Redis在并发中的表现
Redis的API是原子性的操作,那么多个命令在并发中也是原子性的吗?
看看下面这段代码:
$redis= newRedis();
$redis->connect('127.0.0.1',6379);
for($i= 0;$iget('val');
$num++;
$redis->set('val',$num);
usleep(10000);
}
用两个终端执行上面的程序,发现val的结果是小于2000的值,那么可以知道,在程序中执行多个Redis命令并非是原子性的,这也和普通数据库的表现是一样的。
如果想在上面的程序中实现原子性,可以将get和set改成单命令操作,比如incr,或者使用Redis的事务,或者使用Redis+Lua的方式实现。
原子性总结
综上所述,对Redis来说,执行get、set以及eval等API,都是一个一个的任务,这些任务都会由Redis的线程去负责执行,任务要么执行成功,要么执行失败,这就是Redis的命令是原子性的原因。
Redis本身提供的所有API都是原子操作,Redis中的事务其实是要保证批量操作的原子性。
2. 事务
MULTI 、 EXEC 、 DISCARD 和 WATCH 是 Redis 事务相关的命令。事务可以一次执行多个命令, 并且带有以下两个重要的保证:
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
事务的关键字
- EXEC 命令负责触发并执行事务中的所有命令:
如果客户端在使用 MULTI 开启了一个事务之后,却因为断线而没有成功执行 EXEC ,那么事务中的所有命令都不会被执行。 - 另一方面,如果客户端成功在开启事务之后执行 EXEC ,那么事务中的所有命令都会被执行。
当使用 AOF 方式做持久化的时候, Redis 会使用单个 write(2) 命令将事务写入到磁盘中。
然而,如果 Redis 服务器因为某些原因被管理员杀死,或者遇上某种硬件故障,那么可能只有部分事务命令会被成功写入到磁盘中。
如果 Redis 在重新启动时发现 AOF 文件出了这样的问题,那么它会退出,并汇报一个错误。
使用redis-check-aof程序可以修复这一问题:它会移除 AOF 文件中不完整事务的信息,确保服务器可以顺利启动。
从 2.2 版本开始,Redis 还可以通过乐观锁(optimistic lock)实现 CAS (check-and-set)操作,具体信息请参考文档的后半部分。
事务的语句
> MULTI
OK
> INCR foo
QUEUED
> INCR bar
QUEUED
> EXEC
1) (integer) 1
2) (integer) 1
为什么 Redis 不支持回滚(roll back)
如果你有使用关系式数据库的经验, 那么 “Redis 在事务失败时不进行回滚,而是继续执行余下的命令”这种做法可能会让你觉得有点奇怪。
以下是这种做法的优点:
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
2. 使用Redis构建全局并发锁
谈起Redis的用途,小伙伴们都会说使用它作为缓存,目前很多公司都用Redis作为缓存,但是使用Redis仅仅作为缓存未免太大材小用了。深究Redis的原理后你会发现它有很多用途,在很多场景下能够使用它快速地解决问题。常见的用途有:分布式锁控制并发、结合bloom filter用于推荐去重、HyperLogLog用于统计UV、限流控制流量等等;这里我谈下Redis分布式锁控制并发的问题。
Redis分布式锁控制并发主要是通过在Redis里面创建一个key,当其它进程准备占用的时候只能等待key释放再占用。Redis里面有一个原子性指令setnx,当key存在时,它返回0,表示当前已有进程占用,当它返回1时可以执行业务逻辑,此时没有进程占用,等逻辑执行完后,可以删除key释放锁,这样可以简单的控制并发。
127.0.0.1:6379> setnx copy_question 11
(integer) 1
127.0.0.1:6379> setnx copy_question 11
(integer) 0
在业务逻辑执行的过程中如果发生异常,此时key并没有删除,这样就会造成死锁,死锁带来的后果想必大家都很清楚。为了解决这个问题,可以在setnx加锁后设置key的过期时间,当key到期自动删除。
127.0.0.1:6379> expire copy_question l0
(integer) 1
