Python3多进程multiprocessing模块的使用
一、概念
在使用multiprocessing库实现多进程之前,我们先来了解一下操作系统相关的知识。
-
Unix/Linux实现多进程
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前父进程复制了一份子进程,然后,分别在父进程和子进程内返回。子进程永远返回0,而父进程返回子进程的ID。这样,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
-
Windows的多进程
由于Windows没有fork调用,而如果我们需要在Windows上用Python编写多进程的程序。我们就需要使用到multiprocessing模块。
二、多进程的使用
Windows下multiprocessing模块实现多进程
multiprocessing支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。这里我们只是介绍一下Process组件和Queue组件。
- Process
在multiprocessing中,每一个进程都用一个Process类来表示。
# 参数
multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={})
- group:分组,实际上很少使用
- target:表示调用对象,你可以传入方法的名字
- name:别名,相当于给这个进程取一个名字
- args:表示被调用对象的位置参数元组,比如target是函数a,他有两个参数m,n,那么args就传入(m, n)即可
- kwargs:表示调用对象的字典
- 简单的使用
import time
from multiprocessing import Process
import os
def run(name):
while True:
time.sleep(2)
print("子进程ID号:%d,run:%s" % (os.getpid(), name)) # os.getpid()进程ID
if __name__ == "__main__":
print("父进程启动:%d" % os.getpid())
# 创建子进程
p = Process(target=run, args=("Ail",)) # target进程执行的任务, args传参数(元祖)
p.start() # 启动进程
while True:
print("死循环")
time.sleep(1)
# 输出结果
主进程启动:36684
死循环
死循环
死循环
子进程ID号:40228,run:Ail
死循环
创建子进程一定要在主进程没有执行死循环的时候创建,不然子进程无法创建
启动程序,我们再去任务管理器根据进程的ID去看一下我们同时运行的两个进程
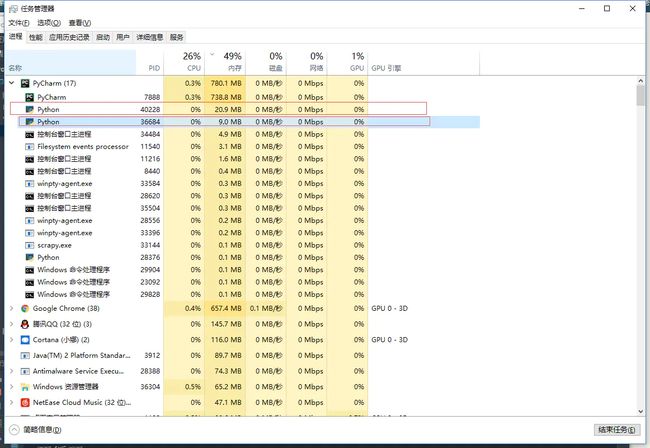
任务管理器
另外你还可以通过 cpu_count() 方法还有 active_children() 方法获取当前机器的 CPU 核心数量以及得到目前所有的运行的进程。
import multiprocessing
import time
def process(num):
print("Process:%d" % num)
if __name__ == '__main__':
for i in range(8):
p = multiprocessing.Process(target=process, args=(i,))
p.start()
print('CPU核心数量:' + str(multiprocessing.cpu_count())) # 查看当前机器CPU核心数量
# 目前所有的运行的进程
for p in multiprocessing.active_children():
print('子进程名称: ' + p.name + ' id: ' + str(p.pid))
print('进程结束')
# 输出结果
CPU核心数量:8
子进程名称: Process-8 id: 40184
子进程名称: Process-5 id: 40764
子进程名称: Process-2 id: 21916
子进程名称: Process-6 id: 40432
子进程名称: Process-3 id: 23128
子进程名称: Process-7 id: 40016
子进程名称: Process-1 id: 5072
子进程名称: Process-4 id: 18264
进程结束
Process:2
Process:1
Process:6
Process:0
Process:4
Process:5
Process:3
Process:7
进程已结束,退出代码0
- 父子进程的先后顺序
继续通过代码来观察父子进程的先后顺序
import time
from multiprocessing import Process
import os
def run():
print("子进程开启")
time.sleep(2)
print("子进程结束")
if __name__ == "__main__":
print("父进程启动")
p = Process(target=run)
p.start()
print("父进程结束")
# 输出结果
父进程启动
父进程结束
子进程开启
子进程结束
父进程的结束不能影响子进程。但这样有会出现一个问题,我们有时候会需要父进程等待子进程结束再执行父进程后面的代码
所以我们需要使用到了join()方法,继续来看上面那段代码,加入join()方法
import time
from multiprocessing import Process
import os
def run():
print("子进程开启")
time.sleep(2)
print("子进程结束")
if __name__ == "__main__":
print("父进程启动")
p = Process(target=run)
p.start()
p.join() # 等待子进程结束后,再往下执行
print("父进程结束")
# 输出结果
父进程启动
子进程开启
子进程结束
父进程结束
既然要等到子进程结束后再执行父进程的后续部分,那么是不是感觉到这样多进程就没什么用了?其实不然,一般情况下我们的父进程是不会执行任何其它操作的,它会创建多个子进程来进行任务的处理。当这些子进程全部结束完成后,我们再关闭我们的父进程。
- 全局变量在多个进程中不能共享
from multiprocessing import Process
from time import sleep
num = 100
def run():
print("子进程开始")
global num
num += 1
print("子进程num:%d" % num)
print("子进程结束")
