多数据源实现事务管理
目录
- 一. 原理-编程式事务管理
-
- 1.核心接口
-
- 1.1 PlatformTransactionManager
- 1.2 TransactionDefinition
-
- 隔离级别 IsolationLevel
-
- 常用状态分析:
- 读取现象
-
- 不可重复读和幻读比较:
- 隔离级别与读取现象
- 常见数据库默认隔离级别
- 传播性 Propagation
- 1.3 TransactionStatus
- 二、实现跨数据源事务
-
- 定义注解
- 定义切面
- 使用
一. 原理-编程式事务管理
想直接看实现的朋友,这部分可以直接跳过
1.核心接口
Spring 中对事务的处理,涉及到三个核心接口:
- PlatformTransactionManager
- TransactionDefinition
- TransactionStatus
这三个核心类是Spring处理事务的核心类。
1.1 PlatformTransactionManager
public interface PlatformTransactionManager {
TransactionStatus getTransaction(TransactionDefinition var1) throws TransactionException;
void commit(TransactionStatus var1) throws TransactionException;
void rollback(TransactionStatus var1) throws TransactionException;
}
可以看到 PlatformTransactionManager 中定义了基本的事务操作方法,这些事务操作方法都是平台无关的,具体的实现都是由不同的子类来实现的。PlatformTransactionManager 中主要有如下三个方法:
-
getTransaction()
getTransaction() 是根据传入的 TransactionDefinition 获取一个事务对象,TransactionDefinition 中定义了一些事务的基本规则,例如传播性、隔离级别等。 -
commit()
commit() 方法用来提交事务。 -
rollback()
rollback() 方法用来回滚事务。
1.2 TransactionDefinition
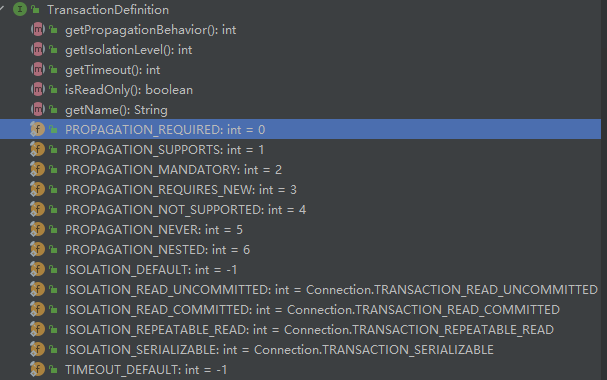
可以看到一共有五个方法:
- getIsolationLevel(),获取事务的隔离级别
- getName(),获取事务的名称
- getPropagationBehavio(),获取事务的传播性
- getTimeout(),获取事务的超时时间
- isReadOnly(),获取事务是否是只读事务
我们可以从这些个方法中, 很直观的感受到这个类的作用:设置事务的属性。接下来,我重点结束几个属性的意义。
隔离级别 IsolationLevel
常用状态分析:
-
ReadUncommitted
表示:未提交读。当事务A更新某条数据的时候,不容许其他事务来更新该数据,但可以进行读取操作
-
ReadCommitted
- 表示:提交读。当事务A更新数据时,不容许其他事务进行任何的操作包括读取,但事务A读取时,其他事务可以进行读取、更新。
- 在Read Committed隔离级别下,一个事务只能读取到已经提交的数据。当多个事务同时读取同一数据时,如果有其他事务正在对该数据进行修改但尚未提交,则读取操作将等待,直到修改完成并提交后才能读取到最新的数据。
- 这意味着在Read Committed级别下,事务读取的数据是实时更新的,但可能会出现不一致的读取结果。
-
RepeatableRead
- 表示:重复读。当事务A更新数据时,不容许其他事务进行任何的操作,但是当事务A进行读取的时候,其他事务只能读取,不能更新。
- 在Repeatable Read隔离级别下,一个事务在开始读取数据后,任何其他事务对该数据的修改都不会被读取到,即使这些修改已经提交。事务在整个过程中都能看到一致的数据快照。
- 这意味着在Repeatable Read级别下,事务读取的数据是一致的,不会受到其他并发事务的修改的影响,确保了事务的独立性和稳定性。
-
Serializable
表示:序列化。最严格的隔离级别,当然并发性也是最差的,事务必须依次进行。
读取现象
通过一些现象,可以反映出隔离级别的效果。这些现象有:
- 更新丢失(lost update):当系统允许两个事务同时更新同一数据时,发生更新丢失。
- 脏读(dirty read):当一个事务读取另一个事务尚未提交的修改时,产生脏读。
比如:事务B执行过程中修改了数据X,在未提交前,事务A读取了X,而事务B却回滚了,这样事务A就形成了脏读。
- 不重复读(nonrepeatable read):同一查询在同一事务中多次进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集,此时发生非重复读。(A transaction rereads data it has previously read and finds that another committed transaction has modified or deleted the data. )。
比如:事务A首先读取了一条数据,然后执行逻辑的时候,事务B将这条数据改变了,然后事务A再次读取的时候,发现数据不匹配了,就是所谓的不可重复读了。
- 幻读(phantom read):同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻像读。(A transaction reexecutes a query returning a set of rows that satisfies a search condition and finds that another committed transaction has inserted additional rows that satisfy the condition. )。
比如:事务A首先根据条件索引得到N条数据,然后事务B改变了这N条数据之外的M条或者增添了M条符合事务A搜索条件的数据,导致事务A再次搜索发现有N+M条数据了,就产生了幻读。
不可重复读和幻读比较:
两者有些相似,但是前者针对的是update或delete,后者针对的insert。
为什么会出现“脏读”?因为没有“select”操作没有规矩。
为什么会出现“不可重复读”?因为“update”操作没有规矩。
为什么会出现“幻读”?因为“insert”和“delete”操作没有规矩。
隔离级别与读取现象
| 隔离级别 | 脏读 Dirty Read | 不可重复读取 NonRepeatable Read | 幻读 Phantom Read |
|---|---|---|---|
| 未授权读取/未提交读 read uncommitted | 可能发生 | 可能发生 | 可能发生 |
| 授权读取/提交读 read committed | - | 可能发生 | 可能发生 |
| 重复读 read repeatable | - | - | 可能发生 |
| 序列化 serializable | - | - | - |
常见数据库默认隔离级别
| 数据库 | 默认隔离级别 |
|---|---|
| Oracle | read committed |
| SqlServer | read committed |
| MySQL(InnoDB) | Read-Repeatable |
传播性 Propagation
1、PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
2、PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作
3、PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。‘
4、PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
5、PROPAGATION_REQUIRES_NEW:支持当前事务,创建新事务,无论当前存不存在事务,都创建新事务。
6、PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
7、PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
1.3 TransactionStatus
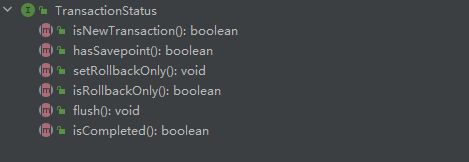
- isNewTransaction() 方法获取当前事务是否是一个新事务。
- hasSavepoint() 方法判断是否存在 savePoint(),即是否已创建为基于保存点的嵌套事务。此方法主要用于诊断目的,与isNewTransaction()一起使用。对于自定义保存点的编程处理,请使用SavepointManager提供的操作。
- setRollbackOnly() 方法设置事务必须回滚。
- isRollbackOnly() 方法获取事务只能回滚。
- flush() 方法将底层会话中的修改刷新到数据库,一般用于 Hibernate/JPA 的会话,对如 JDBC 类型的事务无任何影响。
- isCompleted() 方法用来获取是一个事务是否结束,即是否已提交或回滚。
表示事务的状态。
事务代码可以使用它来检索状态信息,并以编程方式请求回滚(而不是引发导致隐式回滚的异常)。
二、实现跨数据源事务
先说一下两阶段提交:首先多个数据源的事务分别都开起来,然后各事务分别去执行对应的sql(此所谓第一阶段提交),最后如果都成功就把事务全部提交,只要有一个失败就把事务都回滚——此所谓第二阶段提交。
Transactional注解只能指定一个数据源的事务管理器。我们重新定义一个,让它支持指定多个数据源的事务管理器,然后我们在使用了这个注解的方法前后进行所谓的两阶段协议,而这可以通过AOP来完成。所以,代码如下:
定义注解
/**
* 多数据源事务注解
*
*/
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface MultiDataSourceTransactional {
/**
* 事务管理器数组
*/
String[] transactionManagers();
}
定义切面
我们使用Spring的Aspect来完成切面。
先来回顾一下它的切入点
@Before: 标识一个前置增强方法,相当于BeforeAdvice的功能。
@After: 后置增强,不管是抛出异常或者正常退出都会执行。
@AfterReturning: 后置增强,似于AfterReturningAdvice, 方法正常退出时执行。
@AfterThrowing: 异常抛出增强,相当于ThrowsAdvice。
@Around: 环绕增强,相当于MethodInterceptor。
咋一看,@Around是可以的:ProceedingJoinPoint的proceed方法是执行目标方法,在它前面声明事务,try…catch…一下如果有异常就回滚没异常就提交。不过,最开始用这个的时候,好像发现有点问题,具体记不住了,大家可以试一下。因为当时工期紧没仔细研究,就采用了下面这种
@Before + @AfterReturning + @AfterThrowing组合,看名字和功能简直是完美契合啊!但是有一个问题,不同方法怎么共享那个事务呢?成员变量?对,没错。但是又有线程安全问题咋办?ThreadLocal帮你解决(_)。
/**
* 编程式事务 基本过程:
* 1.TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
* 首先通过transactionManager.getTransaction方法获取事务对象status,
* 2.transactionManager.commit(status);
* 然后在try块中执行数据库操作,最后通过transactionManager.commit(status)提交事务。
* 3.transactionManager.rollback(status);
* 如果在数据库操作中发生了异常,则会通过transactionManager.rollback(status)回滚事务。
*
*/
@Component
@Aspect
public class MultiDataSourceTransactionAspect implements ApplicationContextAware {
/**
