GLM-4 (1) - 推理+概览
系列文章目录
GLM-4 (1) - 推理+概览
GLM-4 (2) - RoPE
GLM-4 (3) - GLMBlock
GLM-4 (4) - SelfAttention
GLM-4 (5) - API & Function Calling
GLM-4 (6) - KV Cache / Prefill & Decode
文章目录
- 系列文章目录
- 前言
- 一、环境安装 & 跑通demo
- 二、Tokenizer
- 三、configs
-
- model config
- generation config
- 四、model外林林总总
-
- StoppingCriteria & StoppingCriteriaList
- TextStreamer & TextIteratorStreamer
- tokenizer.apply_chat_template()
- left padding
- prepare_inputs_for_generation() & kv_cache
- 总结
前言
GLM-4出来有一段时间了,下图是官方提供的一组模型。这边以选择了glm-4-9b-chat,希望通过跑demo和debug源码的形式,对GLM-4进行较为全面的理解。本篇主要内容包括:跑通demo、理解模型相关文件(尤其是配置文件),以及涉及到transformers库中的一些组件的用法。模型架构部分会在后续分成旋转位置编码RoPE、GLMBlock、自注意力SelfAttention等部分来讲述。
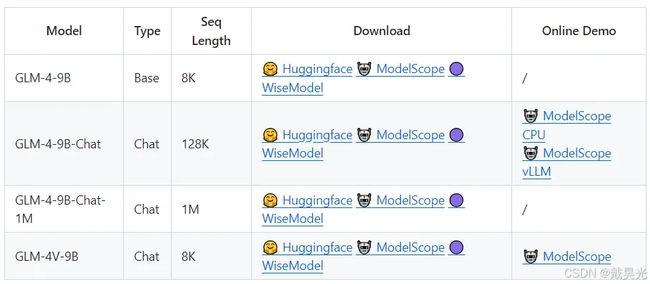
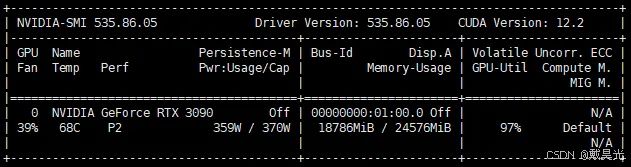
一、环境安装 & 跑通demo
- 使用3090,完全按照
basic_demo/requirements.txt的要求安装依赖; - 下载模型文件,
huggingface可能下载不下来,可以换成hf-mirror或者modelscope进行下载:
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/glm-4-9b-chat.git
- 修改文件如
trans_cli_demo.py中的MODEL_PATH:
# 修改前
# MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/glm-4-9b-chat')
# 修改后(为本地路径,也就是clone的model文件的路径)
MODEL_PATH = os.environ.get('MODEL_PATH', '/home/ubuntu/Projects_ubuntu/glm-4-9b-chat')
- 运行
trans_cli_demo.py文件,查看显存占用约为18GB。
二、Tokenizer
Tokenizer主要由如下文件决定:
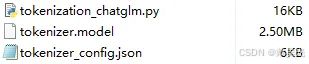
tokenization_chatglm.py:构建ChatGLM4Tokenizer,继承自PreTrainedTokenizer,使用tiktoken来分词;tokenizer.model:词汇文件,为ChatGLM4Tokenizer所用;tokenizer_config.json:包含了一些配置,比如special_tokens,tokenizer_class等等。
以下是tokenizer_config.json的具体配置:
// tokenizer_config.json`在这里插入代码片`
{
"auto_map": {
"AutoTokenizer": [
"tokenization_chatglm.ChatGLM4Tokenizer",
null
]
},
"added_tokens_decoder": {
"151329": {
"content": "<|endoftext|>",
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151330": {
"content": "[MASK]", // 短跨度掩盖(采样),短的完形填空
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151331": {
"content": "[gMASK]", // 掩盖一个长的跨度,用于从左向右生成
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151332": {
"content": "[sMASK]", // 用于句子填空
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151333": {
"content": "" , // 一个片段的开始
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151334": {
"content": "" , // 一个片段的结束
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151335": {
"content": "<|system|>", // 系统角色输入前缀
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151336": {
"content": "<|user|>", // 用户输入前缀
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151337": {
"content": "<|assistant|>", // 助手角色(大模型)输入前缀
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151338": {
"content": "<|observation|>",
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151339": {
"content": "<|begin_of_image|>",
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151340": {
"content": "<|end_of_image|>",
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151341": {
"content": "<|begin_of_video|>",
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
},
"151342": {
"content": "<|end_of_video|>",
