C++——二叉搜索树
1.二叉搜索树
在之前的文章中已经在C语言部分介绍过了二叉树的相关知识(传送门),现在在已有的二叉树基础上接触一种新的规则的二叉树——搜索二叉树。未来我们将继续介绍AVL树、红黑树以及set、map容器,这都需要我们对二叉搜索树有一定的理解。
1.1 二叉搜索树的定义
二叉搜索树又叫做二叉排序树、二叉查找树。我们首先给出二叉搜索树的判定条件,或者说是二叉搜索树的特点。
只有满足如下特点的二叉树才被称为二叉搜索树,对于任意一个结点:
①如果其左子树不为空,那么左子树任意一个结点的值一定小于这个根结点;
②如果其右子树不为空,那么右子树任意一个结点的值一定大于这个根结点;
③这个结点的左右子树也满足上述性质。
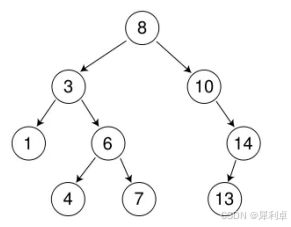
简单来说就是左孩子就是减小的方向,而右孩子就是增大的方向,可以说是非常规整的排列方式了。
1.2 二叉搜索树详解
对于一颗二叉搜索树,为了可以更好的理解它的特性,我们通过代码的方式来熟悉它。但是在开始之前,我们需要知道二叉搜索树根据结点的形式不同,分为了两种类型,分别是K模型和KV模型。
1.2.1 K模型
所谓K模型就是指二叉树的结点中只包含key,在二叉树的搜索中以key作为标准比较大小,所搜索到的值也是key本身。
1.2.1.1 二叉搜索树结点
对于一个K模型的二叉树自然是需要指针指向左右孩子的,而需要存储的内容只有key。
//成员包括:key值、左孩子指针、右孩子指针
template
struct BSTNode {
K _key;
BSTNode* _left;
BSTNode* _right;
//构造函数
//给定key值,构造对应的结点
BSTNode(K key)
:_key(key)
, _left(nullptr)
, _right(nullptr)
{}
}; 1.2.1.2 二叉搜索树的构造函数、析构函数
二叉搜索树的成员即为树的根结点,构造函数使用无参构造即可,值得一提的是析构函数。为了析构一棵树,我们应该采取后序遍历的方法逐一析构二叉树的结点。
//二叉搜索树——K模型
//成员是二叉搜索树的根结点指针
template
class BSTree {
private:
typedef BSTNode Node;
Node* _root;
public:
//构造
BSTree()
:_root(nullptr)
{}
//析构
//析构一棵树需要递归处理,所以需要写一个辅助函数帮助析构的递归处理部分
private:
void Destroy(Node* root)
{
if (root == nullptr) return;
Destroy(root->_left);
Destroy(root->_right);
delete root;
}
public:
~BSTree()
{
Destroy(_root);
_root = nullptr;
}
}; 1.2.1.3 插入数据
插入数据首先要做的是找到应该插入的位置,因为搜索二叉树的规则,对于一个待插入的值key而言,在其值大于当前结点时向右子树继续比较,反之向左子树比较,直到找到一个空位可以插入key为止。注意在第一次插入数据时要特殊处理,因为现在写的二叉搜索树没有头结点,需要判断是否为空树以防止对空指针解引用。
需要强调的是,二叉搜索树会去重,即相同值的结点只允许出现一次(毕竟左小右大,相等是没办法放在其中的)。所以在向下寻找的过程中,如果发现已经存在和待插入结点值相同的结点,那么就视为插入失败。
插入结点的函数返回值是一个bool值,标明是否成功插入。当树中已经存在待插入的值,那么就会插入失败,返回false;其他成功插入的情况就返回true。
//插入数据
//二叉搜索树左孩子比父亲小,右孩子比父亲大
//所以插入数据需要层层比较来找到合适的位置
bool Insert(const K& key)
{
Node* newnode = new Node(key);
//如果是第一次插入,则根结点为空指针,需要特殊处理
if (_root == nullptr)
{
_root = newnode;
return true;
}
Node* parent = _root;
Node* cur = _root;
while (cur)
{
//二叉搜索树已经存在的值不会再插入
//所以结点值大于key,则向左子树找;结点值小于key,向右子树找;如果相等则不再插入,返回false
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else
{
return false;
}
}
if (parent->_key > key)
{
parent->_left = newnode;
}
else
{
parent->_right = newnode;
}
return true;
}1.2.1.4 查找结点
查找二叉树是否存在某一结点很容易,只需要根据二叉搜索树左小右大的规则不断比较即可。
//查找搜索二叉树中是否存在key的结点
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
cur = cur->_left;
}
else if (cur->_key < key)
{
cur = cur->_right;
}
else
{
return true;
}
}
return false;
}1.2.1.5 删除数据
删除某一个结点最重要的一点就是确保不会影响到二叉搜索树的结构,即右孩子>根>左孩子的规则,于是我们就需要分情况分析了。
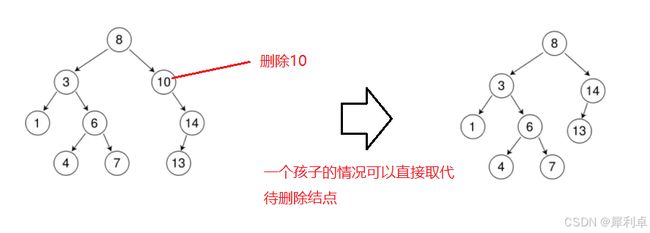
①如果待删除结点只有一个孩子(没有孩子也可以视为只有一个孩子),那么就可以直接让这一个子树取代待删除结点的位置。
②另一种情况就是当待删除结点有两个孩子时,因为这个位置的结点没了,需要有其他的结点来顶替这个位置,我们就需要仔细选择适合这个位置的角色了。这个位置的要求是既要大于左子树的所有节点,还必须大于右子树的所有节点,自然最适合的角色就有两个,一个是左子树的大值(一定比剩余左子树的节点大,同时小于待删除结点,所以也就小于右子树所有节点),另一个则是右子树最小值(一定比剩余右子树的节点小,同时大于待删除结点,所以也就大于左子树所有节点)。