if __name__ == "__main__":
print("父进程开始")
p = Process(target=run)
p.start()
p.join()
# 在子进程中修改全局变量对父进程中的全局变量没有影响
print("父进程结束。num:%s" % num)
# 输出结果
父进程开始
子进程开始
子进程num:101
子进程结束
父进程结束。num:100
在子进程中修改全局变量对父进程中的全局变量没有影响。因为父进程在创建子进程时对全局变量做了一个备份,父进程中的全局变量与子进程的全局变量完全是不同的两个变量。全局变量在多个进程中不能共享
- Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程
import random
from multiprocessing.pool import Pool
from time import sleep, time
import os
def run(name):
print("%s子进程开始,进程ID:%d" % (name, os.getpid()))
start = time()
sleep(random.choice([1, 2, 3, 4]))
end = time()
print("%s子进程结束,进程ID:%d。耗时0.2%f" % (name, os.getpid(), end-start))
if __name__ == "__main__":
print("父进程开始")
# 创建多个进程,表示可以同时执行的进程数量。默认大小是CPU的核心数
p = Pool(8)
for i in range(10):
# 创建进程,放入进程池统一管理
p.apply_async(run, args=(i,))
# 如果我们用的是进程池,在调用join()之前必须要先close(),并且在close()之后不能再继续往进程池添加新的进程
p.close()
# 进程池对象调用join,会等待进程吃中所有的子进程结束完毕再去结束父进程
p.join()
print("父进程结束。")
# 输出结果
父进程开始
0子进程开始,进程ID:41380
1子进程开始,进程ID:44756
2子进程开始,进程ID:31936
3子进程开始,进程ID:32000
3子进程结束,进程ID:32000。耗时0.21.000601
4子进程开始,进程ID:32000
0子进程结束,进程ID:41380。耗时0.22.000833
5子进程开始,进程ID:41380
2子进程结束,进程ID:31936。耗时0.23.000310
1子进程结束,进程ID:44756。耗时0.24.000483
4子进程结束,进程ID:32000。耗时0.23.000789
5子进程结束,进程ID:41380。耗时0.23.000035
-
Pool(8):创建多个进程,表示可以同时执行的进程数量。默认大小是CPU的核心数果。
-
join():进程池对象调用join,会等待进程池中所有的子进程结束完毕再去结束父进程
-
close():如果我们用的是进程池,在调用join()之前必须要先close(),并且在close()之后不能再继续往进程池添加新的进程
因为我们Pool(4)指定了同时最多只能执行4个进程(Pool进程池默认大小是CPU的核心数),但是我们放入了6个进程进入我们的进程池,所以程序一开始就会只开启4个进程。
注意:子进程执行是没有顺序的,先执行哪个子进程操作系统说了算的。而且进程的创建和销毁也是非常消耗资源的,所以如果进行一些本来就不需要多少耗时的任务你会发现多进程甚至比单进程还要慢
- 进程间的通信
现在有这样一个需求:我们有两个进程,一个进程负责写(write)一个进程负责读(read)。当写的进程写完某部分以后要把数据交给读的进程进行使用
这时候我们就需要使用到了multiprocessing模块的Queue(队列):write()将写完的数据交给队列,再由队列交给read()
from multiprocessing import Process, Queue
import os, time
def write(q):
print("启动Write子进程:%s" % os.getpid())
for i in ["A", "B", "C", "D"]:
q.put(i) # 写入队列
time.sleep(1)
print("结束Write子进程:%s" % os.getpid())
def read(q):
print("启动Write子进程:%s" % os.getpid())
while True: # 阻塞,等待获取write的值
value = q.get(True)
print(value)
print("结束Write子进程:%s" % os.getpid()) # 不会执行
if __name__ == "__main__":
# 父进程创建队列,并传递给子进程
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
pw.start()
pr.start()
pw.join()
# pr进程是一个死循环,无法等待其结束,只能强行结束(写进程结束了,所以读进程也可以结束了)
pr.terminate()
print("父进程结束")
# 输出结果:
启动Write子进程:29564
启动Write子进程:22852
A
B
C
D
结束Write子进程:22852
父进程结束
pr进程是一个死循环,无法等待其结束,只能强行结束
- 自定义进程类
from multiprocessing import Process
import time
import os
class MyProcess(Process):
def __init__(self, name):
Process.__init__(self)
self.name = name
def run(self):
print("子进程(%s-%s)启动" % (self.name, os.getpid()))
time.sleep(3)
print("子进程(%s-%s)结束" % (self.name, os.getpid()))
if __name__ == '__main__':
print("父进程启动")
p = MyProcess("Ail")
# 自动调用MyProcess的run()方法
p.start()
p.join()
print("父进程结束")
# 输出结果
父进程启动
子进程(Ail-38512)启动
子进程(Ail-38512)结束
父进程结束
自定义进程类,继承Process类,重写run方法就可以了
作者:艾胖胖胖
链接:https://www.jianshu.com/p/a5f10c152c20
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。