"lstrip": false,
"normalized": false,
"rstrip": false,
"single_word": false,
"special": true
}
},
"additional_special_tokens": ["<|endoftext|>", "[MASK]", "[gMASK]", "[sMASK]", "" , "" , "<|system|>",
"<|user|>", "<|assistant|>", "<|observation|>", "<|begin_of_image|>", "<|end_of_image|>",
"<|begin_of_video|>", "<|end_of_video|>"],
"clean_up_tokenization_spaces": false,
"chat_template": "[gMASK]{% for item in messages %}{% if item['tools'] is defined %}<|system|>\n你是一个名为 GLM-4 的人工智能助手。你是基于智谱AI训练的语言模型 GLM-4 模型开发的,你的任务是针对用户的问题和要求提供适当的答复和支持。\n\n# 可用工具{% set tools = item['tools'] %}{% for tool in tools %}{% if tool['type'] == 'function' %}\n\n## {{ tool['function']['name'] }}\n\n{{ tool['function'] | tojson(indent=4) }}\n在调用上述函数时,请使用 Json 格式表示调用的参数。{% elif tool['type'] == 'python' %}\n\n## python\n\n当你向 `python` 发送包含 Python 代码的消息时,该代码将会在一个有状态的 Jupyter notebook 环境中执行。\n`python` 返回代码执行的输出,或在执行 60 秒后返回超时。\n`/mnt/data` 将会持久化存储你的文件。在此会话中,`python` 无法访问互联网。不要使用 `python` 进行任何网络请求或者在线 API 调用,这些在线内容的访问将不会成功。{% elif tool['type'] == 'simple_browser' %}\n\n## simple_browser\n\n你可以使用 `simple_browser` 工具。该工具支持以下函数:\n`search(query: str, recency_days: int)`:使用搜索引擎进行查询并显示结果,可以使用 `recency_days` 参数控制搜索内容的时效性。\n`mclick(ids: list[int])`:获取一系列指定 id 的页面内容。每次调用时,须选择3-10个页面。选择多个角度的页面,同时尽可能选择可信任的信息来源。考虑到部分页面是无法加载的,你也可以多打开一些可能有用的页面而不用担心内容过多。\n`open_url(url: str)`:打开指定的 URL。\n\n使用 `【{引用 id}†{引用文本}】` 来引用内容。\n\n操作步骤:1. 使用 `search` 来获得信息列表; 2. 使用 `mclick` 来获取指定 ID 页面的内容; 3. 根据获得的内容进行回复。在回复中应当引用信息来源。\n 如果用户提供了 URL,也可以用 `open_url` 直接打开页面。\n如果初次搜索结果没有找到合适的信息,也可以再次使用 `search` 进行搜索。{% elif tool['type'] == 'cogview' %}\n\n## cogview\n\n如果用户的请求中包含了对图像的描述,你可以使用 `cogview` 来生成图像并展示给用户。你需要向 `cogview` 发送图像描述,规则:\n- 发送给 `cogview` 的消息必须使用英语。用户的中文描述必须完全翻译为英语。\n- 应当尽可能详细地描述图像生成的需求,需求描述约 100 英文单词。\n- 保持用户原始描述的意图。不要虚构内容或者没见过的人物。\n- 如无特殊说明,所在地为中国,持有中国立场并遵循中国社会主义价值观。{% endif %}{% endfor %}{% endif %}{% if item['content'] %}<|{{ item['role'] }}|>{{ item['metadata'] }}\n{{ item['content'] }}{% endif %}{% endfor %}{% if add_generation_prompt %}<|assistant|>{% endif %}" ,
"do_lower_case": false,
"eos_token": "<|endoftext|>",
"pad_token": "<|endoftext|>",
"model_max_length": 128000,
"padding_side": "left",
"remove_space": false,
"tokenizer_class": "ChatGLM4Tokenizer"
}
主要包含内容为:
- 一些添加的特殊token,我已经做了注释,参考GLM-130B README、GLM、ChatGLM3/issues/183;
chat_template:完成chat时遵从此模板;padding_side:这边是left,对于decode-only的架构来说,一般需要选择left,而不是像Bert这种是right。原因在于它是生成模型,在batch generation的时候,如果使用了left padding,那么batch上token的index全部对齐了;而如果使用right padding的话,显然在生成的token之前夹带了很多pad token,这是不合理的。具体的也可以参考这篇文章。
三、configs
model config
模型配置主要由configuration_chatglm.py和config.json决定。其中configuration_chatglm.py给出了类ChatGLMConfig的定义,而config.json则给出了对应glm4-9b-chat的真实参数。
为了对模型整体有一个认识,这边贴出具体的配置:
# configuration_chatglm.py
from transformers import PretrainedConfig
class ChatGLMConfig(PretrainedConfig):
model_type = "chatglm"
"""
以下参数会注释含义,并且针对glm_4_9b_chat会给出它的参数值
"""
def __init__(
self,
num_layers=28, # transformer层数,40
padded_vocab_size=65024, # (经过填充后)词汇表大小,151552
