#数据结构# 单链表的实现1(C语言)
目录
链表的概念:
单链表的实现:
1. 链表的基本单元:
2.申请结点(BuySListNode):
3.打印链表(SListPrint):
链表的概念:
“链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。”
简单来说可以说为“一环扣一环”,每个结点的数据都有着联系下一个结点的方式。
为了方便,我们把链表的名称简化为 “SList”。
单链表的实现:
1. 链表的基本单元:
typedef struct
{
SLTDataType data;
struct SListNode* next;
}SListNode;在SListNode结构体中,存放一个SListNode的结构体指针,这个指针即为指向下一位结点的地址,命名为“next”。
以下为单链表简图:
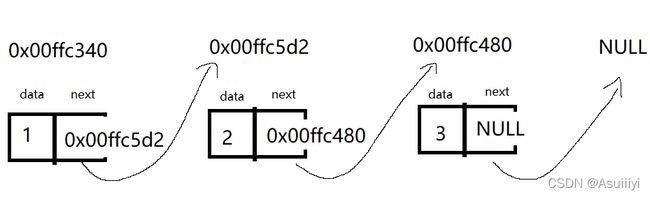
假设有以上的单链表,其中地址为0x00ffc340 的结点可以称为头结点,该结点中的next为0x00ffc5d2,即为第二个结点的地址,第二个结点中的next为第三个结点的地址......直到第三个结点以后,如果没有新的结点,则这个结点的next指向空,即 next=NULL
data中的类型往往不一定是int整形,为了修改方便,我们选择将x的类型整体定义一下,这里定义的x类型为整形:
typedef int SLTDataType;2.申请结点(BuySListNode):
实现申请结点,首先要为SListNode结构体开辟一个新的空间,新结点取名为newnode:
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));其次,需要为newnode的data赋值, 作为新结点,在没有继续申请结点的情况下,next应该默认指向空NULL:
newnode->data = x;
newnode->next = NULL;需要注意的点是:如果malloc开辟的newnode地址为空,这种情况是错误的,应该写一个判断,并且终止程序:
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}最后,由于是新的结点,BuySListNode函数需要返回新结点的地址以便使用(整体代码):
SListNode* BuySListNode(SLTDataType x)//申请结点
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
else
{
newnode->data = x;
newnode->next = NULL;
}
return newnode;
}3.打印链表(SListPrint):
打印链表最基本的思路;先找头结点,通过头结点找下一个结点,找到一个,就打印一个,直到最后一个结点为止。寻找下一个结点的方法:
SListNode* node =node->next;这段代码的意思大概就是,将node的结构体指针的下一位,赋值给当前的node结构体,所以当前node的地址就变成了它原本下一位结点的地址。
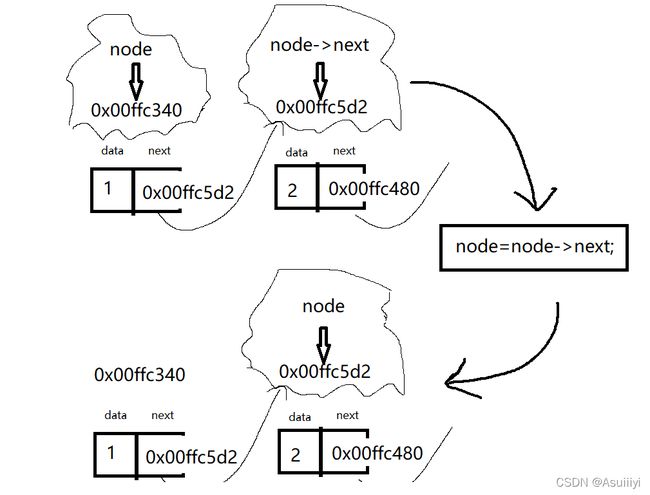
但也需要注意一个点,当头结点为NULL,即链表为空时,我们不可以执行打印的操作,否则在node=node->next这个环节有可能引起计算机报错。
以下为函数代码:
void SListPrint(SListNode* plist)//打印链表
{
SListNode* cur = plist;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}