kube-scheduler调度策略之优选算法(四)
一、概述
摘要: 本文我们继续从源码层面分析kube-scheduler调度策略中的优选调度算法,分析优选算法如何对Node节点进行打分的。
二、正文
说明:基于 kubernetes
v1.12.0源码分析
上文我们说的(g *genericScheduler) Schedule()函数调用了PrioritizeNodes()执行优选策略(打分),接下来我们就具体展开分析。
2.1 PrioritizeNodes对节点打分
// PrioritizeNodes prioritizes the nodes by running the individual priority functions in parallel.
// Each priority function is expected to set a score of 0-10
// 0 is the lowest priority score (least preferred node) and 10 is the highest
// The node scores returned by the priority function are multiplied by the weights to get weighted scores
// All scores are finally combined (added) to get the total weighted scores of all nodes
func PrioritizeNodes(
pod *v1.Pod,
nodeNameToInfo map[string]*schedulercache.NodeInfo,
meta interface{},
priorityConfigs []algorithm.PriorityConfig,
nodes []*v1.Node,
extenders []algorithm.SchedulerExtender,
) (schedulerapi.HostPriorityList, error) {
// If no priority configs are provided, then the EqualPriority function is applied
// This is required to generate the priority list in the required format
// 如果没有配置优选调度算法,则使用 EqualPriorityMap 函数对每个节点打分,这样每个节点的分数都一样,都是1分。
if len(priorityConfigs) == 0 && len(extenders) == 0 {
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
hostPriority, err := EqualPriorityMap(pod, meta, nodeNameToInfo[nodes[i].Name])
if err != nil {
return nil, err
}
result = append(result, hostPriority)
}
return result, nil
}
var (
mu = sync.Mutex{}
wg = sync.WaitGroup{}
errs []error
)
appendError := func(err error) {
mu.Lock()
defer mu.Unlock()
errs = append(errs, err)
}
// 定义results列表,记录每个节点用优选算法打分后的结果
results := make([]schedulerapi.HostPriorityList, len(priorityConfigs), len(priorityConfigs))
// 遍历出所有预选调度算法
for i, priorityConfig := range priorityConfigs {
if priorityConfig.Function != nil {
// DEPRECATED
wg.Add(1)
go func(index int, config algorithm.PriorityConfig) {
defer wg.Done()
var err error
// 使用具体的某个调度算法中的 PriorityFunction,为节点打分。打分的结果放到results列表中
results[index], err = config.Function(pod, nodeNameToInfo, nodes)
if err != nil {
appendError(err)
}
}(i, priorityConfig)
} else {
results[i] = make(schedulerapi.HostPriorityList, len(nodes))
}
}
processNode := func(index int) {
nodeInfo := nodeNameToInfo[nodes[index].Name]
var err error
for i := range priorityConfigs {
if priorityConfigs[i].Function != nil {
continue
}
// 使用具体的某个调度算法中的 PriorityMapFunction,为节点打分。打分的结果放到results列表中
results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo)
if err != nil {
appendError(err)
results[i][index].Host = nodes[index].Name
}
}
}
workqueue.Parallelize(16, len(nodes), processNode)
for i, priorityConfig := range priorityConfigs {
if priorityConfig.Reduce == nil {
continue
}
wg.Add(1)
go func(index int, config algorithm.PriorityConfig) {
defer wg.Done()
// 使用具体的某个调度算法中的 PriorityReduceFunction,为节点打分。打分的结果放到results列表中
if err := config.Reduce(pod, meta, nodeNameToInfo, results[index]); err != nil {
appendError(err)
}
if glog.V(10) {
for _, hostPriority := range results[index] {
glog.Infof("%v -> %v: %v, Score: (%d)", pod.Name, hostPriority.Host, config.Name, hostPriority.Score)
}
}
}(i, priorityConfig)
}
// Wait for all computations to be finished.
wg.Wait()
if len(errs) != 0 {
return schedulerapi.HostPriorityList{}, errors.NewAggregate(errs)
}
// Summarize all scores.
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
result = append(result, schedulerapi.HostPriority{Host: nodes[i].Name, Score: 0})
for j := range priorityConfigs {
// 对分数进行加权后累加
result[i].Score += results[j][i].Score * priorityConfigs[j].Weight
}
}
// 如果使用了 SchedulerExtender ,使用扩展的打分策略继续计算。一般不需要考虑,除非用户自定逻辑来实现更复杂的逻辑
if len(extenders) != 0 && nodes != nil {
combinedScores := make(map[string]int, len(nodeNameToInfo))
for _, extender := range extenders {
if !extender.IsInterested(pod) {
continue
}
wg.Add(1)
go func(ext algorithm.SchedulerExtender) {
defer wg.Done()
prioritizedList, weight, err := ext.Prioritize(pod, nodes)
if err != nil {
// Prioritization errors from extender can be ignored, let k8s/other extenders determine the priorities
return
}
mu.Lock()
for i := range *prioritizedList {
host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score
combinedScores[host] += score * weight
}
mu.Unlock()
}(extender)
}
// wait for all go routines to finish
wg.Wait()
for i := range result {
result[i].Score += combinedScores[result[i].Host]
}
}
if glog.V(10) {
for i := range result {
glog.V(10).Infof("Host %s => Score %d", result[i].Host, result[i].Score)
}
}
return result, nil
}
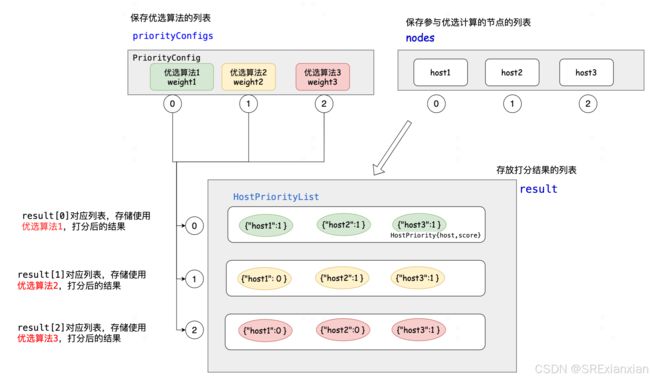
- 依次遍历PriorityConfig中注册的优选算法对节点进行打分
- 再对各个优选算法的打分结果,进行加权后累加得到最终的分数
- 对某个host的打分的计算公式总结:host1最终得分= 优选算法1 * weight1 + 优选算法2 * weight2 + 优选算法3 * weight3 + …
优选算法进行打分的过程示意图
2.2 优选算法有哪些
接下来我们看下默认的调度器加载的优选调度算法有哪些
源码位置k8s.io/kubernetes/pkg/scheduler/algorithmprovider/defaults/defaults.go`
经整理统计优选算法包括如下这些。可以看到除了算法"NodePreferAvoidPodsPriority"之外,其他优选算法的weight都是1.
