数学建模(多分类问题)
前言
多分类问题是机器学习中的一种常见任务,其目标是将输入数据分配到三个或更多预定义的类别之中。解决这类问题的方法包括一对一(One-vs-One, OvO)和一对多(One-vs-All, OvA 或 One-vs-Rest, OvR)策略,前者通过构建多个分类器来比较每对类别,后者则是为每个类别构建一个分类器以区别该类别和其他所有类别。这些技术有助于从给定的训练数据集中学习分类模型,并在新的未知数据上进行准确的预测。
一、任务介绍
今天就带大家了解一下多分类问题,前面两个帖子讲的都是回归问题,本次任务是在sklearn的数据库中抓取20个类别新闻数据集,创建一个逻辑回归模型,将文本数据转化为特征向量,使用模型训练该数据,将训练好的模型对新的数据集进行预测,最后计算预测值与真实值之间的准确度。
1.1 逻辑回归与线性回归区别
1. 目标变量类型 线性回归:适用于连续型目标变量。预测的结果是一个数值范围内的值。 逻辑回归:适用于二分类或多元分类问题。预测的是类别标签的概率。 2. 模型输出 线性回归:输出是一个实际的数值,比如房价、销售额等。 逻辑回归:输出是一个介于0和1之间的概率值,表示某个样本属于某一类别的概率。 3. 损失函数 线性回归:常用最小二乘误差作为损失函数。 逻辑回归:使用对数似然损失函数(也称为交叉熵损失函数)。
二、代码解析
from sklearn.datasets import fetch_20newsgroups # 在sklearn数据库中抓取20个类别的新闻数据
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score首先导入训练模型所需要的库
pip install -U scikit-learn该指令用于终端下载sklearn库,scikit-learn 是一个广泛使用的 Python 库,主要用于机器学习任务。它提供了大量的工具和算法,可以轻松地实现数据预处理、特征选择、模型训练、模型评估等一系列机器学习流程。
sklearn.datasets.fetch_20newsgroups 是一个函数,它用于从互联网上获取 "20 Newsgroups" 数据集 包含了大约 20,000 封电子邮件消息 这些消息是从 20 个不同的 Usenet 新闻组收集的。这些新闻组涵盖了各种主题,如计算机、宗教、科学技术等作为我们本次实验的数据集。后面几个常用的函数前面两个帖子也已经讲过,这里不多赘述。
# 加载 20 newsgroup 数据集
train = fetch_20newsgroups(subset="train") # 抓取内部训练集
test = fetch_20newsgroups(subset="test") # 抓取内部测试集subset参数用于指定训练集还是测试集,这里用train,test变量分别存储训练集和测试集数据,按住 CTRL 键可以直接进入该函数。
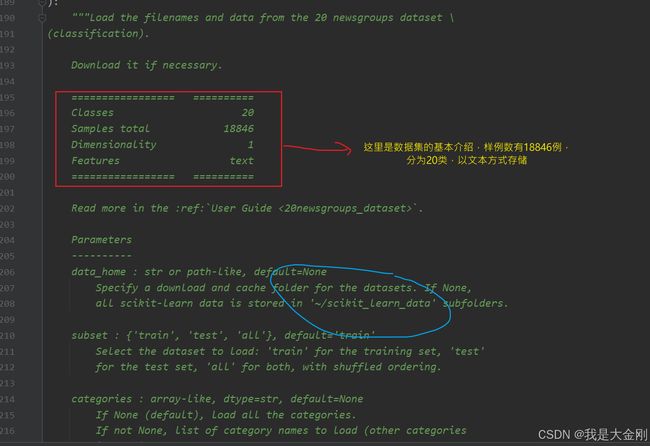
上述图片中红色方框是该数据集的基本介绍,蓝色框里面的路径表示数据集下载路径,该代码会将文本数据下载到本地,以上目录表示C盘用户目录下的scikit_learn_data文件夹中,运行该代码,可以在本地计算机该目录下找到新闻数据集,以后不需要也可以手动删除,不想安装到C盘的宝子可以在参数中定义下载路径。

