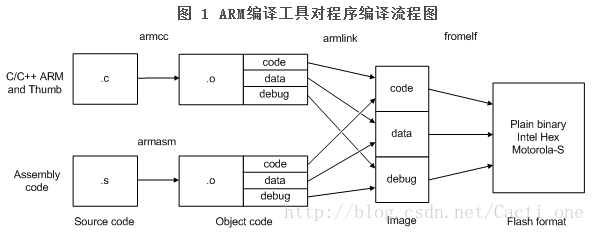
Cortex-M3(2) 汇编启动文件分析
1、汇编文件理解与分析
参考:https://blog.csdn.net/cacti_one/article/details/72811281
由于启动代码是用汇编语言写的,并且启动代码中有大量的伪指令(Directives),所以,在正式介绍启动代码前,先来介绍下相关的伪指令。
一、伪指令(Directives)
由于MDK中的汇编器(汇编编译器)用的是ARM的汇编器,所以可以从ARM官网下载汇编器的用户指南寻找关于伪指令的详细介绍,或者从MDK的“Help”中的汇编器用户指南中查找。
在ARM汇编语言程序里,有一些特殊指令助记符,这些助记符与指令系统的助记符不同,没有相对应的操作码,通常称这些特殊指令助记符为伪指令,他们所完成的操作称为伪操作。
伪指令(directives)也称汇编伪指令,是ARM汇编器提供的一种仅仅在汇编程序被汇编过程中指导汇编器如何进行汇编的且不同于指令的特殊“指令”,即为完成汇编程序作各种准备工作的。伪指令既不会控制机器的操作,也不会被汇编器生成机器码,只要汇编过程完成它的使命就结束了。
如图2所示,ARM汇编器提供了多种多样的伪指令,根据功能的不同可以分别:符号定义伪指令、数据定义伪指令、汇编控制伪指令、宏伪指令及其它伪指令。
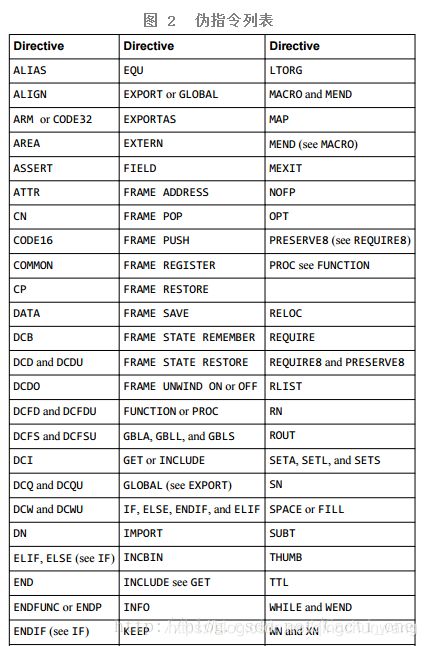
下面将详细介绍启动代码中用到伪指令:
注意:在汇编语言中,标号、内存变量名、子程序名和宏名等都是标识符。
在汇编语言中,标号的使用方式有两种:
(1)标号后带“:”,这时标号只表示内存地址;
(2)标号后不带“:”,这时标号表示内存地址和单元长度。
● EQU
伪指令EQU用来为一个数字常量、或一个和内核寄存器相关的数值或一个和程序计数器相关的数值定义的一个符号名称。类似于C语言中的”#define “。
语法格式:name EQU expr{ , type}
注意:语法格式中的{ }不属于语法格式的部分,并且{ }中的内容是可选的。
name:数值(expr)的符号名称。
expr:一个与内核寄存器相关的地址,或一个绝对地址,或一个与PC相关的地址,或一个32位整型常量。
type:可选项。它可以是ARM、THUMB、CODE16、CODE32或DATA中的任何一个。
举个例子:fiq EQU 0x1C,CODE32
● AREA
伪指令AREA用来定义一个代码段或数据段(data section),到底是数据段还是代码段可以从属性名词分辨出。
语法格式:AREA sectionname{,attr}…{,attr}…
注意:语法格式中的{ }不属于语法格式的部分,并且{ }中的内容是可选的。
sectionname:代码段或数据段的名称。惯用|.text|,它被用于由C编译器产生的代码段或和C库相关的代码段。
它是一块独立的不可分割的数据段或代码段,可以为任何名称。不过,非字符起始的必须加下划线,如1_dataarea。
attr:由一个或多个被逗号隔开的节(或段)属性组成。
段属性有:ALIGN=expression,表示这个数据或代码段按2^expression个字节对齐;
NOINIT表示不零初始化;
READWRITE表示可读可写;
DATA表示只对数据段进行操作,默认可读可写。
注意:伪指令DATA已经被编译器忽略了,不过它可以作为属性使用。
此外还有其他的属性,这里就不过多介绍了,详见《汇编器用户指南》。
● SPACE
伪指令SPACE用于在存储器中开辟一段连续的存储空间,并初始化为零。
语法格式:{label} SPACE expr
注意:语法格式中的{ }不属于语法格式的部分,并且{ }中的内容是可选的。