但是仔细想想你还会发现,如果在执行setnx后,执行expire前Redis发生宕机了,这样就不会执行expire,也会造成死锁。由于setnx与expire是两条命令,并且expire依赖setnx的执行结果,为了解决这个问题可以使用set key value [expiration EX seconds|PX milliseconds] [NX|XX] ,这是一条原子性的指令,同时包含setnx和expire。
127.0.0.1:6379> set copy_question l11 ex 10 nx
OK
127.0.0.1:6379> set copy_question l11 ex 10 nx
(nil)
使用python实现的代码:
class RedisLock(object):
"""
踩坑 Redis并发锁
"""
def __init__(self, key):
self.redis_conn = get_redis_conn()
self.lock_key = "{}_redis_gil".format(key)
@staticmethod
def get_lock_value(cls):
"""
获取value
:param cls:
:return:
"""
cls.get_lok = cls.redis_conn.get(cls.lock_key)
return cls.get_lok
@staticmethod
def set_lock(cls, random_value):
"""
不能使用setnx 没有设置过期时间,可能会出现死锁
引入random_value :自己加的锁只能自己释放
:param cls:
:param random_value:
:return:
"""
cls._lock = cls.redis_conn.set(cls.lock_key, random_value, nx=True, ex=5)
# 如果返回null 表示key存在存在并发
if cls._lock:
return True
else:
LOGGER = logging.getLogger('core.utils')
LOGGER.warning(u"试题复制存在并发")
raise RsError("试题复制存在并发,请稍后再试")
@staticmethod
def release(cls):
"""
释放锁
:param cls:
:return:
"""
cls.redis_conn.delete(cls.lock_key)
@staticmethod
def redis_lock(cls):
"""
只有当设置的value与do_something执行完后所获取的值相同时才删除key
防止在分布式中: clientA由于执行时间过期(clientA的执行时间比设置的过期时间大),clientB获取锁,
clientA执行完后释放锁(删除key),其实这时候删除的是B的key,
为防止这种情况引入random_value 只有当前值为random_value时才删除
:param cls:
:return:
"""
random_value = time.time()
if cls.set_lock(cls, random_value):
do_something()
now_value = cls.get_lock_value(cls)
if now_value == random_value:
cls.release()
return True
else:
return False
def do_something():
pass
在实际业务中调用Redis全局锁,进行加锁示例:
# 公库试题复制到平台考虑并发问题,加锁处理
if self.visible_scope == 10:
key = hash(self.question_id)
cls = RedisLock(key)
cls.redis_lock(cls)
try:
self.insert_question()
except Exception:
raise RsError("试题插入失败")
finally:
cls.release(cls)
如果是Redis集群下此方法可能仍然有问题,试想下:在一个redis集群中,主节点由于某种原因挂掉了,从节点变成了主节点,而此时redis锁还未同步到原从节点中,那么这个锁也就失效了,当其它进程申请锁时仍然可以申请成功。
针对这个问题,新版的redis引入了redlock,通过redlock.Redlock对多个redis节点进行加锁,当超过一半的节点加锁成功时锁才生效。这样在一定程度上提高了高可用性,但由于每次加锁和释放锁要对多个节点进行读写,所以性能上肯定是没有单节点锁高的。