hidden_size=4096, # 隐藏层大小
ffn_hidden_size=13696, # ffn隐藏层大小,这里ffn_hidden_size != 4 * hidden_size
kv_channels=128, # key-value键值对通道数, = hidden_size / num_attention_heads
num_attention_heads=32, # 注意力头个数
seq_length=2048, # 序列长度,131072 (128k)
hidden_dropout=0.0, # 在tranformer block (GLMBlock)中attention和mlp之后的dropout
classifier_dropout=None,
attention_dropout=0.0, # attention内部的dropout
layernorm_epsilon=1e-5, # layernorm eps,1.5625e-07
rmsnorm=True, # 使用rmsnorm替代layernorm作为归一化函数
apply_residual_connection_post_layernorm=False, # 是否在归一化层之后添加残差连接(在layernorm之前(即hidden_states后)添加还是之后添加)
post_layer_norm=True, # 在layers(多层GLMBlock)之后添加归一化层
add_bias_linear=False, # 线性层中是否添加偏置
add_qkv_bias=False, # 是否添加qkv线性层的偏置,True
bias_dropout_fusion=True,
multi_query_attention=False, # 是否使用多查询注意力,True
multi_query_group_num=1, # 多查询注意力中的查询组数,2
rope_ratio=1, # rope_ratio,与base相乘,500 -是不是和seq_length相关?
apply_query_key_layer_scaling=True, # 是否对注意力机制中的查询和键进行缩放处理。缩放系数跟所在layer的层数相关,最后attention_score乘以该系数
attention_softmax_in_fp32=True, # 在计算注意力分数softmax的时候,是否使用fp32精度
fp32_residual_connection=False, # 残差连接是否使用fp32
**kwargs
):
self.num_layers = num_layers
self.vocab_size = padded_vocab_size
self.padded_vocab_size = padded_vocab_size
self.hidden_size = hidden_size
self.ffn_hidden_size = ffn_hidden_size
self.kv_channels = kv_channels
self.num_attention_heads = num_attention_heads
self.seq_length = seq_length
self.hidden_dropout = hidden_dropout
self.classifier_dropout = classifier_dropout
self.attention_dropout = attention_dropout
self.layernorm_epsilon = layernorm_epsilon
self.rmsnorm = rmsnorm
self.apply_residual_connection_post_layernorm = apply_residual_connection_post_layernorm
self.post_layer_norm = post_layer_norm
self.add_bias_linear = add_bias_linear
self.add_qkv_bias = add_qkv_bias
self.bias_dropout_fusion = bias_dropout_fusion
self.multi_query_attention = multi_query_attention
self.multi_query_group_num = multi_query_group_num
self.rope_ratio = rope_ratio
self.apply_query_key_layer_scaling = apply_query_key_layer_scaling
self.attention_softmax_in_fp32 = attention_softmax_in_fp32
self.fp32_residual_connection = fp32_residual_connection
super().__init__(**kwargs)
generation config
是一些和token生成相关的参数,存放在generation_config.json中,如下所示:
// generation_config.json
{
"eos_token_id": [
151329, // "<|endoftext|>"
151336, // ""
151338 // ""
],
"pad_token_id": 151329,
"do_sample": true, // 采样
"temperature": 0.8,
"max_length": 128000,
"top_p": 0.8,
"transformers_version": "4.40.2"
}
四、model外林林总总
大模型各自的模型架构和实现会有一些差异,但是初次之外,总的流程都是一致的,并且这一部分被transformers等这些库很好的集成了。我们这边就来谈谈这些东西,这部分内容主要集中在trans_cli_demo.py文件中。
StoppingCriteria & StoppingCriteriaList
用户控制停止输出的标准,需要继承自StoppingCriteria,并重写__call__方法,必要时可以重写__init__方法,以便传入一些参数,比如这篇博客。input_ids的shape应该是(batch_size, seq_length)。
class StopOnTokens(StoppingCriteria):
"""
遇到终止符就自己停止
"""
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = model.config.eos_token_id
for stop_id in stop_ids:
if input_ids[0][-1] == stop_id: # 比如 model_inputs.shape = [1, 8] 即 [batch_size, seq_len]
