c++应用网络编程之八SOCKET探究
一、socket
在目前主流的网络通信中,SOCKET编程其实就是网络编程的代名词。在前面反复提到socket,那么socket到底是什么呢?英文的愿意是“插座、槽”的意思。这里虽然不讲解传统的网络协议但不得不简单说明一下。
首先从宏观上看,一般的网络编程(也就套接字编程),主要分成几大块,即上层的应用程序;其下为OS相关的网络协议栈,它包括应用层(如TELNET,FTP,SMTP等),传输层(TCP,UDP等),网络层(IP)以及数据链路层;网卡驱动以及相关硬件(含固件程序)。
而在协议栈中,教科书中的OSI协议栈其实没有现实意义。实际的网络部署基本全是TCP/IP的协议栈。而在这个协议栈,网络编程实际应用的基本以TCP/IP,UDP为主。即第二层和第三层。应用层一般是提供的命令操作而更下层链路层基本是对网络进行管理时才会用到。上层应用开发很难直接面对这层进行处理。所以在内核中一般会针对上层应用和下层接口提供两套类似的相关数据结构相关定义。协议栈中,网络数据的流动是双向进行的,可以理解成净水器的过滤,只不过这种“过滤”要抽象的来理解,向上传输时是解包,而向下传输时是封包。
那么问题来了,Socket与TCP,UDP,IP是什么关系?为什么Socket编程即套接字编程可以代表网络编程?
一个个来回答,首先要实现一个通信,最基础的是要有通信的协议,也就是如何通信来保障双方可以理解和支持。就和人们讲话一样,讲一个知识点前先要把其中的一些名词术语解释清楚,这样才能更好的沟通。再如兑换不同的国家的货币,也需要一个锚定的货币来进行(一般是美元)。有了这个协议,就需要有一个东西做其与OS以及上层应用程序的接口定义或者说一个代言人,而这个代言人就是Socket。
理解到这一点上,重点就来了。首先要继续理解,socket本身是一个文件句柄或者说一个节点或者说一个ID,不管怎么理解,先把这一点记清楚。然后,它并是一个简单的fd,它代表一个套接字的接口,所以从宏观角度看,它可以是一个三元组,四元组或者五元组。以五元组为例,它是本地的IP地址和端口,远端的IO和端口以及协议类型。这个几元组才是重点中的关键,因为它就是socket接口代表的真正的东西,即实际在OS及协议栈中的通信的相关接口和数据结构的显示的声明。虽然开发者无法看到具体的内容,但实际上就是通过这些,实现了对底层的网络通信的指定和控制。
二、socket通信的基本流程
现在以服务端为例子,解释一下Socket通信的原理。其基本的流程图如下:
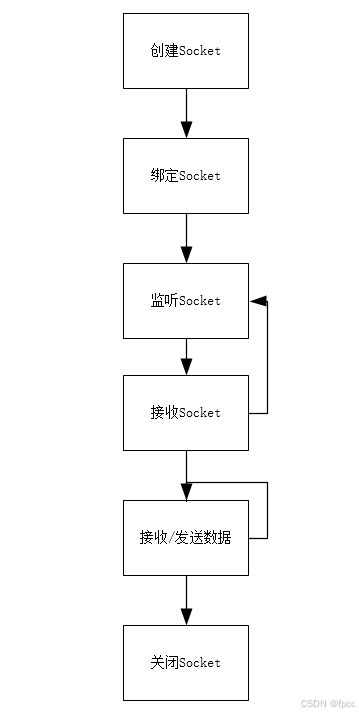
在套接字的编程过程中,相对客户端网络编程,服务端编程是非常复杂的。但它可以基本抽象出上面的流程:
1、创建Socket fd,提供套接字编程的文件句柄
2、通过bind()函数绑定到相关资源上,重点是端口值
3、开始在这个Socket上进行监听,并处理监听到的客户端连接Socket(这就是listen后跟的长度的值,当然不同的OS可能有所不同)
4、通过accept()函数等待客户端的连接请求,并在有连接请求时不断处理其生成一个新连接Socket fd
5、通过上面新生成的socket fd,开始进行接收和发送数据的操作(根据情况可以循环处理)
6、结束后,结束相关网络操作并回收socket资源
而对客户端来说,如果不考虑各种异常情况就非常简单了:
1、创建socket fd
2、利用connect()函数连接服务端地址
3、利用连接成功的socket fd发送接收数据
4、结束相关操作并清理回收资源
UDP通信与之类似,不过少了一些相关的步骤而已,请大家自行查阅相关资料。
三、原理
在分析过socket是个什么东西后,又明白了其通信的流程,那么在上面提到的socket是接口,是数据结构,是对上对下的一个代理是怎么得来的呢?下面看一下在内核中对其的处理,就明白了。
先看一下内核中socket的文件系统的定义:
struct inode {
umode_t i_mode;
unsigned short i_opflags;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
......