3. Redlock(redis分布式锁)
**Redlock:**全名叫做 Redis Distributed Lock;即使用redis实现的分布式锁;
使用场景:多个服务间保证同一时刻同一时间段内同一用户只能有一个请求(防止关键业务出现并发攻击);
官网文档地址如下:https://redis.io/topics/distlock
这个锁的算法实现了多redis实例的情况,相对于单redis节点来说,优点在于 防止了 单节点故障造成整个服务停止运行的情况;并且在多节点中锁的设计,及多节点同时崩溃等各种意外情况有自己独特的设计方法;
此博客或者官方文档的相关概念:
-
1.TTL:Time To Live;只 redis key 的过期时间或有效生存时间
-
2.clock drift:时钟漂移;指两个电脑间时间流速基本相同的情况下,两个电脑(或两个进程间)时间的差值;如果电脑距离过远会造成时钟漂移值 过大
最低保证分布式锁的有效性及安全性的要求如下:
-
1.互斥;任何时刻只能有一个client获取锁
-
2.释放死锁;即使锁定资源的服务崩溃或者分区,仍然能释放锁
-
3.容错性;只要多数redis节点(一半以上)在使用,client就可以获取和释放锁
网上讲的基于故障转移实现的redis主从无法真正实现Redlock:
- 因为redis在进行主从复制时是异步完成的,比如在clientA获取锁后,主redis复制数据到从redis过程中崩溃了,导致没有复制到从redis中,然后从redis选举出一个升级为主redis,造成新的主redis没有clientA 设置的锁,这是clientB尝试获取锁,并且能够成功获取锁,导致互斥失效;
思考题:这个失败的原因是因为从redis立刻升级为主redis,如果能够过TTL时间再升级为主redis(延迟升级)后,或者立刻升级为主redis但是过TTL的时间后再执行获取锁的任务,就能成功产生互斥效果;是不是这样就能实现基于redis主从的Redlock;
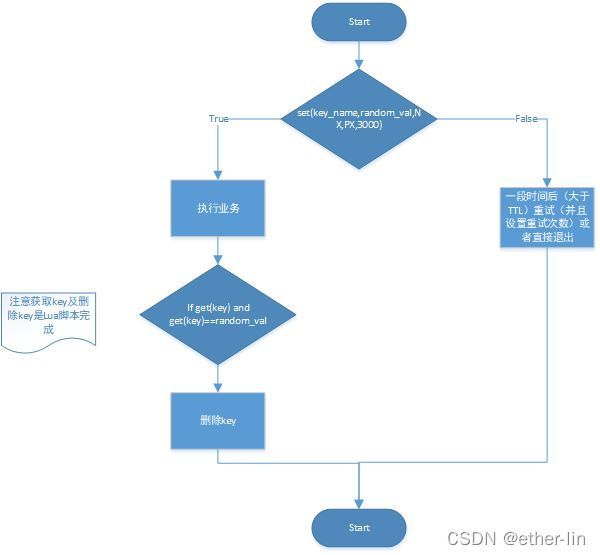
redis单实例中实现分布式锁的正确方式(原子性非常重要):
- 1.设置锁时,使用set命令,因为其包含了setnx,expire的功能,起到了原子操作的效果,给key设置随机值,并且只有在key不存在时才设置成功返回True,并且设置key的过期时间(最好用毫秒)
SET key_name my_random_value NX PX 30000 -- NX 表示if not exist 就设置并返回True,否则不设置并返回False PX 表示过期时间用毫秒级, 30000 表示这些毫秒时间后此key过期
2.在获取锁后,并完成相关业务后,需要删除自己设置的锁(必须是只能删除自己设置的锁,不能删除他人设置的锁);
-
删除原因:保证服务器资源的高利用效率,不用等到锁自动过期才删除;
-
删除方法:最好使用Lua脚本删除(redis保证执行此脚本时不执行其他操作,保证操作的原子性),代码如下;逻辑是 先获取key,如果存在并且值是自己设置的就删除此key;否则就跳过;
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
算法流程图如下:
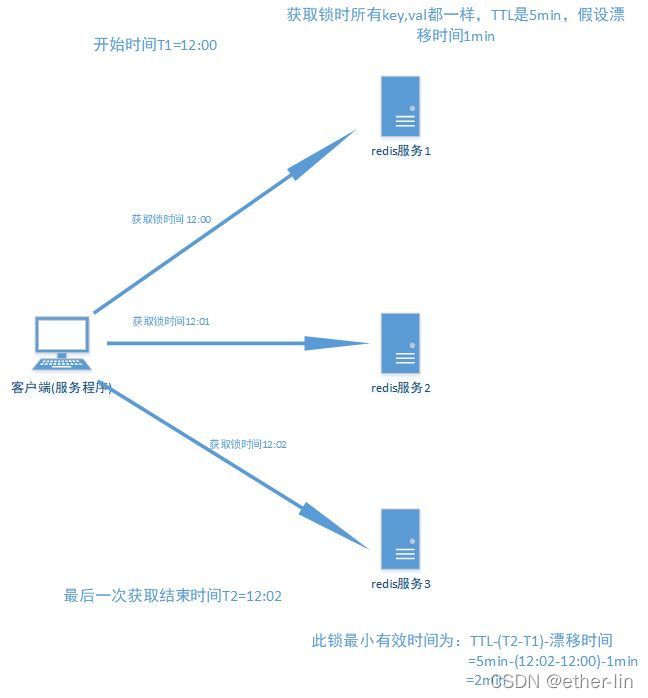
多节点redis实现的分布式锁算法(RedLock):有效防止单点故障
假设有5个完全独立的redis主服务器
-
1.获取当前时间戳
-
2.client尝试按照顺序使用相同的key,value获取所有redis服务的锁,在获取锁的过程中的获取时间比锁过期时间短很多,这是为了不要过长时间等待已经关闭的redis服务。并且试着获取下一个redis实例。
比如:TTL为5s,设置获取锁最多用1s,所以如果一秒内无法获取锁,就放弃获取这个锁,从而尝试获取下个锁 -
3.client通过获取所有能获取的锁后的时间减去第一步的时间,这个时间差要小于TTL时间并且至少有3个redis实例成功获取锁,才算真正的获取锁成功
-
4.如果成功获取锁,则锁的真正有效时间是 TTL减去第三步的时间差 的时间;比如:TTL 是5s,获取所有锁用了2s,则真正锁有效时间为3s(其实应该再减去时钟漂移);
-
5.如果客户端由于某些原因获取锁失败,便会开始解锁所有redis实例;因为可能已经获取了小于3个锁,必须释放,否则影响其他client获取锁
算法示意图如下:
RedLock算法是否是异步算法??
