遥感之机器学习树集成模型-CART算法之回归
本文在前面文章的基础上,连续介绍CART树在回归中的应用,其回归技术经常用于定量遥感领域,涉及各种地表参数含量的反演。
主要分为如下几部分:
- 回归概念描述
- 回归树中数据集的划分准则
- CART回归树的原理和流程
- CART回归树的核心代码
前面内容可参考:
遥感之机器学习树模型专栏
1 回归概念
机器学习中的回归建模以及相应的回归算法,在遥感领域对应的就是定量遥感分方向,比如水质参数反演,土壤中各种参数反演,森林各种生物量反演等等。都属于回归的范畴。
简而言之,回归分析是一套用于估计因变量(通常称为“结果变量”)和一个或多个独立变量(通常称为“预测因子”“协变量”或“特征”)之间关系的统计过程。回归算法属于有监督机器学习算法家族。有监督机器学习算法的主要特点之一是对目标输出和输入特征之间的依赖性和关系进行建模,以预测新输入数据的输出数值。回归算法根据系统中输入数据的属性特征来预测输出值。
常用的回归方法可参考以前的文章,其方法主要有:一元线性回归,多元线性回归,逐步回归等。
遥感反演常用的回归方法
这里主要关注回归树:
回归树(regression tree),顾名思义,就是用树模型做回归问题,每一个叶子节点都输出一个预测值。
预测值一般是该叶子节点所含训练集样本的输出的均值,决策树也可以应用于回归问题。
CART算法是第一个同时支持分类和回归的决策树算法。在分类问题中,CART使用基尼指数或基尼增益作为选择特征及其分割点的依据;在回归问题中,CART使用均方误差或者平均绝对误差作为选择特征及其分割点的依据。
除了CART算法外,随机森林、GBDT、XGBoost、LightGBM等都支持对回归问题的处理。与构建决策树类似,构建回归树时需要考虑的问题是,选择哪一个属性对当前的数据进行划分。与分类决策树不一样的地方在于,需要预测的属性是连续的,因而在叶子节点选择什么样的预测模型也很关键。
2 CART回归树的特征和分割点选择准则
CART分类树采用基尼指数最小化准则或基尼增益最大化原则,而CART回归树常用均方误差(Mean Squared Error,MSE或L2)最小化准则作为特征和分割点的选择方法。
对于回归树来说,常见的三种不纯度测量方法是:
1. 均方误差最小化
2. 最小平均绝对误差
3. 最小半泊松偏差
3 CART回归树原理
CART回归树和CART分类树最大的区别在于输出:如果输出的是离散值,则它是一棵分类树;如果输出的是连续值,则它是一棵回归树。
对于回归树,每一个节点都可以被认为是一个回归值,只不过这个值不是最优回归值,只有最底层的节点回归值可能才是理想的回归值。
一个节点有回归值,也有分割选择的属性。这样给定一组特征,就知道最终怎么去回归以及回归得到的值是多少了。
在本文中,介绍CART回归决策树时,使用最小二乘法。
直觉上,回归树构建过程中,分割是为了最小化每个节点中样本实际观测值和平均值之间的残差平方和。
给定一个数据集D={(x1,y1),(x2,y2),…,(xi,yi),…,(xn,yn)},其中xi是一个m维的向量,即xi含有k个特征,记为变量X,是自变量,y是因变量。
假设一棵构建好的CART回归树有M个叶子节点,这意味着CART将m维输入空间X划分成了M个单元R1,R2,…,RM,同时意味着CART至多会有M个不同的预测值。CART最小化均方误差公式如下:

其中, c m c_{m} cm表示第m个叶子节点的预测值。
想要最小化CART回归树总体的均方误差,只需要最小化每一个叶子节点的均方误差即可,
而最小化一个叶子节点的均方误差,只需要将预测值设定为叶子中含有的训练集元素的均值,即
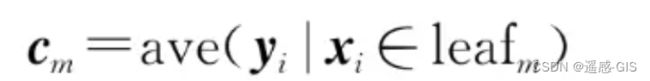
所以,在每一次分割时,需要选择分割特征变量(splitting variable)和分割点(splitting point),使得模型在训练集上的均方误差最小。
这里采用启发式的方法,遍历所有的分割特征变量和分割点,然后选出叶子节点均方误差之和最小的那种情况作为划分。
选择第j个特征变量xj和它的取值s,作为分割变量和分割点,则分割变量和分割点将父节点的输入空间一分为二。
最小二乘回归树生成算法的主要思路为在训练数据集所在的输入空间中,递归地将每个区域划分为两个子区域并决定两个子区域上的输出值,构建二叉决策树。其输入为训练数据集D,输出为回归树f(x)。具体的算法流程如下:
-
选择最优切分变量j与切分点s,求解下式。遍历变量j,对固定的切分变量j扫描切分点s,选择使下式达到最小值的对(j,s)
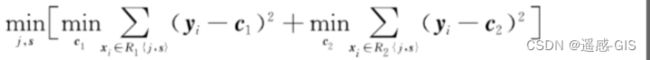
-
用选定的对(j,s)划分区域并决定相应的输出值。
-
继续对两个子区域调用步骤1和2直至满足停止条件。
4 CART回归树核心代码
CART回归树和CART分类树的整体代码框架类似,只是其构建树所划分数据集的方式不同,
具体见:CART分类树源码
这里对构建树的过程重点描述:
def create_tree(self, X, y, feature_names):
"""创建树
X: 满足要求的数据集,行为样本,列为特征,样本要求离散,如果是连续的,则先离散化
y: 目标,因变量,连续值
feature_names: numpy.array
return tree: dict
"""
# 若X中样本y都是一样的,则停止划分
if y.max() == y.min():
return y[0]
# 若节点样本数小于min_samples_split,或者属性集上的取值均相同
if len(y) <= min_samples_split or X.max()==X.min():