#ifdef CONFIG_FSNOTIFY
__u32 i_fsnotify_mask; /* all events this inode cares about */
struct fsnotify_mark_connector __rcu *i_fsnotify_marks;
#endif
#ifdef CONFIG_FS_ENCRYPTION
struct fscrypt_info *i_crypt_info;
#endif
#ifdef CONFIG_FS_VERITY
struct fsverity_info *i_verity_info;
#endif
void *i_private; /* fs or device private pointer */
} __randomize_layout;
struct socket {
socket_state state;
short type;
unsigned long flags;
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
struct socket_wq wq;
};
struct sock {
/*
* Now struct inet_timewait_sock also uses sock_common, so please just
* don't add nothing before this first member (__sk_common) --acme
*/
struct sock_common __sk_common;
#define sk_node __sk_common.skc_node
#define sk_nulls_node __sk_common.skc_nulls_node
#define sk_refcnt __sk_common.skc_refcnt
#define sk_tx_queue_mapping __sk_common.skc_tx_queue_mapping
#ifdef CONFIG_SOCK_RX_QUEUE_MAPPING
#define sk_rx_queue_mapping __sk_common.skc_rx_queue_mapping
#endif
#define sk_dontcopy_begin __sk_common.skc_dontcopy_begin
#define sk_dontcopy_end __sk_common.skc_dontcopy_end
#define sk_hash __sk_common.skc_hash
......
void (*sk_state_change)(struct sock *sk);
void (*sk_data_ready)(struct sock *sk);
void (*sk_write_space)(struct sock *sk);
void (*sk_error_report)(struct sock *sk);
int (*sk_backlog_rcv)(struct sock *sk,
struct sk_buff *skb);
#ifdef CONFIG_SOCK_VALIDATE_XMIT
struct sk_buff* (*sk_validate_xmit_skb)(struct sock *sk,
struct net_device *dev,
struct sk_buff *skb);
#endif
void (*sk_destruct)(struct sock *sk);
struct sock_reuseport __rcu *sk_reuseport_cb;
#ifdef CONFIG_BPF_SYSCALL
struct bpf_local_storage __rcu *sk_bpf_storage;
#endif
struct rcu_head sk_rcu;
netns_tracker ns_tracker;
}
static const struct super_operations sockfs_ops = {
.alloc_inode = sock_alloc_inode,
.free_inode = sock_free_inode,
.statfs = simple_statfs,
};
struct socket_alloc {
struct socket socket;
struct inode vfs_inode;
};
注意上面的socket结构体和sock结构体,就是前文提到的针对不同的层实现的两类socket的描述,这和现实世界中对一个人在不同的场景的称呼有所不同的意义有些类似,一定要注意认识清楚。
socket fd其实就是内核中的sockfs,是vfs(Virtual File System,虚拟文件系统)中的一类,它位于vfs之下。不过需要说明的是,在vfs中,基础的数据定义就是indoe数据结构。在不同的文件类中,indoe会根据实际情况进行相关类型的转换或者数据处理。比如常见的ext4,就需要进行地址的转换。而socket亦是如此,它可以理解成是在inode上层进行的一个封装或者一个抽象或者一个转换,看怎么理解更容易就怎么理解。
这也是为什么socket同样可以使用接口read,write进行操作的原因。写得比较多的开发者可能就用过这两个函数。
Linux中文件系统使用的是索引节点(innode)的数据结构来管理文件的相关元数据。而其元数据本身的组织也是常见的B+树树。使用树的优点很多,特别是对于文件这种本身就是一个级联的形势的场景下更有优势。
再看一下其创建Socket相关代码:
static int __init sock_init(void)
{
int err;
/*
* Initialize the network sysctl infrastructure.