label:它是可选的。它可以是任何不与编译器冲突的字符名称,可以被用来说明开辟的内存空间的名称或作用。
expr:开辟的零初始化存储空间的大小,即字节数。也可是某一个有确定数值的字符。
举个例子:若Stack_Size=0x40,那么语句 Stack_Mem SPACE Stack_Size是正确的。
● PRESERVE8
伪指令PRESERVE8指定当前的文件中,堆栈区的对齐方式为8字节对齐。
语法格式:PRESERVE8 {bool}
注意:语法格式中{ }不属于语法格式的部分,并且{ }中的内容是可选的。
bool:它是可选的。它不是 true 就是 false,默认为true。
● THUMB
伪指令THUMB命令汇编器以UAL语法将THUMB后面的指令翻译成T32指令。
语法格式:THUMB
● EXPORT
伪指令EXPORT用于在程序中声明一个全局的标号,该标号可在其他的文件中被引用。
语法格式:EXPORT的语法格式共有5种,下面主要介绍下启动代码中用到的3种。
(1)EXPORT { [WEAK]}
(2)EXPORT symbol { [SIZE=n]}
(3)EXPORT symbol [ WEAK {,attr}{type{,set}}{,SIZE=n}]
注意:语法格式中的{ }不属于语法格式的部分,并且{ }中的内容是可选的。
[WEAK]:表示其他的同名标号优先于该标号被引用。如果省略symbol,那么所有的标号都是“WEAK”。
从启动代码中可以发现,中断服务函数是弱声明的(由[WEAK]关键字标注)。所谓弱声明,即:如果用户定义了相同的函数则启动代码中的该函数失效而使用用户定义的中断服务函数。这样是为了防止用户使能了中断而没有中断服务函数,从而造成程序崩溃。假设使能了中断,而用户又没有定义这个中断服务函数则会进入默认中断,默认中断为死循环(注意:死循环与程序崩溃不是一个概念)。
symbol:它是全局属性标号,区分大小写。如果省略symbol,那么所有标号都是全局的。
● IMPORT
IMPORT伪指令用于通知编译器要使用的标号在其他的源文件中被定义(即在外部文件中被定义,相当于C语言中的extern),但要在当前源文件中引用,而且无论当前源文件是否引用该标号,该标号均会被加入到当前源文件的标号表中。该标号在程序中区分大小写。
语法格式:
(1)IMPORT symbol { [type]}
(2)IMPORT symbol { [SIZE=n]}
(3)IMPORT symbol [WEAK{,attr}…{,type}…{,SIZE=n}]
[WEAK]:[WEAK]选项表示当所有的源文件都没有定义这样一个标号时,编译器也不给出错误信息,在多数情况下将该标号置为0。若该标号被B或BL指令引用,则将B或BL指令置为NOP操作。
symbol:它分别在汇编源文件、目标文件或库文件中。区分大小写。
● DCD
伪指令DCD用于分配一片连续的字存储单元并用指定的数据初始化。用DCD分配的字存储单元是字对齐的。
语法格式:{label} DCD {U} expr {,expr}
expr:它是程序表达式或数字表达式
● IF ELSE ENDIF
伪指令IF,ELSE,ENDIF用来允许有条件的汇编指令或伪指令。
语法格式:
IF logic-expression
指令序列1
ELSE
指令序列2
ENDIF
说明:IF,ELSE,ENDIF伪指令能根据条件的成立与否决定是否执行某个指令序列。当IF后面的逻辑表达式为真,则执行指令序列1,否则执行指令序列2。其中,ELSE及指令序列2可以没有,此时,当IF后面的逻辑表达式为真,则执行指令序列1,否则继续执行后面的指令。
此外,伪指令IF,ELSE,ENDIF可以嵌套使用。