factory.RegisterPriorityFunction2("EqualPriority", core.EqualPriorityMap, nil, 1)
factory.RegisterPriorityFunction2("MostRequestedPriority", priorities.MostRequestedPriorityMap, nil, 1)
factory.RegisterPriorityFunction2("RequestedToCapacityRatioPriority",priorities.RequestedToCapacityRatioResourceAllocationPriorityDefault().PriorityMap,nil,1)
factory.RegisterPriorityConfigFactory(
"ServiceSpreadingPriority",
factory.PriorityConfigFactory{
MapReduceFunction: func(args factory.PluginFactoryArgs) (algorithm.PriorityMapFunction, algorithm.PriorityReduceFunction) {
return priorities.NewSelectorSpreadPriority(args.ServiceLister, algorithm.EmptyControllerLister{}, algorithm.EmptyReplicaSetLister{}, algorithm.EmptyStatefulSetLister{})
},
Weight: 1,
},
)
factory.RegisterPriorityFunction2("ResourceLimitsPriority", priorities.ResourceLimitsPriorityMap, nil, 1)
factory.RegisterPriorityConfigFactory(
"SelectorSpreadPriority",
factory.PriorityConfigFactory{
MapReduceFunction: func(args factory.PluginFactoryArgs) (algorithm.PriorityMapFunction, algorithm.PriorityReduceFunction) {
return priorities.NewSelectorSpreadPriority(args.ServiceLister, args.ControllerLister, args.ReplicaSetLister, args.StatefulSetLister)
},
Weight: 1,
},
),
factory.RegisterPriorityConfigFactory(
"InterPodAffinityPriority",
factory.PriorityConfigFactory{
Function: func(args factory.PluginFactoryArgs) algorithm.PriorityFunction {
return priorities.NewInterPodAffinityPriority(args.NodeInfo, args.NodeLister, args.PodLister, args.HardPodAffinitySymmetricWeight)
},
Weight: 1,
},
),
factory.RegisterPriorityFunction2("LeastRequestedPriority", priorities.LeastRequestedPriorityMap, nil, 1),
factory.RegisterPriorityFunction2("BalancedResourceAllocation", priorities.BalancedResourceAllocationMap, nil, 1),
factory.RegisterPriorityFunction2("NodePreferAvoidPodsPriority", priorities.CalculateNodePreferAvoidPodsPriorityMap, nil, 10000),
factory.RegisterPriorityFunction2("NodeAffinityPriority", priorities.CalculateNodeAffinityPriorityMap, priorities.CalculateNodeAffinityPriorityReduce, 1),
factory.RegisterPriorityFunction2("TaintTolerationPriority", priorities.ComputeTaintTolerationPriorityMap, priorities.ComputeTaintTolerationPriorityReduce, 1),
factory.RegisterPriorityFunction2("ImageLocalityPriority", priorities.ImageLocalityPriorityMap, nil, 1),
)
2.3 预选算法的控制
有时候我们想对集群的默认调度策略进行干预和控制,比如这个常见需求:集群中分配pod时,我们希望尽快能的平衡Pod到不同的node节点,因为我们的cpu通常超分,"分散布局"Pod,有利于宿主的CPU充分利用。
我们有2中方法控制干预kubernetes的默认调度策略。
- 通过
--policy-config-file配置文件的方式调整调度算法(包括预选与优选算法) - 通过
--policy-configmap也就是k8s中的configmap方式,调整调度算法。
下面通过指定配置文件的方式来设置修改某个打分接口的比重。
-
先创建 kube-scheduler.yaml 文件
-
在Kube-scheduler进程的启动命令中中添加 - --policy-config-file=/etc/kubernetes/policy.cfg指定配置文件。
-
重启Kube-scheduler进程

如果想了解更多,请查看文档Controlling pod placement onto nodes
三、总结
本文分析了优选算法的执行过程并通过阅读源码总结出了打分(预选策略)的计算公式。之后我们整理了默认的调度器中的优选算法有哪些,对应的weight值是多少。最后我们讲述了如何通过修改调度配置策略文件,来控制和干预kubernetes的调度过程。
四、参考文献
-
Controlling pod placement onto nodes
-
kubernetes_scheduler_code