*/
err = net_sysctl_init();
if (err)
goto out;
/*
* Initialize skbuff SLAB cache
*/
skb_init();
/*
* Initialize the protocols module.
*/
init_inodecache();
err = register_filesystem(&sock_fs_type);
if (err)
goto out;
sock_mnt = kern_mount(&sock_fs_type);
if (IS_ERR(sock_mnt)) {
err = PTR_ERR(sock_mnt);
goto out_mount;
}
/* The real protocol initialization is performed in later initcalls.
*/
#ifdef CONFIG_NETFILTER
err = netfilter_init();
if (err)
goto out;
#endif
ptp_classifier_init();
out:
return err;
out_mount:
unregister_filesystem(&sock_fs_type);
goto out;
}
static struct inode *sock_alloc_inode(struct super_block *sb)
{
struct socket_alloc *ei;
ei = alloc_inode_sb(sb, sock_inode_cachep, GFP_KERNEL);
if (!ei)
return NULL;
init_waitqueue_head(&ei->socket.wq.wait);
ei->socket.wq.fasync_list = NULL;
ei->socket.wq.flags = 0;
ei->socket.state = SS_UNCONNECTED;
ei->socket.flags = 0;
ei->socket.ops = NULL;
ei->socket.sk = NULL;
ei->socket.file = NULL;
return &ei->vfs_inode;
}
再看一些常见的上层应用用到的接口函数的实现:
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args)
{
unsigned long a[AUDITSC_ARGS];
unsigned long a0, a1;
int err;
unsigned int len;
if (call < 1 || call > SYS_SENDMMSG)
return -EINVAL;
call = array_index_nospec(call, SYS_SENDMMSG + 1);
len = nargs[call];
if (len > sizeof(a))
return -EINVAL;
/* copy_from_user should be SMP safe. */
if (copy_from_user(a, args, len))
return -EFAULT;
err = audit_socketcall(nargs[call] / sizeof(unsigned long), a);
if (err)
return err;
a0 = a[0];
a1 = a[1];
switch (call) {
case SYS_SOCKET:
err = __sys_socket(a0, a1, a[2]);
break;
case SYS_BIND:
err = __sys_bind(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_CONNECT:
err = __sys_connect(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_LISTEN:
err = __sys_listen(a0, a1);
break;
case SYS_ACCEPT:
err = __sys_accept4(a0, (struct sockaddr __user *)a1,
(int __user *)a[2], 0);
break;
case SYS_GETSOCKNAME:
err =
__sys_getsockname(a0, (struct sockaddr __user *)a1,
(int __user *)a[2]);
break;
case SYS_GETPEERNAME:
err =
__sys_getpeername(a0, (struct sockaddr __user *)a1,
(int __user *)a[2]);
break;
case SYS_SOCKETPAIR:
err = __sys_socketpair(a0, a1, a[2], (int __user *)a[3]);
break;
case SYS_SEND:
err = __sys_sendto(a0, (void __user *)a1, a[2], a[3],
NULL, 0);
break;
case SYS_SENDTO:
err = __sys_sendto(a0, (void __user *)a1, a[2], a[3],
(struct sockaddr __user *)a[4], a[5]);
break;
case SYS_RECV:
err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3],
NULL, NULL);
break;
case SYS_RECVFROM:
err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3],
(struct sockaddr __user *)a[4],
(int __user *)a[5]);
break;
case SYS_SHUTDOWN:
err = __sys_shutdown(a0, a1);
break;
case SYS_SETSOCKOPT:
err = __sys_setsockopt(a0, a1, a[2], (char __user *)a[3],
a[4]);
break;
case SYS_GETSOCKOPT:
err =
__sys_getsockopt(a0, a1, a[2], (char __user *)a[3],
(int __user *)a[4]);
break;
case SYS_SENDMSG:
err = __sys_sendmsg(a0, (struct user_msghdr __user *)a1,
a[2], true);
break;
case SYS_SENDMMSG:
err = __sys_sendmmsg(a0, (struct mmsghdr __user *)a1, a[2],
a[3], true);
break;
case SYS_RECVMSG:
err = __sys_recvmsg(a0, (struct user_msghdr __user *)a1,
a[2], true);
break;
case SYS_RECVMMSG:
if (IS_ENABLED(CONFIG_64BIT))
err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1,
a[2], a[3],
(struct __kernel_timespec __user *)a[4],
NULL);
else
err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1,
a[2], a[3], NULL,
(struct old_timespec32 __user *)a[4]);
break;
case SYS_ACCEPT4:
err = __sys_accept4(a0, (struct sockaddr __user *)a1,
(int __user *)a[2], a[3]);
break;
default:
err = -EINVAL;
break;
}
return err;
}
int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen)
{
int ret = -EBADF;
struct fd f;
f = fdget(fd);
if (f.file) {
struct sockaddr_storage address;
ret = move_addr_to_kernel(uservaddr, addrlen, &address);
if (!ret)
ret = __sys_connect_file(f.file, &address, addrlen, 0);
fdput(f);
}
return ret;
}
这些代码都来自于Linux5.19中,有兴趣可以自己跟进去看一看,可能不同的平台实现略有不同,需要大家注意。
进行过网络通信开发的实践的开发者知道,Socket从创建到监听到接收等有着一系列的返回情况,它们之间有着细节的不同。一般来说,Socket可以大概分成两类,即监听套按字和普通套按字。所谓监听套接字是指listen和Accept函数,它们只负责连接的管理而不进行数据的处理,更直白一些说,它只得到socket而不会做其它的事情。而普通套接字则比较全面,它也是开发者常说的网络IO,即通过对它的操作可以传输和得到数据。
这里还需要澄清一个问题,socket所谓的读写,一般并不是指直接从网卡读写数据,而是对缓冲区数据的读写。同样,缓冲区也分成多层,有程序的,有驱动的,有网卡的等等。这个在DPDK系列中也进行过分析。有兴起的可以看看相关的资料。
另外,为了完成指定的目标,这些套接字都注册了相关的句柄事件。说到这儿,可能大家就非常清楚了,在编写Select,Epoll等模型时,事件的处理的来历了。也明白了,为什么叫事件驱动模型。比如常见的如监听类型的Socket会触发接收和连接等。而Send和Recv等会触发读写事件等等。当然还有其它如悬挂或异常等都需要有专门的处理事件,这都需要开发者在实际开发中进行全面的管理,否则极容易出现异常导致整个程序的Crash。
套接字socket的分类,监听,普通,接收
四、总结
我们分析完成了一般网络通信的原理和相关的IO通信的机制,已经基本明白了网络通信到底是怎么一回事,以及其相关的难点和重点。国内的教科书往往有一个重要的问题,就是从来不连贯的讲述一个知识点,而是将这些知识点打乱并且乱序讲解。这样做很难让一个人把网络通信的相关知识融会贯通。换句话说,基本上靠自觉把相关的体系建立起来的可能性极小。这也是本系列一开篇并没有像传统的书本把网络基础知识大讲一通,然后再搞几个IO模型举几个例子,基本上这书就过去了。
当然,网上也有一些优秀的书籍和资料,但又非常倾向于使用实际例子来解释说明,让一些初学者感到压力很大。希望现在这个系列能给一些初级和中级的开发者一些从理论高度把握网络通信整体的情况再深入到例程中学习实践的思路。
一花开放不是春,百花齐放春来到。与诸君共勉!