return y.mean()
# 按照“平方误差最小”,从feature_names中选择最优切分点
# 这里是和分类最大不同之处,后面预测啥的基本都一样
best_split_point, best_feature_index = choose_best_point_to_split(X, y)
best_feature_name = feature_names[best_feature_index]
# 根据最优切分点,进行子树的划分
tree = {best_feature_name: {}}
sub_feature_names = feature_names.copy()
sub_X_1 = X[X[:, best_feature_index]<=best_split_point, :]
sub_y_1 = y[X[:, best_feature_index]<=best_split_point]
sub_X_2 = X[X[:, best_feature_index]>best_split_point, :]
sub_y_2 = y[X[:, best_feature_index]>best_split_point]
leaf_left = "<= {}".format(best_split_point)
leaf_right = "> {}".format(best_split_point)
tree[best_feature_name][leaf_left] = create_tree(sub_X_1, sub_y_1, sub_feature_names)
tree[best_feature_name][leaf_right] = create_tree(sub_X_2, sub_y_2, sub_feature_names)
return tree
下面具体描述choose_best_point_to_split函数:
def choose_best_point_to_split(self, X, y):
"""选择最优切分点
X: 满足要求的数据集,行为样本,列为特征,样本要求离散,如果是连续的,则先离散化
y: 目标,因变量,连续值
return best_split_point: 最优切分点 float
return best_feature_index: 最优切分点所在属性的索引 int
"""
best_split_point = 0.0
best_feature_index = -1
best_loss_all = float('inf')
num_feature = X.shape[1] # 属性的个数
for i in range(num_feature): # 遍历每个属性
feature_value_list = X[:, i] # 得到某个属性下的所有值,即某列
unique_feature_value = list(set(feature_value_list)) # 得到无重复的属性特征值
unique_feature_value.sort() # 升序排序
split_points = [(unique_feature_value[index] + unique_feature_value[index+1])/2.0 \
for index in range(len(unique_feature_value)-1)]
# 计算各个候选切分点的损失函数
for split_point in split_points:
# 计算左子树的损失函数
sub_y_left = y[X[:, i]<=split_point]
loss_left = np.sum((sub_y_left - sub_y_left.mean()) ** 2)
# 计算右子树的损失函数
sub_y_right = y[X[:, i]>split_point]
loss_right = np.sum((sub_y_right - sub_y_right.mean()) ** 2)
# 计算该切分点的总损失函数
loss_all = (loss_left + loss_right)
# 取损失函数最小时的属性索引和切分点
if best_loss_all > loss_all:
best_loss_all = loss_all
best_feature_index = i
best_split_point = split_point
return best_split_point, best_feature_index
5 总结
本文介绍了CART回归树,介绍了回归于分类的不同之处,以及回归树特征和分割点的选择,原理以及核心代码等。
欢迎点赞,收藏,关注,支持小生,打造一个好的遥感领域知识分享专栏。
关注其他平台专栏:遥感专栏
同时欢迎私信咨询讨论学习,咨询讨论的方向不限于:地物分类/语义分割(如水体,云,建筑物,耕地,冬小麦等各种地物类型的提取),变化检测,夜光遥感数据处理,目标检测,图像处理(几何矫正,辐射矫正(大气校正),图像去噪等),遥感时空融合,定量遥感(土壤盐渍化/水质参数反演/气溶胶反演/森林参数(生物量,植被覆盖度,植被生产力等)/地表温度/地表反射率等反演)以及高光谱数据处理等领域以及深度学习,机器学习等技术算法讨论,以及相关实验指导/论文指导等多方面。
如果对具体的详细示例有兴趣,可以参考本专栏的参考书目:
<现代决策树模型及其编程实践:从传统决策树到深度决策树 黄智濒>
其电子书和其相关的源码可通过下述咨询链接获取
资源获取链接