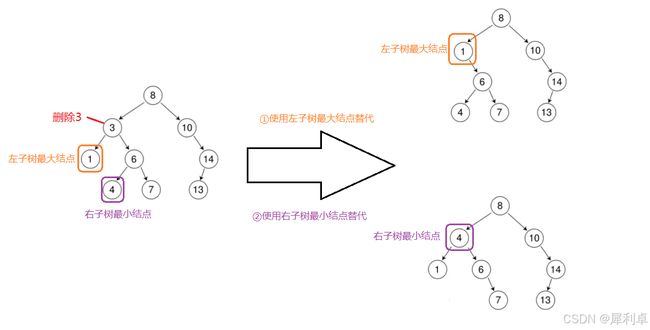
寻找左子树最大结点或右子树最小结点很简单,左子树最大结点就是左子树一直寻找右孩子直至右孩子为空的那个结点,这个结点一定没有右孩子,如果有左孩子就把左孩子向上链接即可;同理,右子树最小结点则是一直寻找左孩子,这个结点一定没有左孩子,如果有右孩子就把右孩子向上链接。
在实际的操作中可以把删除节点变为交换值再删除,这样可以减少结点之间关系链接的修改,具体详情在代码中体现,代码采用找左子树最大结点的方法。由于没有头结点,所以在删除只有一个孩子的结点时需要判断一下是否为根节点,若是则需要特殊处理。
//删除结点
//删除结点后,为了保证二叉搜索树的结构不变,则顶替该位置的结点key值应该大于左子树,小于右子树
//为了满足这一点,可以考虑找左子树最大值或右子树最小值
//因为右孩子一定比父结点大,所以左子树最大值只需要沿着左子树右孩子寻找到尽头即可
//同理,右子树最小值需要沿着右子树左孩子寻找到尽头
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else
{
//删除cur:
//1.cur左树为空(包括全空),直接将右树链在parent上
if (cur->_left == nullptr)
{
if (cur == _root)
{
_root = cur->_right;
}
else if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
delete cur;
return true;
}
//2.cur右树为空,直接将左树链在parent上
else if (cur->_right == nullptr)
{
if (cur == _root)
{
_root = cur->_left;
}
else if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
delete cur;
return true;
}
//3.cur两树均不为空,找左子树最大或右子树最小,与cur替换
else
{
//MaxLeft
Node* change_node = cur->_left;
Node* change_parent_node = cur;
while (change_node->_right)
{
change_parent_node = change_node;
change_node = change_node->_right;
}
//找到最大左树值与其父,为了方便,将最大值与cur值交换即可
cur->_key = change_node->_key;
//由于左树最大值是先找左孩子,再一直找右孩子,所以需要判断是左孩子还是右孩子
//并且左子树最大结点一定没有右孩子,但可能有左孩子,所以需要把左树的根结点链在最大结点父结点对应位置
if (change_parent_node->_left == change_node)
{
change_parent_node->_left = change_node->_left;
}
else
{
change_parent_node->_right = change_node->_left;
}
delete change_node;
return true;
}
}
}
return false;
}1.2.1.6 中序遍历
根据二叉搜索树的特性,对二叉搜索树中序遍历(左、根、右),可以得到一组升序排列的数据。
void Inorder()
{
//中序遍历需要递归,而且调用时不传参,所以需要单另将递归逻辑写出去
_Inorder(_root);
cout << endl;
}
void _Inorder(Node* root)
{
if (root == nullptr) return;
_Inorder(root->_left);
cout << root->_key << ' ' << endl;
_Inorder(root->_right);
}1.2.2 KV模型
KV模型,相较于K模型多了一个value,key和value组成了一个键值对,key作为关键码或者索引,二叉搜索树按照key的大小关系进行排列。value则作为key背后实际代表的内容,当通过索引拿到key时,同步的也就取出来了value。因此KV模型的二叉搜索树可以看作是将索引和值进行分离。
1.2.2.1 二叉搜索树结点
对于一个KV模型的二叉树也是需要指针指向左右孩子的,除此之外,还需要存储key和value。
//成员包括:key值、value值、左孩子指针、右孩子指针
template
struct BSTNode {
K _key;
V _value;
BSTNode* _left;
BSTNode* _right;
//构造函数
//给定key值和value值,构造对应的结点
BSTNode(K key, V value)
:_key(key)
, _value(value)
, _left(nullptr)
, _right(nullptr)
{}
}; 1.2.2.2 二叉搜索树的构造函数、析构函数
KV模型和K模型在类的成员变量、构造函数、析构函数方面没有什么区别。
//二叉搜索树——K模型
//成员是二叉搜索树的根结点指针
template
class BSTree {
private:
typedef BSTNode Node;
Node* _root;
public:
//构造
BSTree()
:_root(nullptr)
{}
//析构
//析构一棵树需要递归处理,所以需要写一个辅助函数帮助析构的递归处理部分
private:
void Destroy(Node* root)
{
if (root == nullptr) return;
Destroy(root->_left);
Destroy(root->_right);
delete root;