以上就是我电脑中该文件夹的位置。
# 创建一个管道,将文本特征提取和逻辑回归结合在一起
pipeline = make_pipeline(CountVectorizer(),LogisticRegression(max_iter=500))
pipeline.fit(train.data,train.target)CountVectorizer 是 scikit-learn 中的一个类,用于将文本数据转换为数值特征向量,方便计算机读取和处理。make_pipeline 创建一个管道,使文本特征提取和逻辑回归结合在一起,使得新的模型对输入的文本数据有一个特征提取的能力,又有逻辑回归的能力--即分类的能力。
下面详细讲一下 CountVectorizer 的功能,
from sklearn.feature_extraction.text import CountVectorizer
# 将文本转化为数值特征向量
text = ["It was a fine day today"," I want to play basketball,let's go to play"]
vector = CountVectorizer()
# 调用fit_transform方法构建词汇表,用于文本转化
text_counter = vector.fit_transform(text)
'''
先通过 fit 方法学习文本数据中的词汇表(即所有出现过的词语及其对应的索引)
然后通过 transform 方法将文本数据转换成一个稀疏矩阵,其中每个元素表示文本中某个词的频率
'''
feature_name = vector.get_feature_names_out() # 向量化器所创建特征的名称
print("稀疏矩阵:\n",text_counter)
print("密集性矩阵:\n",text_counter.toarray())
print("元素对应的单词名称:\n",feature_name)2.1 方法积累
这里就用了一个简单的文本信息展示 CountVectorizer 的功能,编辑了两段文字
"It was a fine day today"," I want to play basketball,let's go to play"
它目前还不支持中文,大家可以使用英文或者其他国家文本(主要是机器太难读懂中文了,相信大家以后可以攻破这个难题,使中国也有自己的文本解读器),fit_transform 用于文本统计transform 将读取的单词转化为词向量,并且记录单词出现的次数。feature_name 顾名思义,就是将提取特征的名称输出,让大家知道每个向量对应的单词,下图给大家详细展示。

橙色框 表示统计出的稀疏矩阵,(np.int32(0),np.int32(4))表示该词向量对应密集矩阵的位置(0,4),根据 红色框 可以知道,该单词是 it,出现次数为1,再举一个例子(np.int32(1),np.int32(7)),对应密集矩阵(1,7),第二行第八个位置(默认从0开始计数),对应的单词应该是 to ,一共出现两次。
红色框 表示相应的密集矩阵,每一行对应一段话,对于这两段话,一共提取到 11 个单词,第三个框名称顺序与第二个框的向量是一一对应的,举例说明红色框第一行表示的意思,第一个数字 0对应 basketball,在第一段话中没有出现,所以词向量中数字为 0 ,第二个数字 1,表示单词day,在第一段话出现一次,所以对应词向量数组为 1,以此类推。
2.2 补充说明
稀疏矩阵是专门用来高效存储和操作包含大量零值的大规模矩阵的一种数据结构。在机器学习和自然语言处理领域
稀疏矩阵非常常见,特别是在处理文本数据时,因为大多数词汇在一个文档中并不出现,导致文档-词汇矩阵中会有大量的零值。
一般数据存储有两种方式,一种是稀疏矩阵存储,一种就是密集型矩阵存储,学过数据结构的宝子应该知道,如果数据中存在大量零元素,那么稀疏矩阵存储无疑节省了大量空间,因为它只存储非零元素对应的位置和数值,这里 CountVectorizer 默认的是csr存储格式,也就是稀疏矩阵存储,调用 toarray 方法可以将他转化为密集型矩阵。
pipeline.fit(train.data,train.target)
y_pred = pipeline.predict(test.data)
score = accuracy_score(y_pred,test.target)
print("accuracy : {:.2f}".format(score))最后将测试集目标结果与测试集预测结果分析,计算训练模型的精确度。

精度为0.79,大家也可以使用自己的数据集进行测试,因为我没有好的数据集,这里就不能带着大家测试了。以下是完整代码。
三、完整代码
from sklearn.datasets import fetch_20newsgroups # 在sklearn数据库中抓取20个类别的新闻数据
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
'''
sklearn.datasets.fetch_20newsgroups 是一个函数,它用于从互联网上获取 "20 Newsgroups" 数据集
包含了大约 20,000 封电子邮件消息
这些消息是从 20 个不同的 Usenet 新闻组收集的。这些新闻组涵盖了各种主题,如计算机、宗教、科学技术等
'''
# 加载 20 newsgroup 数据集
train = fetch_20newsgroups(subset="train") # 抓取内部训练集
test = fetch_20newsgroups(subset="test") # 抓取内部测试集
# 创建一个管道,将文本特征提取和逻辑回归结合在一起
pipeline = make_pipeline(CountVectorizer(),LogisticRegression(max_iter=500))
pipeline.fit(train.data,train.target)
y_pred = pipeline.predict(test.data)
score = accuracy_score(y_pred,test.target)
print("accuracy : {:.2f}".format(score))这里是比较简略的代码,主要是熟悉如何简单构造逻辑回归模型,如何使用逻辑回归模型做分类。