return True
return False
StoppingCriteriaList是一个列表/容器,里面可以添加各种StoppingCriteria,只要其中一个满足停止条件,就认为这个样本可以停止输出了。源码:
class StoppingCriteriaList(list):
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
# 默认填充False,shape: (batch_size, ),表示每个样本都还不能停止输出
is_done = torch.full((input_ids.shape[0],), False, device=input_ids.device)
for criteria in self:
is_done = is_done | criteria(input_ids, scores, **kwargs)
# 返回停止张量
return is_done
@property
def max_length(self) -> Optional[int]:
# 返回最大长度限制,如果都不是相应的类的实例,返回None
for stopping_criterium in self:
if isinstance(stopping_criterium, MaxLengthCriteria):
return stopping_criterium.max_length
elif isinstance(stopping_criterium, MaxNewTokensCriteria):
return stopping_criterium.max_length
return None
TextStreamer & TextIteratorStreamer
流式输出(Streaming Output)是一种数据传输方式,允许数据以连续的流的形式被处理和消费,这在处理大型文件、实时数据流或任何无法一次性加载到内存中的大量数据时非常有用。在NLP中用于提升用户体验。
TextStreamer是一个用于将生成的文本流式传输到控制台或其他输出设备的类。它可以与 transformers库中的生成模型一起使用,以实时显示生成的文本。
TextIteratorStreamer是一个生成器,用于逐个 token 地处理和输出文本。与TextStreamer不同,它不是直接输出到控制台,而是生成 token 序列,可以用于进一步的处理或分析。通常配合generate一起使用。
# modeling_chatglm.py
streamer = TextIteratorStreamer(
tokenizer=tokenizer,
# timeout=60, # 如果timeout不传参,就会一直阻塞,这适合我们debug的时候使用
timeout=None,
skip_prompt=True,
skip_special_tokens=True
)
generate_kwargs = {
"input_ids": model_inputs,
"streamer": streamer, # 这边传入streamer
"max_new_tokens": max_length,
"do_sample": True,
"top_p": top_p,
"temperature": temperature,
"stopping_criteria": StoppingCriteriaList([stop]),
"repetition_penalty": 1.2,
"eos_token_id": model.config.eos_token_id,
}
t = Thread(target=model.generate, kwargs=generate_kwargs)
t.start()
print("GLM-4:", end="", flush=True)
for new_token in streamer: # 流式输出
if new_token:
print(new_token, end="", flush=True)
history[-1][1] += new_token
tokenizer.apply_chat_template()
当使用chat的时候,transformers提供了将对话转成token的方式tokenizer.appy_chat_template,案例参见此链接,add_generation_prompt=True:(文档中解释为Whether to end the prompt with the token(s) that indicate the start of an assistant message)。也就是说添加了模型开始答复的标记,比如<|im_start|>assistant,但并不是每个模型都需要的。
model_inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True, # 添加模型开始答复的标记
tokenize=True, # 将message变成token,否则就是一串字符串
return_tensors="pt"
).to(model.device)
apply_chat_template()是class PreTrainedTokenizerBase的方法,模块路径为:transformers/tokenization_utils_base.py。
# tokenization_utils_base.py
@add_end_docstrings(INIT_TOKENIZER_DOCSTRING)
class PreTrainedTokenizerBase(SpecialTokensMixin, PushToHubMixin):
# ...省略
def apply_chat_template(
self,
conversation: Union[List[Dict[str, str]], List[List[Dict[str, str]]], "Conversation"],
chat_template: Optional[str] = None,
add_generation_prompt: bool = False,
tokenize: bool = True,
padding: bool = False,
truncation: bool = False,
max_length: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_dict: bool = False,
tokenizer_kwargs: Optional[Dict[str, Any]] = None,
**kwargs,
) -> Union[str, List[int], List[str], List[List[int]], BatchEncoding]:
# ...
# 这边chat_template很可能是None,但是根据模型初始化,配置中会传入相关参数,
# self.chat_template就是配置文件中的"chat_template",随后会将self.chat_template赋值给chat_template
# Compilation function uses a cache to avoid recompiling the same template
compiled_template = self._compile_jinja_template(chat_template) # 一个对象
# ...
pass
@lru_cache
def _compile_jinja_template(self, chat_template):
try:
import jinja2
from jinja2.exceptions import TemplateError
from jinja2.sandbox import ImmutableSandboxedEnvironment
except ImportError:
raise ImportError("apply_chat_template requires jinja2 to be installed.")
if version.parse(jinja2.__version__) < version.parse("3.0.0"):
raise ImportError(
"apply_chat_template requires jinja2>=3.0.0 to be installed. Your version is " f"{jinja2.__version__}."
)
def raise_exception(message):
raise TemplateError(message)
jinja_env = ImmutableSandboxedEnvironment(trim_blocks=True, lstrip_blocks=True)
jinja_env.globals["raise_exception"] = raise_exception
return jinja_env.from_string(chat_template)
来举个例子看一下其中涉及到的参数:
# GLM-4
conversation = [{'role': 'user', 'content': 'it is me'}]
chat_template = None
# tokenizer初始化的时候就从配置里面拿到的
self.chat_template = "[gMASK]{% for item in messages %}{% if item['tools'] is defined %}<|system|>\n你是一个名为 GLM-4 的人工智能助手。你是基于智谱AI训练的语言模型 GLM-4 模型开发的,你的任务是针对用户的问题和要求提供适当的答复和支持。\n\n# 可用工具{% set tools = item['tools'] %}{% for tool in tools %}{% if tool['type'] == 'function' %}\n\n## {{ tool['function']['name'] }}\n\n{{ tool['function'] | tojson(indent=4) }}\n在调用上述函数时,请使用 Json 格式表示调用的参数。{% elif tool['type'] == 'python' %}\n\n## python\n\n当你向 `python` 发送包含 Python 代码的消息时,该代码将会在一个有状态的 Jupyter notebook 环境中执行。\n`python` 返回代码执行的输出,或在执行 60 秒后返回超时。\n`/mnt/data` 将会持久化存储你的文件。在此会话中,`python` 无法访问互联网。不要使用 `python` 进行任何网络请求或者在线 API 调用,这些在线内容的访问将不会成功。{% elif tool['type'] == 'simple_browser' %}\n\n## simple_browser\n\n你可以使用 `simple_browser` 工具。该工具支持以下函数:\n`search(query: str, recency_days: int)`:使用搜索引擎进行查询并显示结果,可以使用 `recency_days` 参数控制搜索内容的时效性。\n`mclick(ids: list[int])`:获取一系列指定 id 的页面内容。每次调用时,须选择3-10个页面。选择多个角度的页面,同时尽可能选择可信任的信息来源。考虑到部分页面是无法加载的,你也可以多打开一些可能有用的页面而不用担心内容过多。\n`open_url(url: str)`:打开指定的 URL。\n\n使用 `【{引用 id}†{引用文本}】` 来引用内容。\n\n操作步骤:1. 使用 `search` 来获得信息列表; 2. 使用 `mclick` 来获取指定 ID 页面的内容; 3. 根据获得的内容进行回复。在回复中应当引用信息来源。\n 如果用户提供了 URL,也可以用 `open_url` 直接打开页面。\n如果初次搜索结果没有找到合适的信息,也可以再次使用 `search` 进行搜索。{% elif tool['type'] == 'cogview' %}\n\n## cogview\n\n如果用户的请求中包含了对图像的描述,你可以使用 `cogview` 来生成图像并展示给用户。你需要向 `cogview` 发送图像描述,规则:\n- 发送给 `cogview` 的消息必须使用英语。用户的中文描述必须完全翻译为英语。\n- 应当尽可能详细地描述图像生成的需求,需求描述约 100 英文单词。\n- 保持用户原始描述的意图。不要虚构内容或者没见过的人物。\n- 如无特殊说明,所在地为中国,持有中国立场并遵循中国社会主义价值观。{% endif %}{% endfor %}{% endif %}{% if item['content'] %}<|{{ item['role'] }}|>{{ item['metadata'] }}\n{{ item['content'] }}{% endif %}{% endfor %}{% if add_generation_prompt %}<|assistant|>{% endif %}"
