Python之selenium,使用webdriver模拟登录网站(含验证码)
一、前言
前段时间做了一个小项目,其中有一段需要自动获取网站后台的数据,但是这个网站没有任何提供给开发者的API,所以只能靠自己去探索。
起初想着用发送请求的方式去模拟登陆,获取cookies,从而再获取网站后台数据,但是因为自己太菜了一些原因,放弃了这个方法。
后来想到使用webdriver调用浏览器来模拟登陆,发现操作起来简单很多,而且可以达到同样的效果,于是便有了这篇文章。
二、准备工作
需要下载和安装一些东西,可以去官方教程中进行了解。 学习本篇文章的内容只需要安装好selenium库以及下载好浏览器对应版本的驱动即可。
三、模拟登陆网站
1. 加载驱动和配置
这里我使用的是默认配置,如果有特殊需求,可以参照官方文档进行学习
browser = webdriver.Chrome(executable_path='你驱动的本地路径', options=webdriver.ChromeOptions())
2. 打开网站
browser.get(要打开的网站)
不出意外,此时会自动拉起你的浏览器并进入到你想进入的网站了,如果你的浏览器同时还多出来了一个像下图这样的页面:
不用管,因为这对你将要进行的操作基本没有影响。
3. 寻找元素并填入账号密码
常规写法如下
browser.find_element_by_name('username').send_keys('你的账号') # 填入用户名
browser.find_element_by_name('password').send_keys('你的密码') # 填入密码
或者你也可以这样,效果和上面一样
username = browser.find_element_by_name('username') # 寻找账号输入框
username.send_keys('你的账号') # 填入用户名
password = browser.find_element_by_name('password') # 寻找密码输入框
password.send_keys('你的密码') # 填入密码
上面寻找元素的方法中填入的username和password是根据页面中的元素name进行寻找的,需要根据实际情况更改,如果输入框没有name属性,那么也可以使用id或者xpath进行寻找。
browser.find_element_by_id()
browser.find_element_by_xpath()
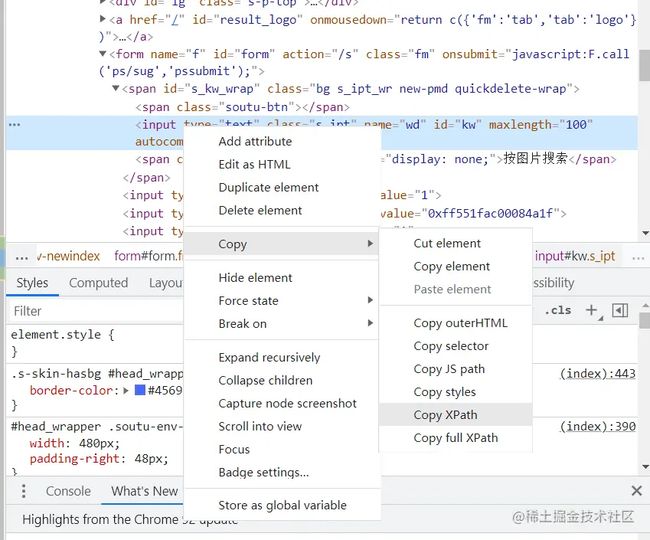
当然前提是你要先手动去网站中获取输入框的这些属性,比如说百度,按F12进行元素审查,然后按Ctrl+shift+C选择你要找的元素,如下图:
然后去查看该元素有没有属性id或者name,如果有的话可以直接用,如果没有的话就单击鼠标右键,然后选择cope,选择xPath,然后把你复制到的xPath放到代码里就好了。
4. 填写验证码
一般的网站登录时都会有验证码,而验证码的识别一般是比较麻烦的一件事情(对于新手来说),这里分享一下我的经验。
首先需要自己去找一个打码平台(直接百度搜打码平台,然后挑一个合适的就好了),然后去阅读它的接入文档,使用它的API进行识别网站的验证码,一般需要给它传入一个以base64编码的字符串,代表待识别图片,然后它会给你返回一些信息,里面会包括识别结果。
回到我们的程序,找到验证码图片的元素,有些验证码可以直接获取到base64形式的图片链接,这时候直接传给打码平台进行识别就可以了,代码如下:
image = browser.find_element_by_xpath('//*[@id="root"]/div/div/div/div/div[2]/div[3]/div[1]/div[2]/img')
image = image.get_attribute('src') # 获取当前验证码图片链接
imageCaptchaValue = readImage(image) # 这里的readImage是用来给打码平台发送请求的方法,需要根据自己的实际情况去实现这个方法
captchaValue = browser.find_element_by_xpath('//*[@id="root"]/div/div/div/div/div[2]/div[3]/div[1]/input') # 验证码输入框
captchaValue.send_keys(imageCaptchaValue) # 填入验证码