逻辑表达式logic-expression也可以为单目运算(Unary Operator,详细的可参考《汇编器用户指南》)。如单目操作数 :DEF: ,:DEF:A则表示如果A被定义,则为真,否则为假。
● PROC
伪指令PROC标志着程序的开始。它容易理解,这里不多做介绍。
● ENDP
伪指令ENDP标志着程序(调用)的结束。这里不多做介绍。
● END
伪指令END告诉汇编器已经到源程序文件的末尾。这里不多做介绍。
二、汇编指令
● B
指令B是跳转指令。
语法格式:B label
在启动代码中,会发现label是一个点“.”,它表示跳转到当前的指令地址处(即当前的PC值),也就是进入到当前的死循环中了。
● BX
指令BX是跳转指令。
语法格式:BX Rm
其中,Rm是一个内核寄存器,它的值是一个地址值。上述指令表示程序跳转到Rm所指向的指令处。
● LDR
LDR既可以作为加载指令使用,也可以作为伪指令。
作为伪指令时的语法格式:LDR Rt,=expr 。其作用是将expr的值(expr为立即数)或expr的地址(expr是一个标号)加载到Rt中。
作为加载指令时的语法格式:LDR {type}{cond} Rt, [Rn {, #offset}]。其作用是将Rn(Rn的值是一个地址值)中的数值加载给Rt。
● ORR
指令ORR是逻辑或操作指令。
语法格式:ORR {S} {cond} Rd, Rn, operand2
其中,Rn是第一操作数,operand2是第二操作数。上述指令表示将Rn和operand2进行逻辑或操作,其结果保存到目标操作数Rd中。
● STR
STR是一个典型的存储指令。
语法格式:STR {type}{cond} Rt, [Rn {, #offset}]。该指令表示将寄存器Rt中的字数据存放到以Rn{+offset}为地址的寄存器中。
注意:语法格式中的{ }不属于语法格式的部分,并且{ }中的内容是可选的。
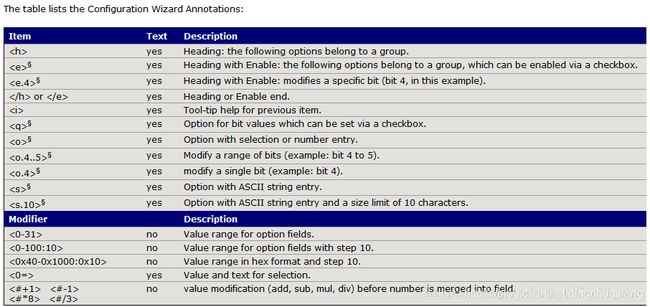
三、启动代码中的配置向导注释
启动代码中的配置向导注释详见《uVision User’s Guide》中的Utilities中的”Congiguration Wizard”。
配置向导注释被用来在汇编、C/C++或初始化文件中产生配置控制。
四、堆栈存储器
堆栈存储区是在片上存储器中的SRAM(或RAM)中由用户自行开辟的一片数据存储区域,并且堆栈区的大小可根据用户的需要任意指定(只要不超过SRAM或RAM的大小),而堆栈区的位置由编译器指定分配。
Cortex-M3/M4处理器的堆栈指针SP是“满递减,空递增”,呈现向下逆生长的特点。
堆栈区数据的存储特点是“先进后出,后进先出”。这种特点是由堆栈指针的移动方式决定的(先入栈的数据对应的指针值比较大,后入栈的数据对应的指针值比较小,而出栈时堆栈指针的值是递增的,所以指针值大的数据当然后出栈)。
堆栈的作用:局部变量的存储、函数调用时函数或子程序间数据的传递(形参的保存,其实函数调用一旦结束被调函数中定义的所有局部变量单元就会被释放)、函数调用时现场数据的保存、中断发生时现场数据的保存。
四、启动代码分析
1、启动代码在MDK的已安装文件中,路径如下:ARM\Pack\Keil\STM32F4xx_DFP\2.11.0\Drivers\CMSIS\Device\ST\STM32F4xx\Source\Templates\arm
2、启动代码的作用:
C程序的的执行是从主函数main()开始的。可是微控制器上电后,是如何寻找main()函数的呢?显然,我们不可能从硬件上来寻找到main()函数的入口地址。实际上,main()函数的入口地址是编译器在编译过程中分配的。并且,从微控制器上电到main()函数执行前,微控制器有个启动的过程,这个启动过程正是启动代码执行的过程,时间非常短暂。