}
public:
~BSTree()
{
Destroy(_root);
_root = nullptr;
}
}; 1.2.2.3 插入数据
插入数据的逻辑也和K模型下的没有太大区别。首先要做的还是按左小右大的规则找到应该插入的位置,同样需要判断是否为空树以防止对空指针解引用。需要注意的是KV模型下key值被分离了出来,所以比较时需要->解引用拿到结点的key值再比较。
插入结点的函数返回值同样是一个bool值,标明是否成功插入。当树中已经存在待插入的key值,那么就会插入失败,返回false;其他成功插入的情况就返回true。注意,在此处key是唯一索引,所以能否插入成功只取决于有无重复的key,而与value无关。
//插入数据
//以key为指标,二叉搜索树左孩子比父亲小,右孩子比父亲大
//所以插入数据需要层层比较来找到合适的位置
bool Insert(const K& key, const V& value)
{
Node* newnode = new Node(key, value);
//如果是第一次插入,则根结点为空指针,需要特殊处理
if (_root == nullptr)
{
_root = newnode;
return true;
}
Node* parent = _root;
Node* cur = _root;
while (cur)
{
//二叉搜索树已经存在的值不会再插入
//所以结点值大于key,则向左子树找;结点值小于key,向右子树找;如果相等则不再插入,返回false
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else
{
return false;
}
}
if (parent->_key > key)
{
parent->_left = newnode;
}
else
{
parent->_right = newnode;
}
return true;
}1.2.2.4 查找结点
查找二叉树结点也是根据二叉搜索树左小右大的规则,取出结点中的key不断比较即可。
//查找搜索二叉树中是否存在key的结点
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
cur = cur->_left;
}
else if (cur->_key < key)
{
cur = cur->_right;
}
else
{
return true;
}
}
return false;
}1.2.2.5 删除数据
对于删除结点,key-value模型和key模型几乎一致,只需要注意在比较时通过->解引用取到key值即可。
//删除结点
//删除结点后,为了保证二叉搜索树的结构不变,则顶替该位置的结点key值应该大于左子树,小于右子树
//为了满足这一点,可以考虑找左子树最大值或右子树最小值
//因为右孩子一定比父结点大,所以左子树最大值只需要沿着左子树右孩子寻找到尽头即可
//同理,右子树最小值需要沿着右子树左孩子寻找到尽头
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else
{
//删除cur:
//1.cur左树为空(包括全空),直接将右树链在parent上
if (cur->_left == nullptr)
{
if (cur == _root)
{
_root = cur->_right;
}
else if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
delete cur;
return true;
}
//2.cur右树为空,直接将左树链在parent上
else if (cur->_right == nullptr)
{
if (cur == _root)
{
_root = cur->_left;
}
else if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
delete cur;
return true;
}
//3.cur两树均不为空,找左子树最大或右子树最小,与cur替换
else
{
//MaxLeft
Node* change_node = cur->_left;
Node* change_parent_node = cur;
while (change_node->_right)
{
change_parent_node = change_node;
change_node = change_node->_right;
}
//找到最大左树值与其父,为了方便,将最大值与cur值交换即可
cur->_key = change_node->_key;
//由于左树最大值是先找左孩子,再一直找右孩子,所以需要判断是左孩子还是右孩子
//并且左子树最大结点一定没有右孩子,但可能有左孩子,所以需要把左树的根结点链在最大结点父结点对应位置
if (change_parent_node->_left == change_node)
{
change_parent_node->_left = change_node->_left;
}
else
{
change_parent_node->_right = change_node->_left;
}
delete change_node;
return true;
}
}
}
return false;
}1.2.1.6 中序遍历
同样的,根据二叉搜索树的特性,对二叉搜索树中序遍历(左、根、右),可以得到一组升序排列的数据。
void Inorder()
{
//中序遍历需要递归,而且调用时不传参,所以需要单另将递归逻辑写出去
_Inorder(_root);
cout << endl;
}
void _Inorder(Node* root)
{
if (root == nullptr) return;
_Inorder(root->_left);
cout << root->_key << ' ' << root->_value << endl;
_Inorder(root->_right);
}