可以看成是同步算法;因为 即使进程间(多个电脑间)没有同步时钟,但是每个进程时间流速大致相同;并且时钟漂移相对于TTL叫小,可以忽略,所以可以看成同步算法;(不够严谨,算法上要算上时钟漂移,因为如果两个电脑在地球两端,则时钟漂移非常大)
RedLock失败重试
当client不能获取锁时,应该在随机时间后重试获取锁;并且最好在同一时刻并发的把set命令发送给所有redis实例;而且对于已经获取锁的client在完成任务后要及时释放锁,这是为了节省时间;
RedLock释放锁
由于释放锁时会判断这个锁的value是不是自己设置的,如果是才删除;所以在释放锁时非常简单,只要向所有实例都发出释放锁的命令,不用考虑能否成功释放锁;
RedLock注意点(Safety arguments):
-
1.先假设client获取所有实例,所有实例包含相同的key和过期时间(TTL) ,但每个实例set命令时间不同导致不能同时过期,第一个set命令之前是T1,最后一个set命令后为T2,则此client有效获取锁的最小时间为TTL-(T2-T1)-时钟漂移;
-
2.对于以N/2+ 1(也就是一半以 上)的方式判断获取锁成功,是因为如果小于一半判断为成功的话,有可能出现多个client都成功获取锁的情况, 从而使锁失效
-
3.一个client锁定大多数事例耗费的时间大于或接近锁的过期时间,就认为锁无效,并且解锁这个redis实例(不执行业务) ;只要在TTL时间内成功获取一半以上的锁便是有效锁;否则无效
系统有活性的三个特征:
-
1.能够自动释放锁
-
2.在获取锁失败(不到一半以上),或任务完成后 能够自动释放锁,不用等到其自动过期
-
3.在client重试获取哦锁前(第一次失败到第二次重试时间间隔)大于第一次获取锁消耗的时间;
-
4.重试获取锁要有一定次数限制
RedLock性能及崩溃恢复的相关解决方法:
-
1.如果redis没有持久化功能,在clientA获取锁成功后,所有redis重启,clientB能够再次获取到锁,这样违法了锁的排他互斥性;
-
2.如果启动AOF永久化存储,事情会好些, 举例:当我们重启redis后,由于redis过期机制是按照unix时间戳走的,所以在重启后,然后会按照规定的时间过期,不影响业务;但是由于AOF同步到磁盘的方式默认是每秒-次,如果在一秒内断电,会导致数据丢失,立即重启会造成锁互斥性失效;但如果同步磁盘方式使用Always(每一个写命令都同步到硬盘)造成性能急剧下降;所以在锁完全有效性和性能方面要有所取舍;
-
3.有效解决既保证锁完全有效性及性能高效及即使断电情况的方法是redis同步到磁盘方式保持默认的每秒,在redis无论因为什么原因停掉后要等待TTL时间后再重启(学名:延迟重启) ;缺点是 在TTL时间内服务相当于暂停状态;
总结
-
1.TTL时长 要大于正常业务执行的时间+获取所有redis服务消耗时间+时钟漂移
-
2.获取redis所有服务消耗时间要 远小于TTL时间,并且获取成功的锁个数要 在总数的一般以上:N/2+1
-
3.尝试获取每个redis实例锁时的时间要 远小于TTL时间
-
4.尝试获取所有锁失败后 重新尝试一定要有一定次数限制
-
5.在redis崩溃后(无论一个还是所有),要延迟TTL时间重启redis
-
6.在实现多redis节点时要结合单节点分布式锁算法 共同实现
相关Blog
Redis原子性
Redis构建全局并发锁
Redlock(redis分布式锁)原理分析