启动代码的作用:
(1)初始化堆栈指针 SP == _initial_sp;
(2)初始PC指针 ==Reset_Handler(复位处理程序);
(3)初始化中断向量表;
(4)配置系统时钟;
(5)调用C库_main()函数初始化用户堆栈,从而最终调用main()主函数去到C世界。
下面是startup_stm32f429xx.s启动代码:
第48~52行:定义了一段大小为1KB的堆栈空间,并初始化为0。(堆栈也叫栈)
第48行:定义一个变量Stack_Size,并赋值为0x00000400;
第50行:定义一个数据段(或数据节)STACK,不零初始化,可读可写,并以8个字节对齐;
第51行:开辟一个大小为0x00000400(即1KB)的初始化为零的连续的内存空间,并命名为Stack_Mem;
第52行:_initial_sp是标号,表示堆栈的栈顶地址。
第59~64行:定义了一段大小为0.5KB的堆空间,并初始化为0。由于未用到编译器自带的内存管理(malloc , free等),不会用到堆,故可以将堆大小设置为0。
第59行:定义一个变量Heap_Size,并赋值为0x00000200;
第61行:定义一个数据段HEAP,不初始化为零,可读可写,并以8个字节对齐;
第62行:_heap_base是标号,表示堆基地址;
第63行:开辟一个大小为0x000000200(即512Bytes)的初始化为零的内存空间,并命名为Heap_Mem;
第64行:_heap_limit是标号,表示堆顶地址。
第66行:PRESERVE8表示当前文件中的堆栈区按8字节对齐;
第67行:THUMB指示汇编器将THUMB后的指令翻译成T32。
第71~190行:系统复位时,向量表被映射到零地址。
第71行:定一个代码段RESET,只可读;
第72~74行:分别定义3个全局变量 _Vectors 、_Vectors_End 及_Vectors_Size;
第76~186行:分别定义了多个连续的字存储单元,这些存储单元用于存储向量表。标号_Vectors是栈顶地址 _initial_sp,__Vectors_End表示向量表的结尾地址。
第188行:定义一个变量__Vectors_Size 用于表示向量表的大小;
第190行:定义一个代码段|.text|,只可读;
第193~202行:复位处理程序,可根据实际情况进行修改。
第193行:Reset_Handler是标号。PROC表示程序的开始。
第194行:定义一个全局变量Reset_Handler,并指定为[weak](若用户没有定义同名的Reset_Handler函数,则就去执行第195~202行的程序)。
第195~196行:告知编译器,SysemInit和_main是两个在其他文件中定义过的符号名(或函数名)。
第206~246行:空异常处理程序(函数入口)。其中,”B .”表示跳转到当前指令,所以也就是进入无限循环当中。ENDP表示程序结束。
第248~433行:空异常处理程序。系统默认的处理程序和全局符号。
第440~449行:用户栈和堆初始化程序。
第440行:IF…ELSE…ENDIF结构。如果使用(或定义)_MICROLIB,那么,定义了3个全局属性变量。否则,定义一个全局属性的标号__user_initial_stackheap,并且通知编译器本文件中应用的_use_two_region_memory在其他文件中定义了。注意:MiCROLIB缺省的情况下使用的是Keil C库。
第453~460行:分别将栈顶地址,栈底地址,堆顶地址及堆基地址存放在寄存器R1,R3,R0,R2中。
注意:堆区和栈区的名称分别代表堆区和栈区的起始地址,由于栈逆生长,所以它的名称代表栈区的栈底地址。