* 线程本地变量:为什么使用栈?※为了达到后进先出的效果※
*/
private static final ThreadLocal<Stack<Pair<DataSourceTransactionManager, TransactionStatus>>> THREAD_LOCAL = new ThreadLocal<>();
/**
* 事务声明
*/
private DefaultTransactionDefinition def = new DefaultTransactionDefinition();
{
// 非只读模式
def.setReadOnly(false);
//事务隔离级别 采用数据库默认的
def.setIsolationLevel(DefaultTransactionDefinition.ISOLATION_DEFAULT);
//事务传播行为 - 创建一个新的事务,并在该事务中执行;如果当前存在事务,则将当前事务挂起。
def.setPropagationBehavior(DefaultTransactionDefinition.PROPAGATION_REQUIRES_NEW);
}
/**
* implements ApplicationContextAware ==> 获取spring容器
*/
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
/**
* 设置切入点
*/
@Pointcut("@annotation(com.example.mutidatasource.dataSource.multiDataSourceTransaction.MultiDataSourceTransactional)")
public void pointcut(){}
/**
* 声明事务
*
* 冗余了,pointcut() 、 @annotation(transactional) 语义一致
* 但是 不加上这个@annotation(transactional) 报错, before() 方法期望有一个 MultiDataSourceTransactional 类型的参数,
* 虽然pointcut() 确定了有这个注解,但是编辑器不知道啊
*/
@Before("pointcut() && @annotation(transactional)")
public void before(MultiDataSourceTransactional transactional){
//根据设置的事务名称按顺序声明,并放到ThreadLocal里
String[] TransactionalNames = transactional.value();
Stack<Pair<DataSourceTransactionManager, TransactionStatus>> pairStack = new Stack<>();
for (String transactionalName : TransactionalNames) {
// 从容器中获取 数据库事务管理器
DataSourceTransactionManager manager = applicationContext.getBean(transactionalName, DataSourceTransactionManager.class);
TransactionStatus status = manager.getTransaction(def);
pairStack.push(new Pair<>(manager,status));
}
THREAD_LOCAL.set(pairStack);
}
/**
* 提交事务
*
* @AfterReturning 和 @After 都是 Spring AOP 框架提供的注解,用于在方法执行后执行某些操作。但是,它们之间有一些关键的区别:
*
* @AfterReturning 仅在方法正常返回时执行,而 @After 总是在方法执行后执行,无论方法是否正常返回。
* @AfterReturning 可以访问方法的返回值,而 @After 则不能。
* @AfterReturning 可以通过 returning 属性指定要访问的返回值的名称,而 @After 则不能。
*/
@AfterReturning("pointcut()")
public void afterReturning(){
// ※栈顶弹出(后进先出)
Stack<Pair<DataSourceTransactionManager, TransactionStatus>> pairStack = THREAD_LOCAL.get();
while (!pairStack.empty()) {
Pair<DataSourceTransactionManager, TransactionStatus> pair = pairStack.pop();
// 提交事务 transactionManager.commit(status);
pair.getKey().commit(pair.getValue());
}
THREAD_LOCAL.remove();
}
/**
* 回滚事务
*
*
*/
@AfterThrowing("pointcut()")
public void afterThrowing(){
// ※栈顶弹出(后进先出)
Stack<Pair<DataSourceTransactionManager, TransactionStatus>> pairStack = THREAD_LOCAL.get();
while (!pairStack.empty()) {
Pair<DataSourceTransactionManager, TransactionStatus> pair = pairStack.pop();
// 提交事务 transactionManager.commit(status);
pair.getKey().rollback(pair.getValue());
}
THREAD_LOCAL.remove();
}
}
使用
/**
* 测试多数据源事务
*/
@MultiDataSourceTransactional(transactionManagers={"ATransactionManager","BTransactionManager"})
public void testTransaction() {
}