# 乱入Qwen2,哈哈哈
conversation = [{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'it is me'}]
chat_template = None
self.chat_template = "{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
left padding
上面已经说过了。只不过这一点很重要,还是单拎出来提一嘴。
prepare_inputs_for_generation() & kv_cache
在transformers/generation/utils.py中,有类class GenerationMixin它的一个方法为prepare_inputs_for_generation(),继承自GenerationMixin的类,必须重写该方法,才能进行后续的token生成。modeling_chatglm.py中的ChatGLMForConditionalGeneration中方法重写如下:
# modeling_chatglm.py
class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
# ...无关代码省略
def prepare_inputs_for_generation(
self,
input_ids: torch.LongTensor,
past_key_values: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
is_first_forward: bool = True,
**kwargs
) -> dict:
# only last token for input_ids if past is not None
if position_ids is None: # 获取位置id
position_ids = self.get_position_ids(input_ids, device=input_ids.device)
if not is_first_forward: # 是否是第一次前向,若非首次前向,输入和位置只取当前位
if past_key_values is not None:
position_ids = position_ids[..., -1:]
input_ids = input_ids[:, -1:]
return {
"input_ids": input_ids,
"past_key_values": past_key_values,
"position_ids": position_ids,
"attention_mask": attention_mask,
"return_last_logit": True,
"use_cache": use_cache
}
首次forward时返回结果(输入为it is me):
{
"input_ids": tensor([[151331, 151333, 151336, 198, 275, 374, 752, 151337]], device='cuda:0'),
"past_key_values": None,
"position_ids": tensor([[0, 1, 2, 3, 4, 5, 6, 7]], device='cuda:0'),
"attention_mask": tensor([[1, 1, 1, 1, 1, 1, 1, 1]], device='cuda:0'),
"return_last_logit": True,
"use_cache": True
}
当生成一个token,第二次forward时返回结果:
{
"input_ids": tensor([[198]], device='cuda:0'), # 新生成的token
"past_key_values": [40 * tuple(2 * torch.Size([1, 2, 8, 128]))],
"position_ids": tensor([[8]], device='cuda:0'),
"attention_mask": tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1]], device='cuda:0'),
"return_last_logit": True,
"use_cache": True
}
这边简单说一下past_key_values,这涉及了kv_cache这个动作。因为逐个token生成的时候,前面的key和value每次都会被重复计算,为了解决这个问题,就出现了kv_cache这种将每一层的key和value都存起来的操作。再来说一下它的形状:配置中设置了一共有40层,要存key和value这两个参数,也就是1+1=2,torch.Size([1, 2, 8, 128])中四个维度分别是(batch_size, group_num, seq_len, dim_per_head),其中group_num是注意力中组的个数。
总结
本篇主要内容包括:跑通demo、理解模型相关文件(尤其是配置文件),以及涉及到transformers库中的一些组件的用法,希望通过本篇能对GLM-4能有一个整体的认知。