如果你要登录的网站的验证码不是base64形式的链接,甚至你单击右键在新窗口中打开图片时显示的又是另一张图片,那么很可能就需要用到下面的方法了。
- 调用screenshot()方法对验证码进行截图操作,并对图片进行保存
- 将保存的图片以二进制的方式打开,并转为base64编码
- 将得到的base64编码字符串解码并传给打码平台进行识别
代码如下:
browser.find_element_by_name('img').screenshot("img.png") # 找到验证码并将验证码以截图的方式保存
f = open('img.png', 'rb') # 二进制方式打开图文件
image = base64.b64encode(f.read()) # 读取文件内容,转换为base64编码
f.close()
imageCaptchaValue = readImage(image.decode()) # base64编码解码后进行识别
browser.find_element_by_name('rand').send_keys(imageCaptchaValue) # 填入验证码
这里需要注意的是以base64编码进行发送的时候需要先解码,否则会报错:
TypeError: Object of type bytes is not JSON serializable
进行到这一步,如果不出意外的话,只需要点击登录按钮就可以成功登录了:
browser.find_element_by_id('login_btn1').click() # 点击登录按钮
登录网址后就可以进行自己想要做的事情啦! 这里再放一些登录后可能需要的代码:
browser.switch_to.alert.accept() # 接受弹窗警告
cookies = browser.get_cookies() # 获取当前状态下的cookies
dataUrl = browser.find_element_by_xpath('/html/body/a[1]').get_attribute('href') # 获取数据文件下载路径
四、遇到的一些坑
- 有些网站的元素并不能直接通过find寻找到,比如有些网站页面用了大量的frame或iframe,那么此时需要先进入到该元素所在的frame,然后才能找到需要的元素:
browser.switch_to.frame('left') # 进入到frame下
doSomething......
browser.switch_to.default_content() # 重新回到主页面上操作元素
browser.switch_to.frame('main') # 进入到新的frame中进行操作
doSomething......
- 一般的打码平台都需要充值后才能使用,建议先进行在线免费测试,确认它可以识别我们的验证码了之后再进行充值使用。
- 操作完毕后要记得关闭浏览器
browser.quit() - 如果在调用selenium的一些方法的时候发现pycharm给代码打了中划线,那么可能是这样方法已经不被推荐使用了,这时候稍微修改一下即可:
switch_to_window 改为 switch_to.window
switch_to_default_content 改为 switch_to.default_content
switch_to_frame 改为 switch_to.frame
- 有时候浏览器的加载速度跟不上你代码的运行速度,或者请求验证码识别速度比较慢,建议使用暂停的方法来进行缓冲:
browser.implicitly_wait(3)
time.sleep(2)
五、后记
其实整个流程操作下来,也就几十行代码,但是对于像我这样的菜鸡新手来说,可能需要七找八找,花上好几个小时,才能解决其中遇到的一些问题。学会selenium的一些方法之后,你会发现你还可以做很多其他的事情,然后挂在服务器上……哈哈哈,这里就不多说了。
如果大家在操作过程中还遇到了其他的困难,多多百度,百度能解决你大部分问题。等一个个解决之后,你还可以写一篇博客记录一下,把自己的经验分享给大家,让自己学到的东西更有意义,这也是一种乐趣吧!
最后: 可以在公众号:【自动化测试老司机】免费领取一份216页软件测试工程师面试宝典文档资料。以及相对应的视频学习教程免费分享!,其中包括了有基础知识、Linux必备、Shell、互联网程序原理、Mysql数据库、抓包工具专题、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试、安全测试等。